С увеличением масштабов проекта СЭД DIRECTUM растет количество объектов, за состоянием которых нужно следить, и, как следствие, растет количество логируемой информации. В инфраструктуре крупного проекта нередко можно наблюдать примерно такую картину:
- пара десятков серверов, на каждом по 1-3 службы или приложения;
- пара десятков терминальных серверов, которые обслуживают тысячи тонких клиентов;
- несколько сотен толстых клиентов.
Все эти объекты генерируют огромное количество логов, расположенных в разных местах, и со временем становится непонятно, что со всем этим делать.
Задачи
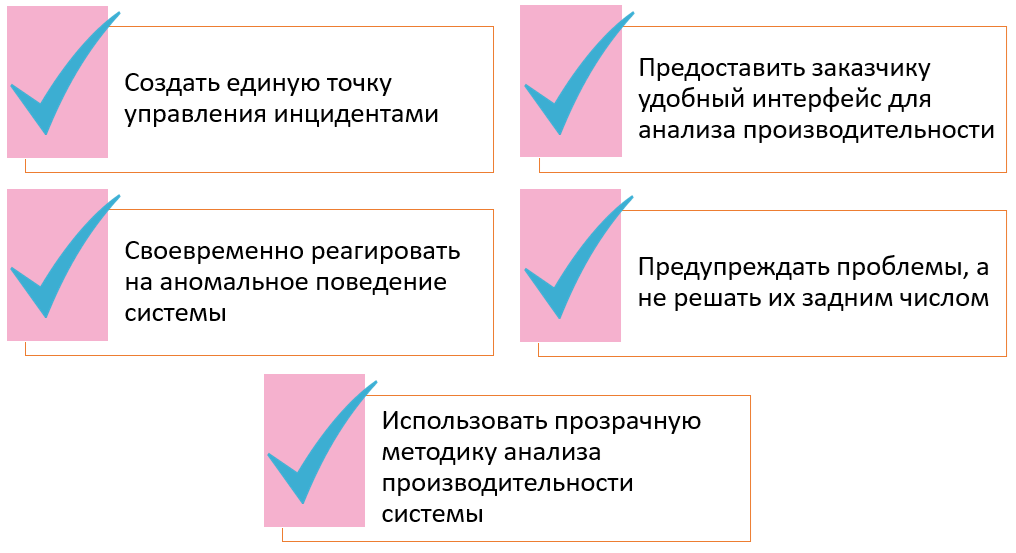
При сопровождении СЭД DIRECTUM анализу подлежат следующие виды логов:
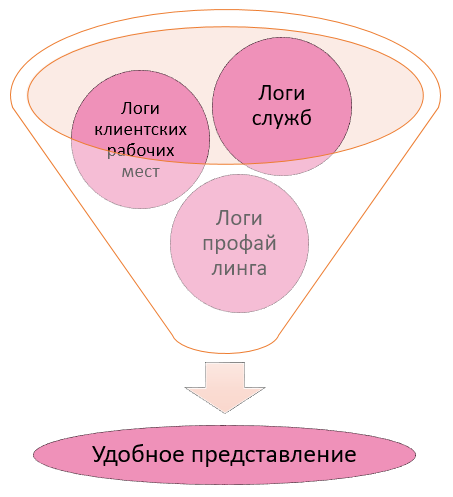
Прежде чем внедрять решение по мониторингу производительности системы DIRECTUM, следует навести порядок в текущей инфраструктуре лог-файлов. В рамках подготовки системы DIRECTUM к внедрению подсистемы мониторинга производительности были произведены следующие настройки:
- во время очередного обновления системы DIRECTUM до новой версии файлы LogSettings.xml всех клиентских рабочих мест были настроены на единую сетевую папку;
- настроено копирование лог-файлов с терминальных серверов в единую сетевую папку;
- настроена ротация лог-файлов служб и клиентских рабочих мест, в том числе на терминальных серверах;
- включен профайлинг стандартными средствами системы DIRECTUM;
- настроена ротация лог-файлов профайлинга.
Что ж, пожалуй, теперь система готова к настройке мониторинга производительности. Итак, начнем.
Описание решения
Для начала небольшой глоссарий
Чтобы не было недопонимания в терминологии, определимся с неоднозначными понятиями.
ELK Stack – по первым буквам Elasticsearch, Logstash и Kibana.
Виджет – отдельный элемент, визуально представляющий некоторый набор логов, полученный по определенному запросу.
Дэшборд – произвольный набор виджетов на одном экране в браузере.
Индекс – в Elasticsearch это аналог таблицы БД.
Логи профайлинга – логи профайлинга, которые записываются стандартными средствами DIRECTUM. Настройка записи этих логов производится в справочнике Настройки профайлинга.
Использованные технологии и платформы
После исследования нескольких open source и платных решений (ELK Stack, Graylog, TICK Stack, Prometheus + Grafana), было решено использовать open source продукт ELK Stack в такой конфигурации:
ElasticSearch – мощный инструмент для хранения и поиска больших объемов информации. Внутри себя использует движок Lucene.
LogStash – умный транспорт для доставки лог-файлов в ElasticSearch. Быстро обрабатывает переданные ему логи, преобразовывает их по заданным правилам и передает в ElasticSearch.
FileBeat – «легкий» собиратель логов. Устанавливается на удаленные машины, собирает логи и передает их в Logstash.
Kibana – удобный интерфейс для компоновки и визуализации данных.
Компоненты используют движок JVM, так называемую виртуальную машину Java. На первый взгляд, LogStash и FileBeat делают одно и то же: транспортируют логи, но разница все же есть – FileBeat существенно легче, его можно установить на конечные производители логов, и он не будет потреблять много ресурсов.
Установить ELK Stack можно как на ОС Windows, так и на Linux, причем на Linux с теми же показателями системы он будет себя чувствовать просторнее за счет того, что меньше ресурсов используется для поддержания работоспособности самой ОС. У нас же все было настроено на Windows Server 2012 с 64 гигабайтами оперативной памяти.
Возможности решения
Вот некоторые полезные «что можно мониторить» в СЭД:
- частота появления определенного события;
- временные ряды по событиям;
- пользователи с наибольшим количеством ошибок;
- длительность выполнения операций на клиентских рабочих местах;
- количество занятых и свободных клиентских лицензий.
А вот некоторые полезные «что можно мониторить» за пределами СЭД:
- журналы Windows;
- посещаемость и активность на сайтах;
- сетевой трафик;
- визуализировать гео-данные.
И немного о «невозможностях» open source решения:
- нет возможности отправки сообщений по событию;
- нет возможности настроить аутентификацию для доступа к интерфейсу Kibana.
Эти возможности есть в платной версии продукта, а именно: в расширении X-Pack.
Суть работы и порядок использования
Немного пошаманив с настройками, мы загрузили в ElasticSearch логи клиентских рабочих мест DIRECTUM, логи служб, а также логи профайлинга. Для каждой группы логов были настроены дэшборды для удобства визуального анализа информации, представленной в логах. Настройка визуализации логов профайлинга показала, что действительно информативные блоки выглядят так себе, поэтому было решено добавить на дэшборд красивых картинок для привлечения внимания (количество входов в систему за период времени, количество обращений к документам, количество обращений к справочникам, топ активных пользователей, топ наиболее длительных операций и т.д.).
Интересные технические находки и особенности
В процессе настройки ELK Stack были выявлены следующие особенности:
- ELK Stack достаточно «прожорлив» в отношении ресурсов, но скорость его работы существенно компенсирует эту особенность.
- ElacticSearch хранит данные в индексах. Как оно внутри устроено, остается загадкой, но работает он с этими индексами действительно быстро.
- ELK Stack предпочитает работать с «плотными» данными, т.е., загружая в него несколько разных видов логов, нужно постараться называть поля одинаково.
- По умолчанию индексы создаются по датам, т.е. один индекс включает в себя события одного дня из всех лог-файлов. Сделано это для того, чтобы было удобнее удалять старые индексы или строить запросы к индексу по конкретной дате. Но индексам также можно давать произвольные названия. Например, складывать клиентские логи, логи служб и логи профайлинга в разные индексы по дням, по неделям или по месяцам. Тогда будет удобнее настраивать визуализацию, и, как уже упоминалось ранее, ElasticSearch будет доволен, т.к. данные в таких индексах будут «плотными».
Тут уместно написать про объемы генерируемой информации. Данные приведены для одновременно используемых 1700-1800 лицензий.
- Размер ежедневного индекса с клиентскими логами в нормальном режиме работы 25-30 Мб;
- Объем ежедневных логов профайлинга на жестком диске на сервере 3,5 Гб;
- Размер ежедневного индекса с логами профайлинга 500 Мб. Разница в объемах логов профайлинга существенна из-за того, что события фильтруются на этапе прохождения через Logstash.
А теперь немного о доработке продукта «напильником»:
- Красивые графики — это, конечно, хорошо, но хочется получать информацию об ошибках своевременно, а не тогда, когда дошли руки посмотреть на дэшборд. Ограничения по отправке уведомлений по событию можно обойти, если строить запросы к эластику внешними скриптами на powershell и в случае превышения каких-либо показателей отправлять e-mail ответственным администраторам.
- Разграничить доступ к интерфейсу Kibana можно через поднятие веб-сервера IIS с настройкой аутентификации.
Другой способ обойти эти два ограничения – дополнительно поднять еще одно open source решение Prometheus+Grafana, у которого присутствуют эти функции в коробке.
Примеры пользовательского интерфейса
ELK Stack не только умный, но и красивый. Компонента Kibana предоставляет доступ к визуальному представлению всей хранимой в ElasticSearch информации. Данные можно компоновать произвольным образом и выводить в виде графиков, диаграмм, таблиц и т.д. Набор типов виджетов достаточно разнообразный.
На нескольких следующих скриншотам мы постарались воспроизвести минимально необходимый набор виджетов для слежения за состоянием системы DIRECTUM.
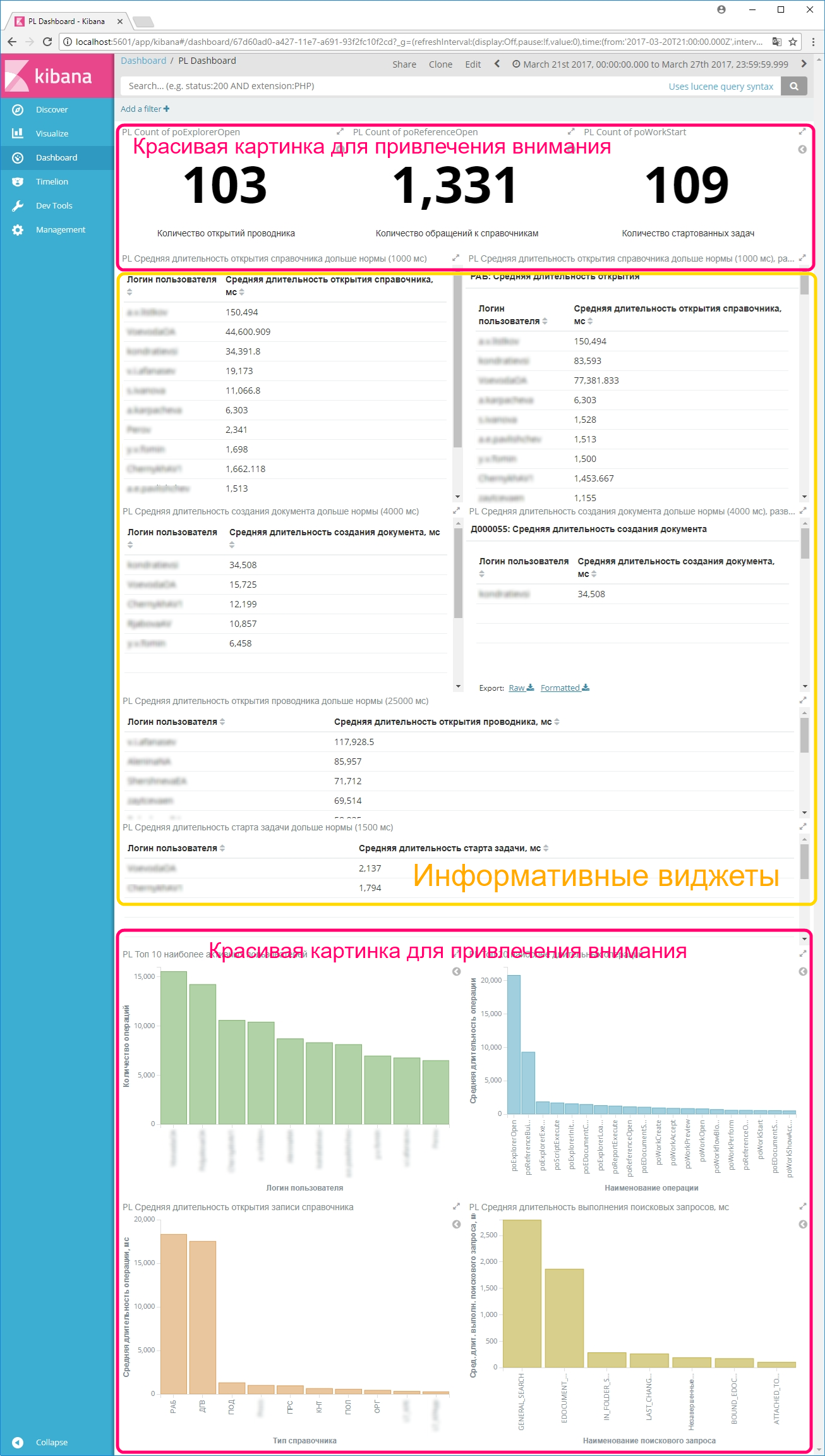
На первом скриншоте продемонстрирован дэшборд по визуализации логов профайлинга. Информативная часть виджетов, выделенная на скриншоте желтым цветом, выглядит достаточно сухо. Поэтому сверху и снизу были добавлены красивые картинки для привлечения внимания, как уже упоминалось ранее.
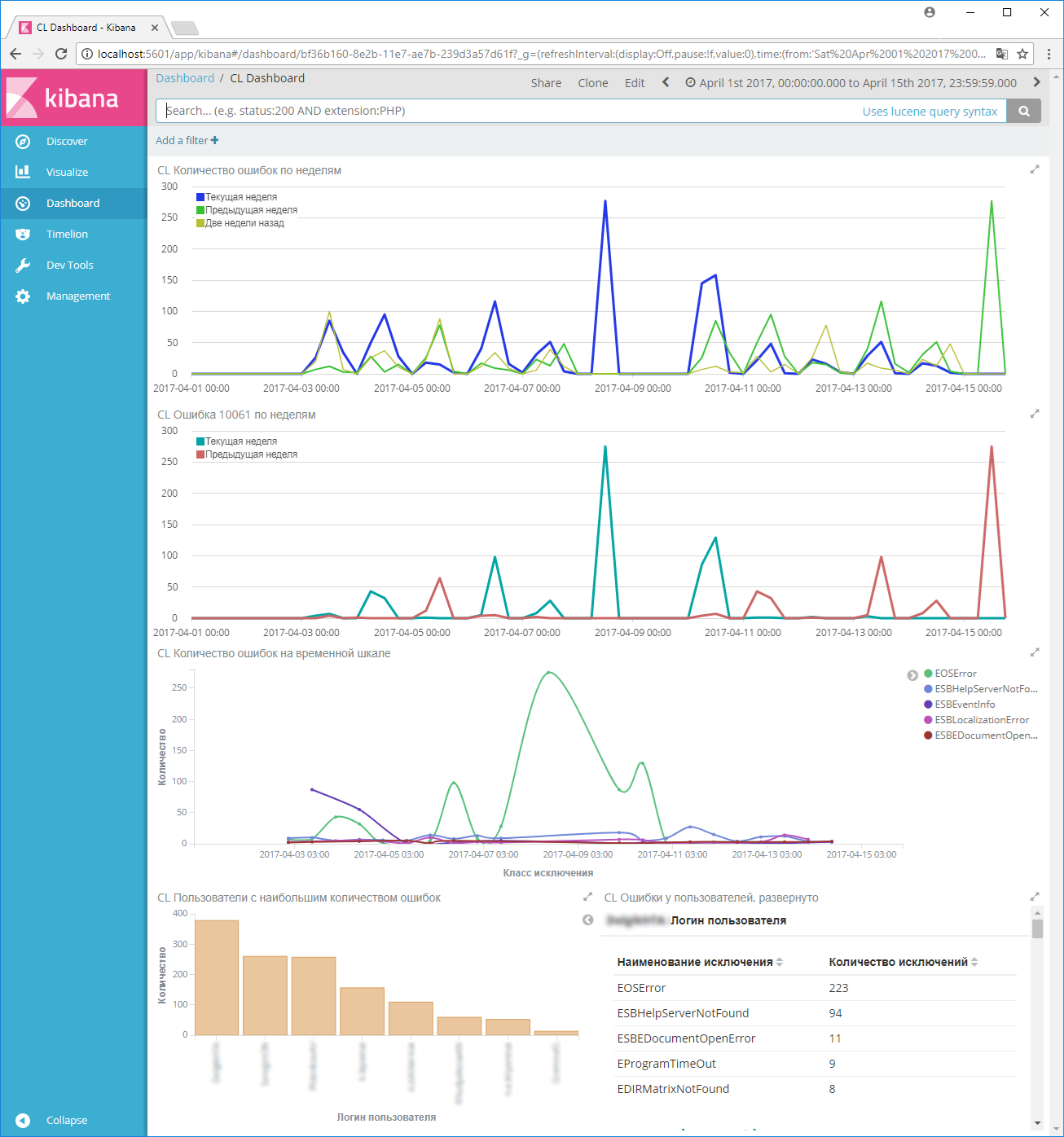
 Второй скриншот демонстрирует аналитику по клиентским логам: временные ряды, сравнивающие количество ошибок за равнозначные периоды времени (текущая неделя, предыдущая неделя и две недели назад), наиболее часто встречающиеся ошибки, а также пользователи с наибольшим количеством ошибок:
Второй скриншот демонстрирует аналитику по клиентским логам: временные ряды, сравнивающие количество ошибок за равнозначные периоды времени (текущая неделя, предыдущая неделя и две недели назад), наиболее часто встречающиеся ошибки, а также пользователи с наибольшим количеством ошибок:
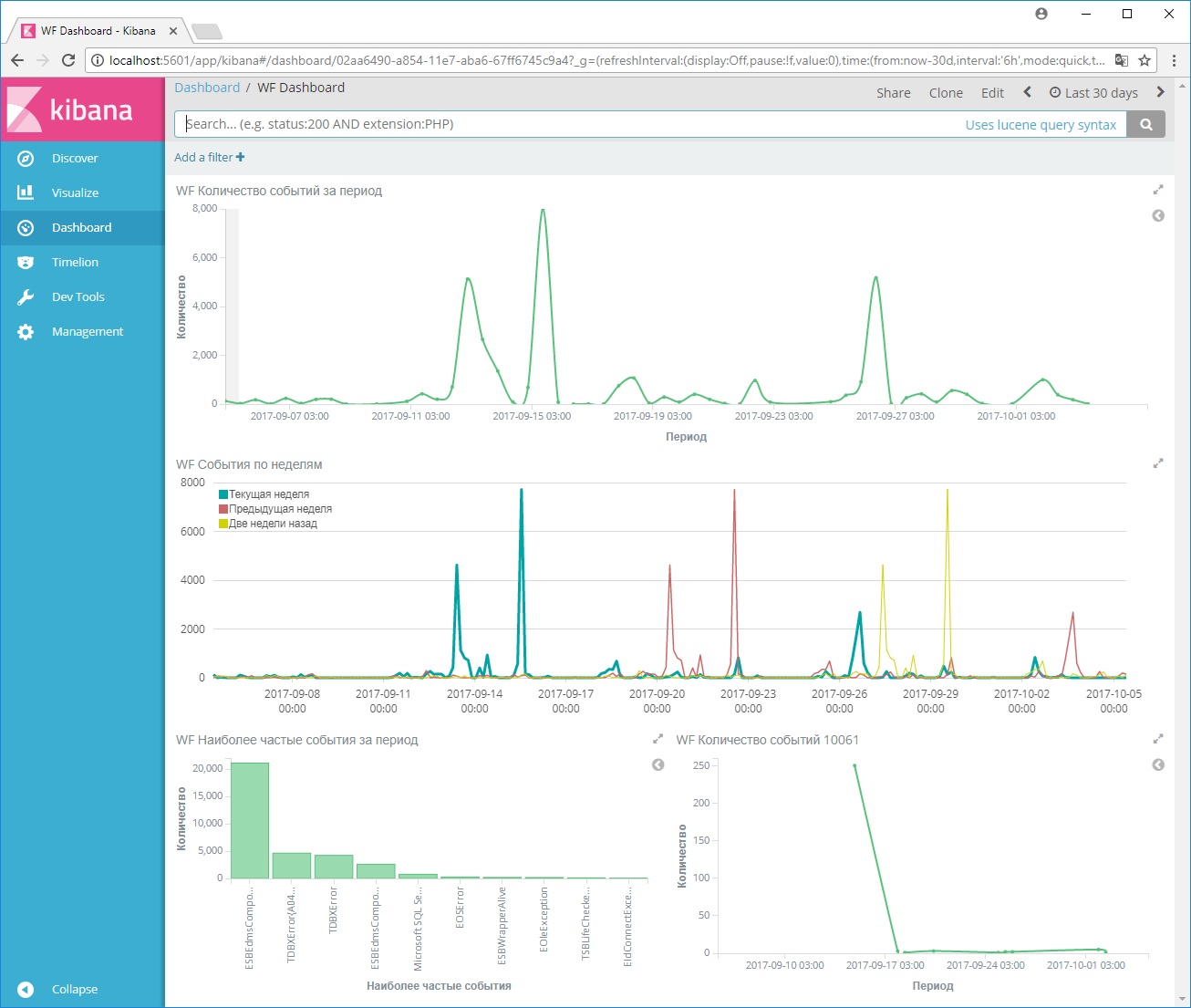
На третьем скриншоте показаны данные по событиям в логах службы Workflow: общее количество событий за период, временные ряды за последние три недели, а также наиболее частые события за период:
В отдельный индекс были загружены логи службы сервера сеансов из файла, настроенного в параметре ClientConnectionLog в файле SBSessionSrvSettings.xml. Так появился четвертый скриншот. Он дает понимание, сколько максимально используется лицензий за период и сколько еще есть свободных, прежде, чем пользователям будет отказано в доступе по причине нехватки лицензии.
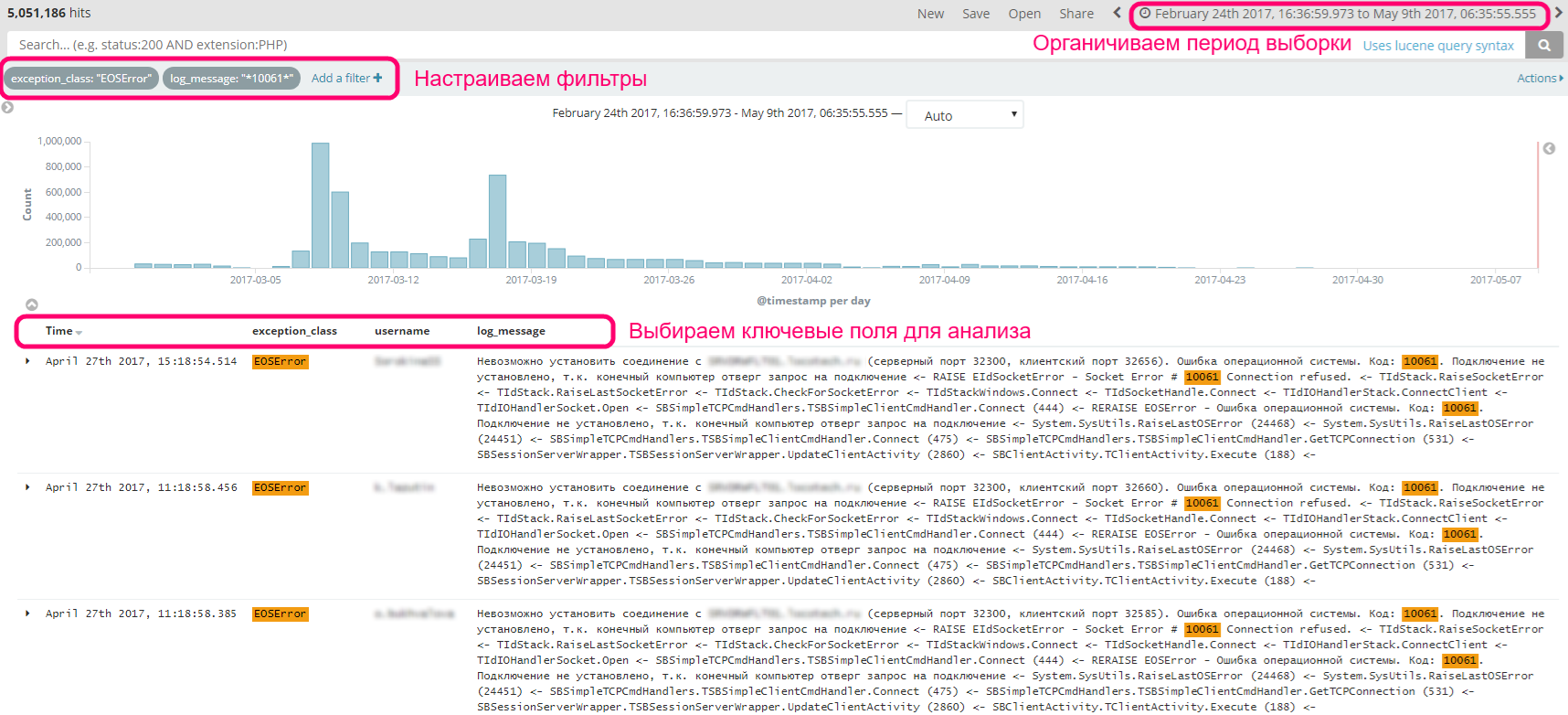
 Как показала практика, информации на этих дэшбордах достаточно для того, чтобы выявить отклонения в работе системы. Дальнейший анализ следует проводить по отфильтрованному списку событий. Это выглядит примерно так:
Как показала практика, информации на этих дэшбордах достаточно для того, чтобы выявить отклонения в работе системы. Дальнейший анализ следует проводить по отфильтрованному списку событий. Это выглядит примерно так:
Результаты применения решения
Бонусы от применения решения оказались существенными уже на этапе тестирования.
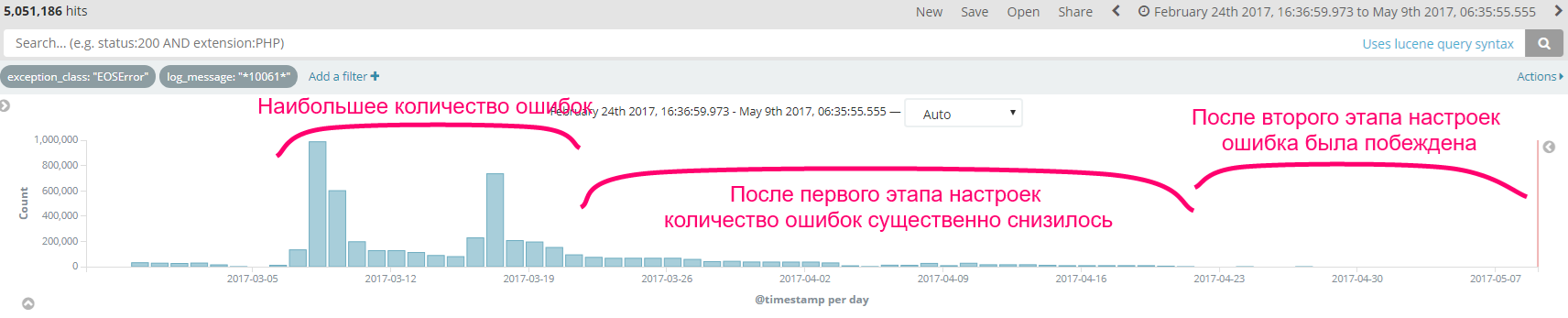
Бонус №1. С ростом масштабов использования DIRECTUM на крупном предприятии стала существенно расти нагрузка на серверы, вследствие чего стали появляться необычные ошибки, например, ошибка EOSError с номером 10061, которая «подвешивала» систему DIRECTUM у пользователей минуты на полторы и вызывала много вопросов как со стороны рядовых пользователей, так и со стороны руководства заказчика. Система мониторинга помогла проанализировать частоту появления ошибки, принять меры по ее устранению, а также продемонстрировать заказчику эффективность принятых мер:
Бонус №2. В процессе тестовой настройки были использованы реальные логи клиентских рабочих мест. При анализе этих данных в Kibana в топе ошибок оказалась ошибка ESBHelpServerNotFound, нам стало стыдно, и мы наконец-таки подняли у заказчика сервер веб-справки.
Бонус №3. Была проанализирована скорость выполнения операций, и в отношении наиболее длительных операций были приняты соответствующие меры:
- оптимизированы запросы при открытии набора данных некоторых справочников;
- параметризованы многократные SQL-запросы;
- оптимизирован код при создании записей справочников.
А также были выявлены пользователи с большим количеством задач в папках Входящие, Исходящие, и выданы рекомендации по очистке этих папок.
Перспективы развития решения
Планы на будущее:
- настроить мониторинг работоспособности служб;
- настроить мониторинг счетчиков производительности SQL-сервера;
- реализовать уведомления ответственным администраторам о критичных ошибках/событиях;
- в связи с планируемым внедрением мобильного доступа Solo/Jazz появилась необходимость также следить за здоровьем сервера Nomad.
И самое главное – продвигать культуру проактивного мониторинга СЭД в процессе внедрения проектов, разворачивать ELK Stack уже в рамках проекта и обучать ответственных технических специалистов заказчика нехитрым премудростям мониторинга.
Впечатления
После проведенных исследований и проделанной работы, были сделаны следующие выводы:
- Анализировать логи может быть не только скучно, но и увлекательно.
- Разбираться с настройкой продукта легко и приятно, несмотря на некоторые «трудности перевода». На официальном сайте предоставлена действительно полная документация по настройке, к тому же написанная очень красочным языком. Низкий поклон их маркетологам.
- Возможности продукта для наших целей оказались более чем достаточными, даже немного с избытком.
- Если правильно пошаманить, то можно восполнить ограничения open source решения в плане отправки уведомлений по событию, а также по разграничению доступа к веб-интерфейсу мониторинга.
Всем хороших показателей на дэшбордах. Спасибо за внимание!
Номинация:
Решение разработчика
У вас похожая задача?
Обсудите реализацию с экспертом Directum

Хотите внедрить
похожее решение?
Оставьте заявку, и мы свяжемся с вами — определим ваши интересы и подготовим индивидуальную презентацию под ваши задачи.
Получить презентацию
Ну, наконец-то, разработчики начали реально думать о пользователях и удобстве их работы !!!
Да, интересное решение - начальник отдела ИТ как без рук без этого инструментария.
Юлия, поздравляем вас! Вы в числе активных и получивших признание от сообщества, ваша заявка набрала более 15 лайков, а значит вы получаете приз. В ближайшее время с вами свяжутся, чтобы уточнить детали, как получить приз.
Отличное решение!
У нас в свою очередь используется Grafana + Influxdb.
Но нотификации и счётчики по Windows/SQL Server осуществляются через SCOM.
Также в этой связке для снятия метрик SQL Server отлично подходит influxdata/telegraf. Вот такая красота sql server.
Роман, а Influxdb умеет агрегировать логи так же как Elastic? Хранить, делать поиск по ним? Рассматривали так же его на этапе выбора решения, но Influxdb позиционируется как Time Series Database. И примеров реализации агрегации логов на нем не видели.
А мы анализ логов в нём не производим пока что. Мы использовали для снятия метрик: кол-во пользователей в базе (через выгрузку SASessionSrvInfo.exe), оттуда же заблокированные элементы по типам, кол-во задач в Workflow на различных серверах (была проблема в 5.0 с кэшированными справочниками cfg и гонка процессов за доступ к ним), состояние служб - работает/не работает, кол-во пакетов DICS в обработке (но тут потом отдельная разработка появилась), и др.
В принципе связка очень удобная для визуализации любых метрик, опять же отправить запрос в базу можно из любого объекта системы где есть разработка через обычный post запрос.
До массового анализа логов руки так и не дошли. Но как-то даже смотрели Clickhouse для этого дела.
Удобство Графаны в том, что она работает с любыми источниками данных, причём одновременно. Первоначально вообще использовался Graphite, но не с Директумом.
Авторизуйтесь, чтобы написать комментарий