Решение по журналированию произвольных событий в Directum.
Суть проблемы
Нужно регистрировать те или иные события при работе в системе Directum, чтобы потом их анализировать, например:
- запуск сценариев и результаты их выполнения,
- прохождение задач,
- следить за тем, кто какие изменения внёс в карточки записей справочников и электронных документов,
- фиксировать исключения, происходящие в прикладной разработке,
- другие события, потребность в которых возникает у разработчиков и администраторов.
Существующие решения
- ведение лог-файлов (в файловой системе),
- ведение журнала в таблице базы данных SQL.
Недостатки и преимущества существующих решений
Лог-файлы преимущества: простота, наличие стандартных функций записи в файл. Так все делают.
Лог-файлы недостатки: не удобно просматривать при большом объеме, не удобно анализировать. Требуется настройка сетевых каталогов и прав доступа к ним. Файлы ограничены по размерам.
Таблица базы данных SQL преимущества: высокое быстродействие, удобно анализировать.
Таблица базы данных SQL недостатки: схема таблицы должна быть заранее определена, что ведёт к существенному усложнению разработки и сопровождения существующих прикладных решений.
Исходя из этого, я предлагаю пилотное решение, которое обладает преимуществами вышеперечисленных вариантов и избавлено (как мне кажется) от их недостатков.
Суть решения
Допустим, нам нужно фиксировать изменения значений реквизитов некоторого справочника. На событии Сохранение после мы вставляем функцию (пилотное название функции Directumlog()), в которую передаём объект (в нашем случае это запись справочника, но может быть и электронный документ и список IList и строка в определенном формате), название события (произвольное, помогает в последующем найти это событие в коллекции), имя коллекции (произвольное, содержит все события относящиеся к одной группе событий). Функция собирает значение всех реквизитов, и отправляет их в базу данных с помощью POST запроса. На сервере (HTTP-сервер) данные сохраняются в NoSQL базу данных (подробнее о NoSQL можно почитать тут). Такая база данных не требует наличия заранее определенной схемы данных, в отличии от SQL, что позволяет передавать самые разные данные. На следующем рисунке представлена общая схема взаимодействия (см. Рис. 1).

Рис. 1 Общая схема взаимодействия компонент
Далее нам нужно только прочитать данные из базы данных NoSQL, что не представляется сложной задачей. В частности, для баз данных под управлением MongoDB (подробнее о MongoDB можно почитать тут), можно использовать бесплатный инструмент Robomongo (официальный сайт), который обладает удобным графическим интерфейсом и позволяет найти всё что нам нужно в базе данных. Давайте посмотрим на это более детально.
Реализация на примере
Рассмотрим пример, в котором мы будет отслеживать изменения реквизитов некоторого справочника TestReference. Для этого добавим функцию Directumlog() в справочник TestReference на событии сохранение после (Рис. 2). В параметры передадим: текущий объект Object (текущая запись справочника), тип события (сохранение возможность), имя коллекции в которой будут храниться записи (TestReferenceEvents). Имя коллекции задаётся произвольно и если такой коллекции нет, она будет создана автоматически, вам не придется об этом думать.
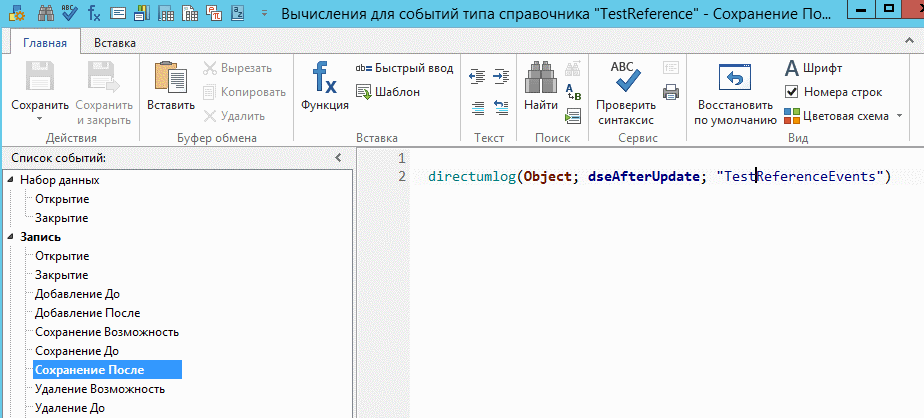
Рис. 2 Вставить функцию на событии
Заполним запись справочника TestReference и сохраним (Рис. 3)
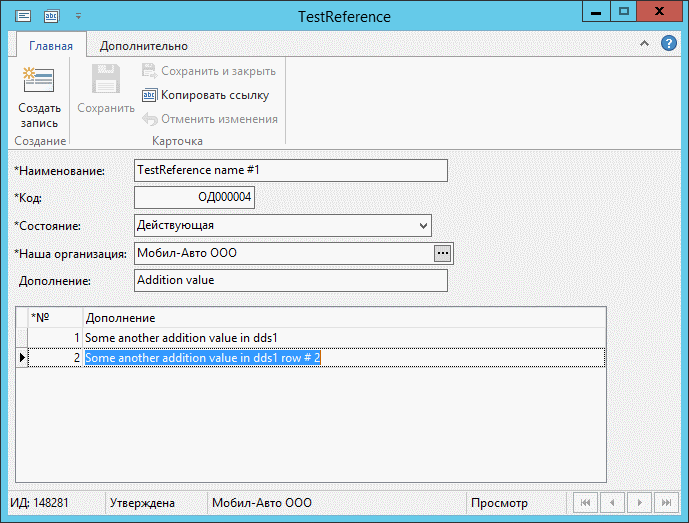
Рис. 3 Заполненная карточка
В результате в базе данных появилась новая коллекция TestReferenceEvents с нашими данными.
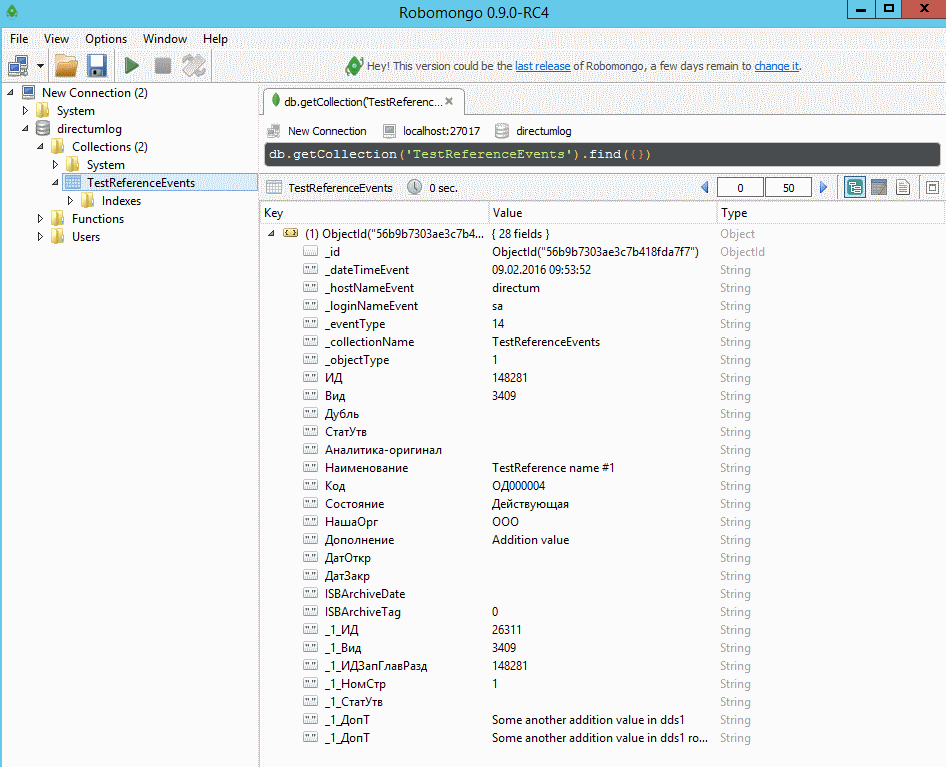
Рис. 4 Результат в программе Robomongo (в режиме объектов)
Если бы мы использовали SQL таблицу, то нам пришлось бы заранее определить структуру данных для нашего события, и так для каждого нового нового типа события. В случае с данным решением, нам требуется только указать название новой коллекции, в которой мы будем хранить наши события и все.
Кроме того, представьте ситуацию, что мы решили добавить (или удалить) некоторые реквизиты справочника, в этом случае возникает необходимость доработать таблицу SQL для приёма данных в новом формате. Что делать с данным, которые уже содержаться в таблице? Это головная боль. В случае с моим решением, мы запросто можем записать данные с разным составом полей в одну и ту-же таблицу (коллекцию) и при этом анализировать эти данные. Удобно, быстро, просто.
Реализация на еще одном примере
Теперь давайте рассмотрим еще один пример, в котором нам нужно фиксировать события старта и завершения сценария SomeCoolScript. Сценарий служит для того, чтобы замерить быстродействие функции Directumlog(). Рассмотрим текст сценария:
// Получим текущее время
started = SQL("SELECT CURRENT_TIMESTAMP")
// Выполним функцию directumlog, которая создаст событие started в коллекции SomeCoolScriptEvent
directumlog(""; 'started'; 'SomeCoolScriptEvent')
// Получим текущее время и посчитаем сколько времени прошло с момента запуска функции directumlog
timeSpendInSeconds = SQL(Format("SELECT DATEDIFF(millisecond, '%s', (SELECT CURRENT_TIMESTAMP))"; ArrayOf(started)))
// Создадим список реквизитов для нового события
logData = CreateList()
// Добавим результат вычисления времени в список реквизитов
logData.Add("Затрачено времени"; timeSpendInSeconds)
// Выполним функцию directumlog, которая создаст событие finish в коллекции SomeCoolScriptEvent с доп. реквизитом "Затрачено времени".
directumlog(logData; 'finish'; 'SomeCoolScriptEvent')
Функция Directumlog() фиксирует событие старта сценария в коллекции SomeCoolScriptEvent с событием started. Замеряем производительности выполнения функции и фиксируем еще одно событие с помощью функции Directumlog(). Фиксируем в ту-же коллекцию SomeCoolScriptEvent но с событием finish. Посмотрим что получилось в итоге базе событий (Рис. 5)
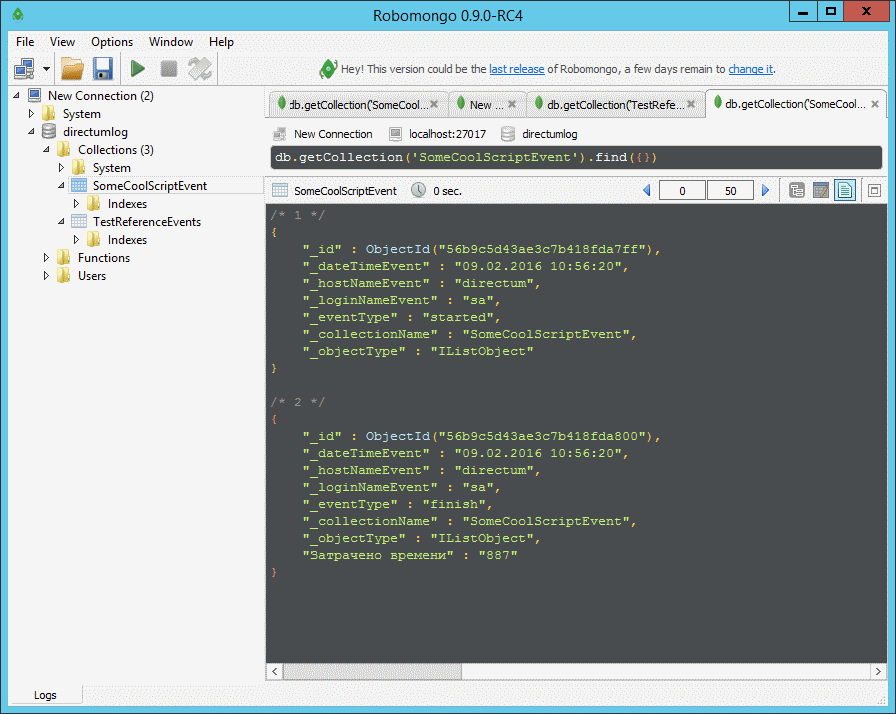
Рис. 5 Результат выполнения сценария SomeCoolScript (представлено в текстовом режиме)
Как мы можем увидеть на рис. 5 во втором событии есть поле "Затрачено времени" и рядом значение этого поля: 887 миллисекунд. На этот раз мы видим результат в текстовом виде, однако можно просмотреть результаты и в табличной форме и в форме объектов (как на рис. 4). Запустим этот сценарий 10000 раз, и вычислим среднее значение времени выполнения функции Directumlog(). Получилось в среднем 400 миллисекунд. Вопрос быстродействия является ключевым для данного решения, поэтому я работаю над тем чтобы его увеличить, и уже сейчас можно сказать, что можно увеличить его в 2-3 раза.
Итог
Итого, решение позволяет создавать произвольные события, не заботясь ни о чём другом, кроме добавления одной единственной функции в нужные события прикладной разработки. Все эти данные сохраняться в базе данных. Вам не нужно думать о том, что переполняться файлы, что структура ваших данных изменилась и нужно менять таблицы SQL, ни о том, как найти нужные события.
Преимущества решения Directumlog: простота использования (одна единственная функции для регистрации всех событий), неограниченный объем данных (ограничено объемом накопителей), достаточно высокое быстродействие, возможность удобного просмотра событий и построения отчётов, не ведет к усложнению разработки и сопровождения существующих прикладных решений.
Дополнительные преимущества решения Directumlog: большие возможности для расширения функционала (представьте возможность рассылки писем в на электронную почту в случае некоторых событий, выгрузку отчётов), нет привязки к платформе (решение можно разместить как на Windows, так и на других современных операционных системах, например Linux или Mac OS), возможность балансировки нагрузки и распределенной работы HTTP-сервера (позволяет разместить решение на нескольких серверах и распределить нагрузку на них, что повысит быстродействие и отказоустойчивость).
Недостатки решения Directumlog: нужно установить дополнительное ПО, нужно освоить инструмент поиска событий в базе NoSQL, нет опыта использования (так еще не делали на больших проектах на сколько мне известно).
Как начать пользоваться уже сейчас?
По запросу я могу предоставить виртуальную машину, которую вы можете скачать и использовать. На виртуальной машине открыт один HTTP порт и один порт для доступа к данным базы данных. Можно скачать, развернуть и использовать.
Комментарии и обсуждение приветствуется.
Источники вдохновения
Как определить, какие реквизиты записи справочника были изменены с определенного момента времени.
Протоколирование сценариев собственной разработки
Cрез самых топовых проблем, которые мешают жить прикладному разработчику
А как потом анализировать такой лог, если я заранее не знаю его структуру?
А вот тут нам и приходит на помощь язык запросов NoSQL (в моём случае это MongoDB), т.к. для каждого события есть стандартные реквизиты, которые заносятся в базу данных: Дата и время события, пользователь, рабочая станция, тип события. Эти данные дают уже очень много для того, чтобы анализировать информацию. Для иллюстрации, обратите внимание на Рис. 5, на нём мы видим события отработки сценария SomeCoolScript, в строке запроса (чуть выше результатов) можно увидеть строку db.getCollection('SomeCoolScriptEvent').find({}), которая и выбирает все данные из коллекции (таблицы). Если мы к примеру задумали найти все события с типом finish, то мы напишем db.getCollection('SomeCoolScriptEvent').find({"_eventType": "finish"}). Язык запросов достаточно гибкий, для того, чтобы найти любую интересующую информацию. Подробнее о языке можно почитать в справке по MongoDB (в моём случае). Еще момент, изначально MongoDB предлагает нам взаимодействовать через console (terminal) операционной системы, что не всегда удобно, поэтому есть прекрасный свободный продукт Robomongo.
Спасибо за уточняющие вопросы, Алексей! Буду рад ответить на все
Данные в вашем сервисе могут быть скомпрометированы. Конечно, это может быть не критично в большинстве ситуаций, но помнить об этом стоит.
Злоумышленник может посылать на веб сервис запросы и передавать произвольные данные, события, имя пользователя...
Помогла бы в этом случае общая аутентификация с MSSQL сервером, но как такое сделать, не ясно...
Абсолютно справедливое замечание! Вопрос аутентификации стоит на данный момент в приоритете задач. Первым делом предполагется добавить возможность использования HTTPS в дополнение к HTTP, далее добавить возможность basic authentication (по логину и паролю), далее сделать Windows Authentication. Предполагаю что данное решение поможет решить большинство вопросов связанных с передачей "злоумышленных" данных.
Интересное решение! Такая потребность периодически возникает в том или ином виде.
Узким местом может быть встраивание данного механизма отправки в события объектов, с которыми напрямую работает пользователь. Например в события справочника сохранение до/после + они выполняются в рамках транзакции. Следовательно как ни крути, а будет какая-то дополнительная задержка.
Поясню подробнее.
1. Это может напрямую выходить на пользователей - увеличится время сохранения. Где-то может быть и не заметно, а где то время сохранения уже на грани и добавления еще одного звена - превысит допустимые значения.
2. Появляется еще одно звено в виде HTTP-сервера. Это повышает время блокировки данных для других пользователей, т.к. транзакция сохранения длится дольше. По всей видимости, чем больше данных будет передаваться в лог, тем дольше она будет длиться. Особенно если есть реквизиты типа Text.
3. Система логирования должна быть надежной. Иначе теряется ее смысл, если какие то действия не фиксируется, что то может потеряться и т.п.. Как следствие - при отправке запроса - нужно получить какой-то ответ, что все действительно сохранилось. Это увеличивает время обмена еще больше. Плюс, если с коннектом до HTTP-сервера возникают какие-то проблемы, то все может вообще подвиснуть.
Если все эти вопросы решить, и попутно еще вопросы с безопасностью, как отметил Михаил - вполне может получиться конфетка.
Благодарю, Андрей!
Действительно, время сохранения увеличится, но увеличиться оно на выполнение одного SQL запроса к базе Directum который соберёт все данные необходимые для отправки, на формирование и отправку HTTP запроса. По моим наблюдениям, это не превышает 1 секунды.
Я еще не проверял работу с большими данными типа Text. Как только проверю скорость работы, обязательно выложу результаты.
Верно! Надёжность должна быть высокой. Я только начинаю анализировать возможные события отказа, чтобы их предупредить. В любом случае, уверен, что данные вопросы получиться разрешить.
Т.к. я использую асинхронную отправку и обработку запросов, то подвисать нечему. Этот момент я предусмотрел прежде всего.
Сначала конфетка, а потом и производство кондитерской продукции!
Это так. Но чтобы найти в логе информацию, нужно знать, что она там есть. И выходит (тут мы переходим на уровень логической структуры), что лог должен содержать не только собственно данные, но и информацию о том, что это за данные — метаданные. И на вашем скрине это тоже видно. В целом не вижу принципиальных препятствий для организации подобного логирования на SQL. Надо только понимать, что это означает накладные расходы (к NoSQL это тоже относится) — за гибкость логирования придется заплатить цену в виде большего размера логов и снижения скорости работы с ними, что не всегда приемлемо.
Я не уверен, что правильно Вас понимаю, Алексей.
Это относится ко всем логам. Ведь если я открываю файл TestReferenceLog.txt, я ожидаю увидеть там информацию и читаю её. Если я делаю запрос к таблице TestReferenceLogTable, то я тоже ожидаю от этой таблицы определённого формата данных? По крайней мере мне нужно знать состав реквизитов справочника TestReference. В случае NoSQL, мы тоже ожидаем увидеть информацию в коллекции TestReferenceEvents.
Конечно, каждое сообщение, содержит обязательные поля: дата и время события, имя пользователя, имя рабочей станции, тип события. Этого достаточно, чтобы найти любое событие и посмотреть данные которые были переданы. При этом нам не нужно думать о том, что при изменении состава реквизитов справочника, нам нужно будет изменять таблицу базы SQL для того, чтобы новые поля тоже сохранялись в логе. В этом вся суть.
Принципиальных препятствий использования действительно нет, есть даже выгоды от этого варианта, о которых я говорил, однако те преимущества решения, которые я описал в статье, могут перевесить. Лично я считаю что каждый из способов имеет место быть в тех или иных ситуациях. Но когда требуется иметь централизованный, удобный в использовании, масштабируемый и простой в сопровождении продукт, то я бы сделал выбор в сторону этого решения.
Верно. При использовании SQL будут большие накладные расходы. NoSQL как будто создана для того, чтобы хранить в себе лог файлы (неструктурированную или слабо структурированную информацию), тогда как SQL очень хорош для того, чтобы обрабатывать структуры данных.
Это немало. Заказчиками часто предъявляются довольно жесткие требования ко времени сохранения карточек, и в него порой едва удается впихнуть бизнес-логику, от которой не откажешься. А тут еще логирование, польза от которого для заказчика не столь очевидна. Угадайте, что пойдет "под нож" в первую очередь?
Разве что в качестве научного эксперимента по проверке живучести лог-сервера Потому что сливать значения реквизитов
типа Text в логи — самоубийство чистой воды. Или нет?
Потому что сливать значения реквизитов
типа Text в логи — самоубийство чистой воды. Или нет?
Самые ненужные функции . На самом деле у меня уже есть решение, которое позволяет затрачивать на событие отправки сообщения
не более 100 миллисекунд. Но оно еще находится в стадии тестирования и я не знаю на сколько это нужно. Раз Вы говорите, что это нужно, то продолжу разработку и в этом направлении.
. На самом деле у меня уже есть решение, которое позволяет затрачивать на событие отправки сообщения
не более 100 миллисекунд. Но оно еще находится в стадии тестирования и я не знаю на сколько это нужно. Раз Вы говорите, что это нужно, то продолжу разработку и в этом направлении.
Согласен, пока не могу себе представить ситуацию, в которой нужно было бы журналировать поля типа Text. Но в любом случае, как возможность это я бы хотел предусмотреть.
Да, и среднее время выполнения 400 миллисекунд. 1 секудна это максимальное время, которое я зафиксировал. Минимальное составило 59 миллисекунд.
Еще одно ограничение предложенного решения - потребность встраивать функцию в события объектов. Так мы не сможем получить информацию о действиях, на которые событий нет: работа с папками, добавление/удаление ссылки, изменения констант, выполнения действий из различных мест (например, через кнопку или контекстное меню) и т.д.
Это действительно важный момент. На данном этапе решение может журналировать только события, к которым у прикладных разработчиков есть доступ. Т.к. у прикладных разработчиков нет возможности обращаться к событиям, которые вы описали выше, то такие события и не журналируются. Хотя было очень хорошо иметь доступ и к этим событиям.
Важно отметить, что этот момент я успел в некоторой степени изучить. Пока конкретных решений у меня нет, но я планирую использовать триггеры MS SQL для доступа к таким событиям. Т.к. это трудозатратно в реализации, хотелось бы убедиться, что это действительно нужный функционал. Прошу высказываться по этому поводу, на сколько это нужно?
А давайте, я объяснюсь иначе. Когда я читаю лог (файл или таблицу — неважно) фиксированной структуры, я не трачу время на выяснение того, что именно у меня записано в полях — я знаю это априори. Если же фиксированной структуры нет, то мне необходимо для каждого необязательного поля каждой записи выяснять, что это за информация. А для этого я должен хранить в каждой записи лога метаданные, что при прочих равных увеличит а) размер каждой записи; б) скорость ее обработки.
Например, на рис. 5 восьмое поле второй записи содержит информацию о затраченном времени. В третьей записи там может лежать курс йены (поменяется и имя поля, естественно), а в первой записи восьмого поля вообще нет. И с этим придется разбираться "на лету" при анализе лога. То есть анализировать не только данные, но и саму структуру каждой записи лога.
Это я и называю накладными расходами, и не понимаю, как от этого избавляет NoSQL. Он позволяет на лету менять структуру лога — да, но ценой его размера и производительности.
Вот теперь я Вас понял!
Когда мы формируем сообщение на клиенте Directum, мы определяем следующие очень важные моменты:
1. Состав реквизитов, которые нужно передать (если это запись справочника, то передаются имена реквизитов и их значения, если это объект типа IList, то передаются соответственно имена и значения элементов IList)
2. Тип события (в примере на рис. 5 типов событий всего два: started и finish)
3. Имя коллекции, в которую событие попадёт (в последнем примере это SomeCoolScriptEvent)
Таким образом, мы определяем структуру которая поможет нам не намешать всё в кучу, а разбить все события на: коллекции и типы событий. Таким образом мы можем точно сказать что в коллекции SomeCoolScriptEvent содержатся события относящиеся к выполнению скрипта SomeCoolScript. Что в этой коллекции содержатся события, тип которых started или finish (так как мы сами изначально типы событий которые фиксируем). При этом состав реквизитов, которые мы передаём может отличаться. Мы можем ожидать, что в типе события finish будет содержаться поле "Затрачено времени", тогда как в событии типа started этого поля не будет. Если мы захотим найти все записи в коллекции, которые содержат поле "Затрачено времени", то мы напишем db.getCollection('SomeCoolScriptEvent').find({"Затрачено времени": {$exists: true}}) и увидим только те записи, в которых есть это поле.
Таким образом, мы заранее определяем в какой коллекции мы хотим чтобы сохранялись события, какие типы событий мы будем регистрировать (определяем это в параметрах функции Directumlog() а не на стороне базы данных, там все сохраниться автоматически в указанную нами коллекцию). Нам не нужны метаданные, чтобы выяснить что это за информация, т.к. мы заранее знаем что и куда мы сохраняем.
Т.е. структуру хранимых событий мы определяем в функции Directumlog("Данные в формате Name=Value"; "Имя события произвольно"; "Имя коллекции произвольно"). Например, вызвав функцию Directumlog("Name=Pavel"; "Добавление записи"; "ПОЛ_СОБЫТИЯ" ), мы автоматически (не делая ничего дополнительно) получим запись в базе данных в коллекцию ПОЛ_СОБЫТИЯ (даже если её еще не существует, она создается), с типом "Добавление записи", и с реквизитами (стандартными и переданными Name).
По моему это очень удобно и не вызывает никаких накладных расходов вообще, нет избыточности данных, работает всё очень быстро. Я ведь правильно понял вопрос?
Я помню минимум 2 раза, когда заказчик хотел историю по добавлению/удалению ссылок из папок, например, при разборе ситуации, когда пользователь не выполнил свое задание в срок и говорит, что оно ему не приходило. Тут важно знать, оно действительно не пришло или пользователь сам удалил ссылку на него из входящих? Еще может быть настроено правило, которое удаляет ссылки.
Протоколирование действий пользователь необходимо при анализе "типовых" сценариев работы, например, как пользователь отправляет договор на согласование: через мастер, через кнопку в карточке или вложением в задачу через контекстное меню. Анализ "типовых" сценариев работы позволяет улучшать систему в соответствии с предпочтениями пользователей.
Павел, правильно ли я вас понимаю: по сути это — хранение фактически независимых логов (по типам событий) в одном файле, причем в рамках каждого типа событий состав полей неизменен? Просто изначально в материале был приведен пример с изменением состава реквизитов справочника и возможностью вывода нового состава данных в уже существующие логи. Это разные задачи.
Не совсем так. В рамках каждого события имеется стандартный состав полей (пользователь, дата время и т.п.) и состав полей, который определяется на стороне клиента прикладным разработчиком. Т.е. разработчик определяет состав полей который он хочет зафиксировать в событии.
По сути, решение не запрещает ему хранить всё в одной коллекции, не запрещает называть все события одним и тем-же именем и при этом передавать самые разные данные. Но в этом случае, данные действительно невозможно будет анализировать. Поэтому нужно заранее определиться с тем какие события в каких коллекциях будут содержаться и какие события мы в этих коллекциях регистрируем. То, как будет организовано хранение событий, по сути определяет прикладной разработчик Directum.
В примерах, которые я привел выше создано две коллекции: в одной я храню события справочника TestReference, в другой я храню события сценария SomeCoolScript. Причем, в случае со сценарием, состав передаваемых полей разный (в зависимости от типа события). Этим я хотел показать, что можно хранить разные типы событий с разным составом полей в одной коллекции, относящейся к одной коллекции событий. И то, что этих коллекций может быть столько, сколько необходимо. И что эти коллекции создаются автоматически (в отличии от таблиц SQL).
Юлия, этот вопрос в рамках текущего решения решить не получится, но я обязательно подумаю над возможностью реализации.
Что касается протоколирования действий, у меня есть ощущение, что текущее решение вполне может с этим справиться. И на мастере действий и на кнопке в карточке и на типовом маршруте есть события, на которые можно добавить функцию журналирования. Если у Вас есть реальный бизнес-кейс я с удовольствием сделаю презентационное решение, как этом можно реализовать
Павел, уточните пожалуйста, в логе хранится информация о факте внесения изменений или также хранится первоначальное и текущее значение реквизита?
Решение позволяет:
Т.е. можно заносить ту информацию, которую вы считаете нужной и в том формате, в котором вам это удобно. Я считаю, что второй вариант предпочтительнее, т.к. по логу будет видно на какие данные были изменены реквизиты в каждом из событий.
Наталья, Павел, слежение за изменениями реквизитов обсуждалось вот тут: Журналирование действий. Можно посмотреть, чтобы понимать, какие требования предъявляются к такому инструменту. Павел, судя по всему, уже в курсе
На самом деле эта идея и вдохновила на создание решения. Я просмотрел все материалы форума, идей, вопросов и ответов. Те материалы, которые особенно мне помогли в формировании идеи я привёл в качестве ссылок в конце статьи.
Спасибо, Алексей, обязательно посмотрю, инструмент очень полезный, особенно при "разборе полетов" по замечаниям пользователей.
Спасибо, Натальня! При "разборе полётов" действительно это решение будет очень полезным. Мы всегда сможем отследить изменения значений реквизитов карточек электронных документов и справочников (в том числе в детальных разделах), чего нельзя сделать в стандартной поставке Directum. Кроме того, я уже получил очень много конструктивной обратной связи от коллег и у меня появились новые идеи, как можно сделать это решение более быстрым, надёжным и удобным в использовании.
Возможно меня не совсем верно поняли. При анализе "типовых" сценариев работы необходимо знать не ЧТО запускает пользователь, а КАК он это делает. Приведу пример - запуск задачи по типовому маршруту:
1) через проводник через кнопку "Создать задачу", в задаче выбирает типовой маршрут
2) через проводник через кнопку "Создать задачу по типовому маршруту"
3) Через контекстное меню записи справочника "Отправить" и далее тоже 2 варианта "Задачей" или "Задачей по типовому маршруту"
4) Те же действия, но через горячие клавиши
И таких примеров очень много, событий естественно тоже нет
Юлия, теперь ясно. Действительно, Directum пока не предоставляет возможностей для реализации описанных Вами задач. Надеюсь меня поправят, если я не прав. Это хорошая возможность, чтобы оформить идею. Как только её одобрят, можно будет за неё голосовать.
Павел, решение просто отличное!
Многим разработчикам и администраторам необходимо знать, что происходило с объектами в системе, а использование стандартных логов действительно не всегда удобно в использовании. Здесь же вся информация собирается в одном информационном поле: и об удаленных объектах, ссылках и об изменениях и добавлениях.
Сейчас чтобы узнать информацию об удаленных объектах кто-то использует сценарий, описанный в статье http://club.directum.ru/post/Prikladnojj-scenarijj-171Poisk-udalennykh-obektov-sistemy187.aspx . Используются другие методы для анализа изменения "жизни" объекта в системе. Все это занимает время на поиск информации и на ее анализ. Так что ждем выхода решения в эксплуатацию!
И конечно, я в очереди на тестирование!
Алена, спасибо большое! Очень приятно.
Да, мы можем собирать информацию об удалении объектов, если поместим на событие удаления этих объектов (записей справочников и документов) функцию directumlog(). А вот информацию о ссылках на данный момент получить сложно, т.к. платформа не предоставляет прикладным разработчикам возможность обработать эти события. Но я думаю, что в новых версиях моего решения и это будет возможно.
Согласен. Конечно и в моем решении нужно будет потратить некоторое время на поиск информации. И на данном этапе развития этого решения поиск по силам скорее ИТ специалистам, чем бизнес-пользователям. На этот счёт я получил очень ценную обратную связь о том, что нужно будет добавить удобный механизм просмотра данных для бизнес-пользователей, для руководства. Например, отправлять эти данные электронной почтой и/или предоставить возможность просмотреть информацию в виде опубликованной веб-страницы.
Спасибо большое! Буду очень рад показать решение и отдать в эксплуатацию.
Опишу наш опыт логгирования событий. Мы поступили примерно так же, но чутка проще.
Создали справочник "Трассировка". В нем колонки: "Дата", "Группа", "Компонента", "Наименование" и текстовый реквизит "Сообщение".
Создали функцию "__trace(msg; group='default')"
В функцию передаем текстовое сообщение и если требуется, то имя группы сообщений (просто текст для группировки)
Функция добавляет в справочник запись. В записи присутствует дата её создания, имя группы. В реквизите "Компонента" прописываются данные из компоненты, вызвавшей функцию. Например, если функцию вызвали из сценария, то прописывается что - то вроде: "Script | __ContractReportPart |", если из событий документа, то: "EDocument | ДГД | 5631778", где указывается тип карточки и ИД документа, если из событий справочника, то вида: "Reference | __Рац_предложение | 5366798". Так же для задач, заданий... В реквизит "Сообщение" и в "Наименование" записывается информация из параметра msg, непосредственно текст сообщения.
В версии 5.2.1 с появлением функционала раскраски, стали подсвечивать красным записи, в которых встречается часть слова "ошиб" для того, что бы сообщения об ошибках бросались в глаза.
С помощью фильтров можно ограничивать выборку по колонкам. Так, можно ограничить по компоненте (по конкретному сценарию, например), по группе, искать по слову или фразе в сообщении, ограничить по дате события и т.д.
Среди недостатков решения то, что при работе с транзакциями (IConnection.RollbackTransaction) при откате транзакции, запись в справочник не сохраняется.
Авторизуйтесь, чтобы написать комментарий