5 рекомендаций для повышения производительности в DIRECTUM 5
Иногда наши клиенты сталкиваются с ситуацией медленной работы системы DIRECTUM. В некоторых случаях низкая производительность наблюдается только у части пользователей, в других – подобное влияние испытывает на себе большинство.
Решение подобных кейсов, как правило, начинается с выполнения диагностики общего состояния системы (если вы ещё не знаете, что это, то на этот счёт есть ряд статей: Какой диагноз у вашей системы?, Диагностика системы DIRECTUM: из мухи сделали слона, Диагностика общего состояния системы DIRECTUM: 8 часто задаваемых вопросов), по результатам которой часто выдаются типовые рекомендаций, благодаря которым можно снизить нагрузку на базу данных и на клиентскую часть.
В данной статье рассмотрим эти рекомендации, и ряд рекомендаций для администратора SQL-сервера, направленных на повышение производительности системы.
1. Ссылки в предопределённых папках
Одной из самых распространённых причин, которая приводит к длительному запуску проводника DIRECTUM и долгому обновлению содержимого папок, является большое количество ссылок в предопределённых папках Входящие и Исходящие.
Дело в том, что при обновлении содержимого этих папок (а оно происходит в том числе и при запуске проводника) осуществляется серия запросов к базе данных. Чем больше ссылок находится в папках, тем дольше будет обрабатываться этот запрос базой данных и тем дольше клиентская часть на компьютере пользователя будет получать результаты этого запроса и обрабатывать их.
Таким образом, простое уменьшение количества ссылок в предопределённых папках у пользователей может увеличить скорость запуска проводника, снизить нагрузку на базу данных и сеть. Рекомендуемое значение – не более 100 ссылок на обе папки.
Полезно будет знать и о параметре FolderCacheUpdatePeriod в установках системы. Он позволяет управлять временем, через которое обновляется локальный кэш папок. При открытии папки её содержимое будет подгружаться из локального кэша и не будет нагружать базу данных. Запросы к базе данных будут выполняться только в том случае если содержимое папки изменялось или с момента предыдущего чтения содержимого папки с сервера прошло больше времени, чем задано в установке FolderCacheUpdatePeriod.
Таким образом, в системах с большим количеством пользователей полезно установить значение этого параметра побольше (например, 720), чтобы уменьшить ненужную нагрузку от обновления содержимого редко используемых папок. Интервал обновления кэша задаётся в часах. Значение 0 соответствует отключенному кэшированию, поэтому стоит его избегать.
2. Фильтр по периоду
Вторая частая причина, «благодаря» которой у пользователя долго открываются справочники и также создаётся лишняя нагрузка на базу данных – отсутствие фильтров по периоду.
Фильтр по периоду – это механизм, который позволяет выгружать с сервера и отображать пользователю только те записи, которые были созданы в заданный период. Это позволяет не только снизить нагрузку на базу данных, но и быстрее получить доступ к необходимой информации. Ведь в большинстве случаев нужен доступ к «оперативным» данным, а не записям двухлетней давности и логичнее для этого получить, скажем, 200 записей, а не 10000.
Данные об установленном для каждого пользователя фильтре по периоду хранятся в таблице XIni. Для удобства массового проставления был написан isbl-сценарий (во вложении к статье), который позволяет выбрать необходимые даты, установить только начальный или только конечный периоды сразу для всех пользователей системы:
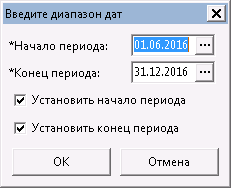
Помимо описанных выше способов, есть другие, постоянные направления, которые уже полностью ложатся на плечи администратора SQL-сервера: актуализация и оптимизация состава индексов, их реорганизация, обновление планов запросов и триггеров.
3. Состав индексов
С течением времени изменяется профиль работы пользователей, работающих с системой, их количество, могут изменяться бизнес-процессы. Всё это изменяет и профиль нагрузки на SQL-сервер.
В связи с этим, для обеспечения эффективной работы необходимо регулярно осуществлять актуализацию состава индексов: создавать новые необходимые индексы, модифицировать существующие, удалять или отключать не использующиеся, т.к. они могут создавать повышенную нагрузку на дисковую систему при изменении данных в часто используемых таблицах. Это, в свою очередь, ведёт к снижению производительности сервера SQL.
Как можно определить какие индексы нужны, а какие нет? Сервер SQL ведёт статистику по частоте использования существующих индексов, а также, на основе статистики запросов, формирует рекомендации по их созданию (отмечу, что статистика ведётся с момента запуска SQL-сервера и при его перезапуске сбрасывается).
Эту статистику можно получить SQL-запросами, представленными в сценариях: «Поиск редко используемых индексов.sql», «Поиск не используемых индексов.sql», «Рекомендуемые индексы.sql» (тексты этих запросов во вложении к статье).
Результат поиска редко используемых индексов будет выглядеть примерно так:

Он содержит в себе имя и тип индекса, таблицу на которой он создан, имя базы данных, содержащее эту таблицу, и статистику обращения к этому индексу.
Результат поиска неиспользуемых индексов схож с предыдущим:

Он содержит более подробную информацию по количеству и типам обращений к индексу и занимаемый индексами объём на диске.
Рекомендации по необходимым индексам выглядят так:

В них указывается таблица, для которой рекомендован индекс и генерируется текст запроса, которым можно этот индекс создать. Также, фигурирует показатель среднего расчётного воздействия Avg_Estimated_Impact. Описать его можно, как среднее оценочное уменьшение «стоимости» выполнения запроса в процентах.
Эти данные следует воспринимать, как задающие направление для возможной оптимизации, а не как прямое руководство к действию, т.к., механизм сбора данной статистики может быть не совсем точен в своей оценке. При изменении состава индексов стоит внимательно анализировать возможные последствия. Не стоит создавать на таблицу больше 5-10 индексов, т.к. избыточное их количество будет только замедлять работу.
Кроме того, полезно проводить анализ SQL-трейсов базы данных. Суть состоит в том, что записав в течение одного рабочего дня трейс с помощью SQL Server Profiler, можно, накладывая различные фильтры, выделять группы ресурсоёмких запросов, которые имеют высокое потребление процессорного времени, большое количество операций чтения-записи и т.п. Выделив «тяжёлые» запросы, можно попытаться их оптимизировать – модифицировать прикладную разработку, создать новые индексы или изменить существующие.
Полезно предварительно подвергнуть разбору действительный план выполнения запроса (Actual Execution Plan). Его можно записать и в трейсе, но «вычленять» его оттуда для конкретного запроса несколько неудобно, поэтому можно выполнить интересующий запрос в SQL Management Studio, предварительно включив на тулбаре кнопку Include Actual Execution Plan. План запроса будет выглядеть примерно так:
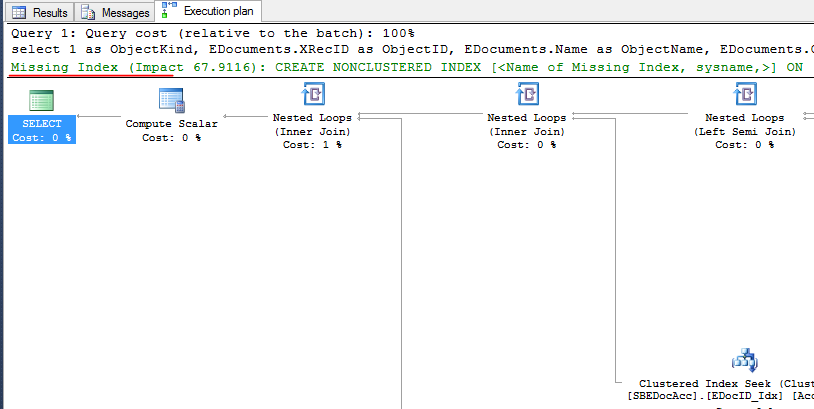
Если оптимизатор запросов посчитает, что для наилучшего выполнения запроса не хватает какого-то индекса, то напишет об этом в шапке плана запроса. Также, сгенерирует шаблон текста запроса для создания этого индекса.
Для советов по оптимизации запроса можно воспользоваться инструментом Database Engine Tuning Advisor, который входит в пакет администрирования MS SQL Server. Достаточно выделить запрос в SQL Management Studio и выбрать в контекстном меню «Analyze Query in Database Tuning Advisor». Далее запустить анализ, по окончании которого будут сформированы рекомендации по созданию индексов. Отмечу, что лучше проводить анализ запроса через этот инструмент не в рабочее время и не спешить притворять их в жизнь, а подвергнуть сначала всестороннему рассмотрению, спрогнозировать возможные последствия.
Мероприятия по актуализации состава индексов должны проводиться администратором системы регулярно.
4. Реорганизация и перестроение индексов
Зачем нужна реорганизация и перестроение индексов?
При выполнении операций добавления, изменения или удаления записей таблицы сервер SQL автоматически актуализирует её индексы и, через определённое время, данные в индексе будут «рассеяны» по базе данных – фрагментированы. Индексы будут содержать страницы, логический порядок данных в которых, основанный на ключевых значениях, будет отличается от физического порядка внутри файла данных. Таким образом, сильно фрагментированные индексы будут приводит к снижению скорости выполнения запросов за счёт увеличения времени получения данных.
Перестроение индекса (REBUILD) удаляет и создаёт его заново, устраняя фрагментацию и уменьшая место, занимаемой им на диске. Данная операция довольно ресурсоёмка, поэтому её стоит выполнять в нерабочее время.
Процесс реорганизации (REORGANIZE) представляет из себя дефрагментацию индекса, в ходе которой происходит физическая сортировка страниц индекса в соответствии с их логическим порядком. Реорганизация индексов использует минимальное количество системных ресурсов, тем не менее тоже рекомендуется выполнять её в нерабочее время.
Полезно создать Задание (Job) по реорганизации/перестроению индексов на сервере SQL, которое будет выполняться каждые один-два дня во время наименьшей нагрузки, например, ночью. В приложении к статье есть пример sql-сценария для Job’а , который, в зависимости он степени фрагментации индекса, делает одну или другую операцию.
5. Обновление статистик
Итак, что же такое статистики и зачем их обновлять?
Статистика – это объект, который содержит статистические сведения о распределении значений в одной или более столбцах таблицы или индексированного представления. Оптимизатор запросов использует статистики для оценки количества строк в результате запроса. Эта оценка количества результирующих строк позволяет оптимизатору построить высокоэффективный план выполнения запроса, что позволяет значительно ускорить его выполнение, тем самым повышая производительность системы.
Обновление статистик обеспечивает компилирование запросов с актуальными сведениями о распределении данных, поэтому данную операцию рекомендуется проводить более-менее регулярно. Однако, не стоить этого делать и слишком часто, чтобы выигрыш в производительности за счёт эффективных планов запросов не был перевешен тратой времени на перекомпиляцию запросов.
Заключение
Следуя этим рекомендациям, регулярно проводя мероприятия по обслуживанию базы данных можно избежать ситуаций с медленной работой системы.
Прикреплен файл: Сценарии.zip
Добрый день! Не скачивается прикреплённый файл "Сценарии.zip"
Добрый день! Та же проблема, что у Сергея, не скачивается файл Сценарии, можете ссылку обновить?
Сергей, Добрый день!
Удалось сохранить как ссылку.
Авторизуйтесь, чтобы написать комментарий