Кэш планов и параметризация запросов. Часть 1. Анализ кэша планов.
Здравствуйте, уважаемые читатели. В этой серии статей мы с вами рассмотрим один из способов оценки эффективности использования кэша планов запросов и три варианта параметризации SQL-запросов, для более эффективного использования кэша планов – простую автоматическую параметризацию, принудительную автоматическую параметризацию и ручную параметризацию запросов.
План выполнения запроса
Для начала давайте в общих чертах посмотрим, как происходит выполнение SQL-запросов сервером Microsoft SQL. Процессор запросов (query processor), который и занимается выполнением SQL-запросов, поступивших на SQL-сервер, и выдачей их результатов клиенту, состоит из двух основных компонентов:
- Оптимизатор запросов (Query Optimizer).
- Исполнитель запросов (Relational Engine).
Поскольку инструкция SELECT не определяет точные шаги, которые SQL-сервер должен предпринять, чтобы выдать клиенту запрашиваемые им данные, то SQL-сервер должен сам проанализировать эту инструкцию и определить самый эффективный способ извлечения запрошенных данных. Сначала инструкция попадает в обработку к оптимизатору запросов, где выполняются следующие шаги, с использованием компонентов оптимизатора:
- Синтаксический анализатор (Parser) просматривает инструкцию SELECT и разбивает ее на логические единицы, такие как ключевые слова, выражения, операторы и идентификаторы, а также производит нормализацию запроса.
- Из синтаксического анализатора данные попадают на вход компонента Algebrizer, который выполняет семантический анализ текста. Algebrizer проверяет существование указанных в запросе объектов базы данных и их полей, корректность использования операторов и выражений запроса, и извлекает из кода запроса литералы, для обеспечения возможности использования автоматической параметризации.
Например, именно поэтому запрос, имеющий в секции SELECT поля, не содержащиеся ни в агрегатных функциях, ни в секции GROUP BY, пройдёт в SQL Server Management Studio (SSMS) проверку по Ctrl+F5 (синтаксический анализ), но свалится с ошибкой при попытке запуска по F5 (не пройдёт семантический анализ). - Далее Algebrizer строит дерево разбора запроса с описанием логических шагов, необходимых для преобразования исходных данных к желаемому результату. Для дерева запроса извлекаются метаданные объектов запроса (типы данных, статистика индексов и т.д.), производятся неявные преобразования типов (при необходимости), удаляются избыточные операции (например, ненужные или избыточные соединения таблиц).
- Затем оптимизатор запросов анализирует различные способы, с помощью которых можно обратиться к исходным таблицам. И выбирает ряд шагов, которые, по мнению оптимизатора, возвращают результаты быстрее всего и используют меньше ресурсов. В дерево запроса записывается последовательность этих полученных шагов и из конечной, оптимизированной версии дерева генерируется план выполнения запроса.
Далее полученный план выполнения запроса сохраняется в кэше планов. И исполнитель запросов на основе последовательности инструкций (шагов), указанных в плане выполнения, запрашивает у подсистемы хранилища требуемые данные, преобразует их в заданный для результирующего набора данных формат и возвращает клиенту.
Шаги, описанные для обработки инструкции SELECT, применяются также и к другим инструкциям SQL, таким как INSERT, UPDATE и DELETE. Для инструкций UPDATE и DELETE результатом создания плана выполнения запроса будет план по определению набора строк, которые должны быть изменены или удалены.
Таким образом в общих чертах происходит создание плана выполнения запроса. И если в дальнейшем SQL-серверу на исполнение поступает аналогичный запрос и план выполнения для данного запроса по-прежнему доступен в кэше планов, то исполнитель запросов выполняет запрос согласно ранее созданному плану выполнения.
Анализ кэша планов
В теории всё выглядит замечательно – для впервые пришедших на SQL-сервер запросов составляются оптимальные планы выполнения, которые в дальнейшем используются для исполнения аналогичных запросов, экономя тем самым процессорные мощности SQL-сервера для более важных задач. Однако на практике, для того чтобы использовать преимущества, предоставляемые кэшем планов выполнения запросов, необходимо соблюдение определенных условий. Но прежде чем мы рассмотрим эти условия, давайте выясним – зачем нужен анализ эффективности использования кэша и как мы можем посмотреть на его использование и узнать, в каких случаях он используется оптимально, а в каких – не очень.
Кэш планов (всех планов, не только планов запросов) располагается в оперативной памяти SQL-сервера и в рабочей среде может достигать размера от нескольких гигабайт до нескольких десятков гигабайт, в зависимости от количества доступной SQL-серверу оперативной памяти и текущего размера буферного пула SQL-сервера.
Посмотреть текущий размер всего кэша планов и кэша планов запросов можно с помощью следующего запроса:
Если в кэш планов поступает много одноразовых планов, которые никогда больше не будут использованы SQL-сервером, то кэш быстро разрастается до своего максимального размера и в дело вступает механизм очистки кэша, который начинает удалять из кэша наиболее старые и наименее ценные планы, высвобождая место под новые планы, которые в дальнейшем так же не будут использованы повторно. Таким образом, если кэш планов используется неэффективно, то помимо выделения под кэш оперативной памяти (которая могла бы быть использована под другие задачи сервера), SQL-сервер постоянно тратит некоторое количество процессорного времени на компиляцию новых планов запросов, на очистку кэша от старых планов и на размещение в нем новых планов запросов.
Для анализа кэша планов запросов мы будем использовать следующий запрос:
Примечание: Для работы запроса требуется уровень совместимости БД, в контексте которой будет выполняться запрос, не меньше 100 и SQL-сервер версии не ниже SQL Server 2008. Если ваша БД меньшего уровня совместимости, но имеющийся SQL-сервер - SQL Server 2008 или выше, то запрос будет работать, поскольку в начале запроса имеется инструкция, задающая контекст базы master для выполнения запроса.
Запрос довольно тяжеловесный и, в зависимости от размера кэша планов в рабочей среде, может выполняться от нескольких десятков секунд, до свыше десяти минут. Если какие-то из данных, собираемых запросом, вам не нужны (как, например, количество инструкций в пакетных запросах) или каких-то данных не хватает (например, статистики по физическим и логическим чтениям, которая в рамках данной статьи не нужна), то вы вольны модифицировать этот запрос исходя из собственных нужд.
Рассмотрим параметры и выходные данные запроса.
Параметр всего один – это переменная @QueryLike varchar(20). Она служит для поиска в кэше планов статистики для конкретного запроса, по указанному набору символов текста запроса. Если переменная не задана, то выводится статистика по всем планам запросов. Чуть ниже мы рассмотрим пример использования этого параметра.
Результатом выполнения запроса является заполненная временная таблица #plans_summary, содержащая следующие данные (столбцы) по статистике кэша планов:
- db_name: Наименование базы данных, в контексте которой выполнялся запрос, для которого сгенерирован план;
- objtype: Тип объекта, для которого сгенерирован план. Хотя в кэше планов могут храниться планы для 11 типов объектов, нам интересны всего два:
- Adhoс – это значение говорит о том, что план был сгенерирован для нерегламентированного (произвольного, не универсального) запроса. Как правило планы именно таких запросов и являются малополезными пожирателями оперативной памяти на SQL-сервере. В реальной рабочей среде далеко не для каждого Adhoc-запроса план может быть использован повторно – для этого запрос должен быть или очень простым, чтобы удовлетворять условиям простой автоматической параметризации (об этом в следующей статье) или должен в точности совпадать с ранее использованным запросом;
- Prepared – это значение говорит о том, что данный план был сгенерирован для заранее подготовленного (параметризованного) запроса. В большинстве случае такие планы могут быть использованы повторно, но бывают и исключения. В конце статьи описаны причины, приводящие к созданию дубликатов планов выполнения для параметризованных запросов;
- usecounts: Счётчик количества выполнений данного плана. Для единожды исполненного запроса равен единице. Для каждого случая исполнения запроса, для которого в кэше был найден подходящий план, счётчик для найденного плана увеличивается на единицу;
- compile_time: Общее время, в миллисекундах, затраченное на компиляцию плана выполнения;
- compile_cpu: Процессорное время, в миллисекундах, затраченное на компиляцию плана выполнения;
- total_worker_time: Процессорное время, в миллисекундах, затраченное на выполнение плана с момента компиляции, с учетом количества повторных использований плана (сумма времени каждого выполнения плана);
- average_worker_time: Среднее процессорное время, в миллисекундах, затраченное на каждое выполнение плана;
- total_elapsed_time: Общее время, в миллисекундах, затраченное на выполнение плана с момента компиляции, с учетом количества повторных использований плана. Учитывает время, потраченное всеми ресурсами SQL-сервера, необходимыми для выполнения запроса – процессор, память, устройства ввода/вывода;
- average_elapsed_time: Среднее общее время, в миллисекундах, затраченное на каждое выполнение плана;
- query_text: Текст запроса, для которого был сгенерирован план;
- size_in_kb: Количество памяти, в килобайтах, занимаемое планом в кэше планов (в оперативной памяти);
- plan_subqueries: Количество скомпилированных планов, содержащихся в общем плане запроса. Равно единице для простых запросов и больше единицы – для пакетных запросов;
- stat_subqueries: Количество инструкций запроса, которые были выполнены при обращениях к плану. Равно единице для простых запросов и может быть больше единицы для пакетных запросов. Отличие от plan_subqueries в том, что в stat_subqueries учитываются только выполненные инструкции запроса. Например, если в запросе есть операторы ветвления, содержащие разные подзапросы, и какие-то ветви запроса ни разу не выполнялись, то невыполнявшиеся инструкции не учитываются. Каждая инструкция учитывается один раз, повторное выполнение инструкций при повторном выполнении всего запроса, не увеличивает счетчик;
- creation_time: Дата и время создания плана выполнения запроса. Это поле можно использовать для оценки текучки планов запросов в кэше;
- last_execution_time: Дата и время последнего использования плана выполнения запроса;
- plan_handle: Токен, ссылающийся на текущий скомпилированный план. Может быть использован для более детального анализа статистики плана;
- parameterized_plan_handle: Токен, ссылающийся на план выполнения для автопараметризованного запроса. Заполняется только для автопараметризованных запросов;
- query_hash: Хэш запроса, на основании которого скомпилирован план выполнения. Данный хэш создаётся из дерева разбора запроса, после прохождения запроса через процедуры синтаксического и семантического анализа, нормализации и упрощения (Parser и Algebrizer), что позволяет использовать этот хэш для поиска планов не только идентичных (без учёта литералов) запросов, но и семантически схожих. Это поле мы и будем использовать для поиска планов похожих запросов.
Пример: Выполним следующий запрос (благодаря инструкции GO он выполнится как два отдельных запроса, а не как один пакетный запрос):
Установим значение параметра @QueryLike в запросе для сбора статистики кэша планов:
И выполним предыдущий большой запрос. Сделав выборку из таблицы #plans_summary
мы получим следующий результат:

Значение query_hash для обоих запросов совпадает, несмотря на то, что в запросах разные условия в секции WHERE.
- query_plan_hash: Хэш плана запроса. Данный хэш создаётся из скомпилированного плана выполнения запроса, что позволяет использовать этот хэш для поиска схожих по алгоритму выполнения планов запросов. Когда запросы с одинаковыми значениями query_hash выполняются на различных данных, оптимизатор запросов может выбрать для этих запросов разные планы выполнения из-за разницы в количестве элементов в результатах запроса. К примеру, для двух одинаковых запросов с разными значениями в условиях выборки (секция where) оптимизатор может использовать разные способы поиска по индексу, что даст разные значения query_plan_hash при одинаковых значениях query_hash;
- query_plan: Содержит представление скомпилированного плана запроса в формате xml. Предназначается для более детального изучения плана и соответствующего ему запроса.
Примечания:
- В колонках total_worker_time, average_worker_time, total_elapsed_time, average_elapsed_time, stats_subqueries, creation_time, last_execution_time, query_hash, query_plan_hash могут содержаться значения NULL, в тех случаях, когда:
- Adhoc-запрос прошел процедуру автопараметризации;
- В запросе содержится только вызов процедуры;
- Запрос не содержит инструкций SELECT, INSERT, UPDATE, DELETE;
- Также в колонках query_hash и query_plan_hash будут значения NULL для пакетных запросов, т.к. в случае пакетных запросов хэш запроса и хэш плана запроса высчитываются для каждой инструкции пакета;
- Обычно общее время выполнения плана (total_elapsed_time) и процессорное время выполнения плана (total_worker_time) примерно равны друг другу. Но есть и обратные ситуации:
- Общее время больше процессорного времени. Общее время выполнения будет превышать процессорное в тех случаях, когда для выполнения запроса потребовалось ожидание данных от дисковой подсистемы или когда запрос ждал окончания какой-нибудь блокировки;
- Процессорное время больше общего времени. Как бы странно это ни звучало, но бывают планы запросов, для которых процессорное время выполнения запроса превышает общее время. И это, на самом деле, хорошие планы выполнения запросов (при условии, что общее время выполнения не превышает разумных величин). Такие ситуации возникают в тех случаях, когда при выполнении запроса процессору запросов не пришлось ждать дисковую подсистему или окончания блокировок, и выполнение запроса, при этом, было распараллелено на два или более процессорных ядра.
Пример: Некий запрос выполнялся на двух ядрах в течение пяти миллисекунд. Общее время выполнения запроса, в этом случае, составит пять миллисекунд. А процессорное время - десять миллисекунд (по пять на ядро).
Примеры использования
А теперь самая интересная часть статьи. Давайте посмотрим статистику использования кэша планов запросов на некотором сервере в некоторой боевой БД (DIRECTUM 5.0, простая автопараметризация).
После формирования таблицы #plans_summary из неё можно делать выборки интересующих нас данных в нужных разрезах.
Статистика по ресурсам, потребляемым Adhoc-запросами
Одноразовые планы выполнения
Запрос:
Результат:

Список полей:
- Count Normal: Количество обычных планов Adhoc-запросов в кэше;
- Count Shell: Количество планов-заглушек в кэше;
- Compile Time (sec): Общее время, затраченное на компиляцию планов (у планов-заглушек равно нулю);
- Compile CPU (sec): Процессорное время, затраченное на компиляцию планов (у планов-заглушек равно нулю);
- Elapsed Time (sec): Общее время, затраченное на выполнение планов (у планов-заглушек равно нулю);
- Worker Time (sec): Процессорное время, затраченное на выполнение планов (у планов-заглушек равно нулю);
- Size Normal (MB): Суммарный размер обычных планов в кэше;
- Size Normal (MB): Суммарный размер планов-заглушек в кэше;
- TTL (hours): Время жизни самого старого плана в текущей выборке. Высчитывается из даты создания и относится только к обычным планам.
Что интересного можно увидеть в результатах этого запроса?
Время компиляции планов одноразовых запросов в несколько раз больше времени их выполнения - это не очень хорошо, но в данном случае не страшно, т.к. цифры всё равно небольшие, в пределах нескольких минут. Самых интересных показателей два - это Size Normal (MB) и TTL (hours). Одноразовые планы занимают больше половины всего кэша планов (размер кэша на момент выполнения запроса - 3,2Гб, что составляет 10% от объёма оперативной памяти сервера), а невысокое время жизни одноразовых запросов (меньше двух часов) говорит о том, что кэш забит под завязку и в нём идёт постоянная ротация планов - вытеснение старых планов и компиляция новых.
Несмотря на то, что планов-заглушек почти в 7,5 раз меньше, чем обычных планов, места в кэше планы-заглушки занимают примерно в пятьдесят раз меньше. Это объясняется тем, что планы-заглушки - это не полноценные планы, а по сути ссылки на автопараметризованные планы и поэтому они занимают заметно меньший объём.
Повторно используемые планы выполнения
Запрос:
Результат:

Поле TTL (hours) в этом запросе отсутствует, поскольку на повторно используемые планы выполнения не распространяется условие, что первым из кэша вытесняется самый старый план - кандидаты на вытеснение вычисляются по более сложной системе расчёта рейтинга планов, основывающейся на счётчике количества выполнений плана. Вообще для одноразовых планов применяется такая же схема поиска кандидатов на вытеснение, но у них счётчик равен единице, что приводит к тому, что у одноразовых планов выполнения запросов рейтинг и так невысок, меньше только у планов-заглушек.
В результатах данного запроса наблюдается обратная от одноразовых планов ситуация - общее время выполнения запросов значительно превышает время компиляции планов, что объясняется тем, что планы выполнения запросов в данном случае был скомпилированы один раз, а выполнены несколько раз. Объём повторно используемых планов для Adhoc-запросов занимает четверть всего кэша. И, что довольно интересно, процессорное время выполнения запросов почти в три раза превышает фактическое время, т.е. какая-то часть запросов, составляющих эту статистику, выполняется с распараллеливанием. Чуть ниже мы в этом убедимся более детально.
Необходимое примечание: Так уж получилось, что данная статистика собрана всего через 5 часов после перезагрузки SQL-сервера, и, следовательно, после полной очистки кэша планов. При более длительной работе SQL-сервера статистика по объёму занимаемого места в кэше значительно смещается от одноразовых планов к повторно используемым, а общее время выполнения начинает заметно превышать процессорное (сказывается тот факт, что далеко не все запросы распараллеливаются, да и не все распараллеливаемые запросы выполняются с использованием параллелизма. Плюс чтение тел документов из БД приводит к ожиданию данных от дисковой подсистемы).
В целом по итогам этой статистики видно, что планы для Adhoc-запросов занимают значительную (более 75%) часть кэша. Производительность SQL-сервера в данном случае от этого не слишком страдает, т.к. время, затрачиваемое сервером на компиляцию планов, всё же горазно меньше времени, затрачиваемого на их выполнение, но оперативная память расходуется неэффективно. Давайте посмотрим статистику по отношению занимаемой памяти к количеству идентичных и схожих запросов.
Поиск планов идентичных и схожих запросов
Планы для схожих запросов мы будем искать с помощью группировки по полю query_hash. Как уже было рассмотрено - это поле является хэш-суммой текста нормализованного запроса и содержит одинаковые значения для схожих запросов. Исключим из выборки планы, счётчик выполнения которых равен единице, т.к. нам сейчас интересна статистика по дубликатам.
Планы схожих Adhoc-запросов
Запрос:
Результат:
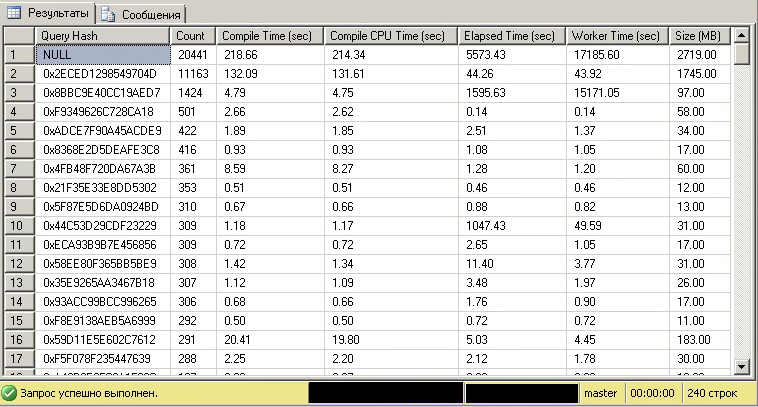
Первая строка - это суммарный итог по всей выборке, по этой же причине поле query_hash для первой строки равно NULL.
Как мы видим 85% всего кэша занимают планы выполнения всего для 239 запросов. Для этих запросов было скомпилировано 20 441 планов выполнения. При этом более половины всего кэша (вторая строка) занимают планы для одного единственного (без учета литералов) запроса, к тому же на компиляцию планов для этого запроса уходит в несколько раз больше времени, чем на их выполнение. Запрос из третьей строки, судя по процессорному времени, как раз и даёт основную статистику по распараллеливаемости. Давайте посмотрим более подробную статистику по этому запросу:
Результат:

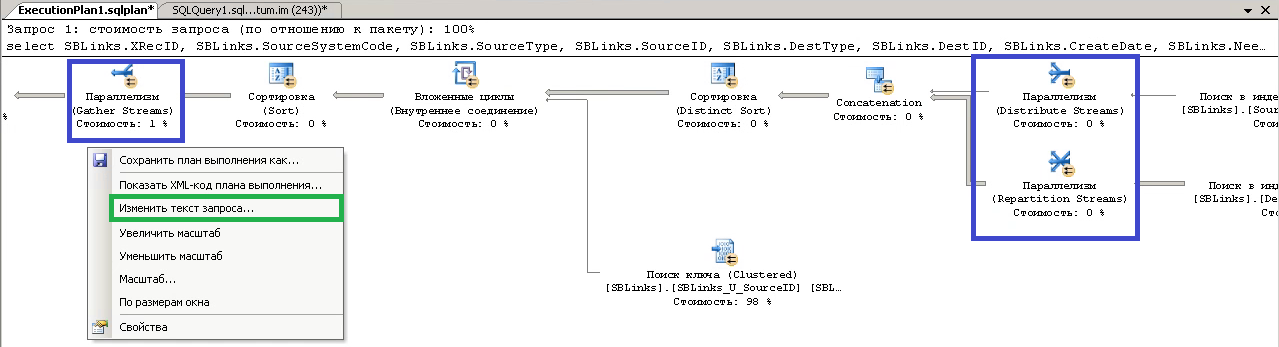
Итого по данному query_hash из 1424 планов всего 4 плана явно выполняются с параллелизмом. Возможно таких планов больше, но время, выигрываемое на распараллеливании, съедается расходами на другие операции и поэтому в данную выборку такие планы не попали. Если щёлкнуть по ссылке, указанной в поле query_plan, то можно посмотреть графическое отображение плана запроса и сам запрос:
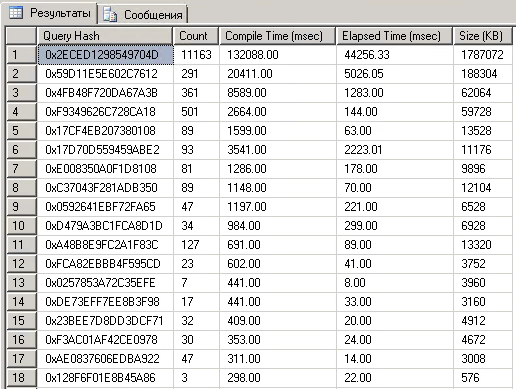
Давайте теперь выведем список query_hash для тех запросов, планы выполнения для которых не только занимают место в кэше, но и на компиляцию которых времени уходит больше, чем на выполнение.
Запрос (с сортировкой по разнице между временем компиляции и выполнения):
Результат:
Планы схожих параметризованных запросов
Дублирующиеся планы выполнения могут создаваться SQL-сервером не только для Adhoc, но и для параметризованных запросов.
Выполним следующий запрос:
Результат:
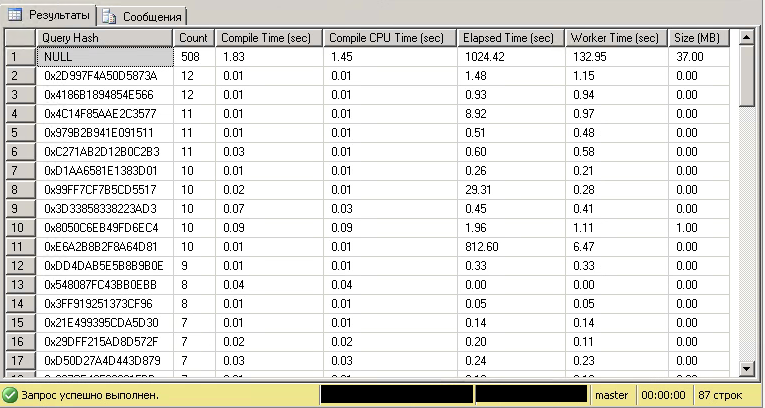
Как видно из результата, для некоторых параметризованных запросов планы выполнения дублируются, давая в сумме 508 планов выполнения, вместо 86.
Причин создания дублирующихся планов выполнения для параметризованных запросов может быть несколько:
- Разные настройки сеанса, задаваемые инструкцией SET при выполнении одного и того же запроса. Например инструкции SET наверняка будут разными при выполнении запроса в Директуме и в SSMS. Но в нашем случае эта причина роли не играет, т.к. абсолютное большинство планов генерируются из запросов, выполняемых в Директуме.
- Различный регистр букв и разное число пробелов в запросах. Например для запросов SELECT Field FROM SomeTable и select field from sometable будут созданы два идентичных плана выполнения.
- Выполнение одного и того же запроса в контексте разных баз данных.
- Экономность автоматического режима параметризации. При выполнении автоматической параметризации SQL-сервер выбирает минимально необходимый тип данных для используемых в запросе литералов (за исключением строковых литералов, для них устанавливается тип данных varchar(8000)).
Пример: Если в БД с принудительной автопараметризацией последовательно выполнить запросы select Field from SomeTable where SomeID = 1 и select Field from SomeTable where SomeID = 10000, то помимо планов-заглушек будут созданы два параметризованных плана выполнения. Один с типом данных smallint, для используемого в запросе литерала, и второй с типом данных tinyint. При выполнении запросов в обратном порядке всё равно будут созданы два параметризованных плана выполнения с такими же типами данных для литералов. - Самая распространённая причина (в нашем случае) дублирования планов параметризованных запросов - обращение к объектам БД без указания используемой схемы. Если запрос ссылается на объект базы данных без указания схемы, то SQL-сервер первым делом ищет этот объект в схеме текущего пользователя, и только потом в схеме dbo. Если объект в схеме пользователя найден, то для запроса будет создан новый план выполнения, даже если идентичный план выполнения для идентичного запроса уже сгенерирован для другого пользователя или для схемы dbo.
Заключение
Уважаемые читатели, в данной статье был рассмотрен один из способов того, как можно проанализировать эффективность использования кэша планов выполнения запросов. Надеюсь, что эта статья была для вас полезной. Если у вас есть какие-то вопросы, то задавайте их в комментариях, постараюсь на них ответить.
В следующей статье будут рассмотрены способы борьбы с неэффективным расходованием оперативной памяти и процессорных ресурсов SQL-сервером с помощью автоматической и ручной параметризации запросов.
Материалы, использованные при написании статьи:
- Справочные материалы по используемым в статье динамическим представлениям - Динамические административные представления и функции, связанные с выполнением (Transact-SQL)
- Обработка инструкций SQL
- Кэширование и повторное использование плана выполнения
- Plan Cache Internals
- SQL Server Execution Plans
- Same query, different execution plans
- Multiple Plans for an "Identical" Query
Авторизуйтесь, чтобы написать комментарий