Архивирование объектов: ускоряем поиск объектов
Механизм архивирования объектов позволяет нам скрыть в системе объекты (записи справочников, документы, задачи и задания), видеть которые постоянно нет никакой нужды, потому что работа с ними уже давно завершена, а данные объектов устарели. Зачем их скрывать? Во-первых, устаревшие объекты бесполезно увеличивают объем данных, загружаемых из СУБД на клиента. А во-вторых, чем больше старых и ненужных объектов будет скрыто из списка, который видит пользователь, тем больше туда поместится новых и полезных. Если кто-то не в курсе механизма, в справке эта тема разложена по полочкам.
Как работает сейчас
Администратор настраивает в справочнике «Правила архивирования» специальные критерии, руководствуясь которыми агент архивирования (сценарий TransferObjectsToArchive) находит и переносит объекты в архив. Да вот беда: строить критерии поиска объектов можно только по реквизитам главного раздела. То есть, например, для входящих РКК можно настроить перенос всех записей по определенному месту регистрации, направленных в дело N дней назад. Все просто и выглядит понятно:

Но если дополнительно требуется проконтролировать, что на закладке «Местонахождение» у всех подлежащих возврату выдач документа заполнена дата возврата, то красиво сделать уже не получится, потому что нужно анализировать данные в детальном разделе. Или такое условие: нужно проконтролировать, что к документам, связанным с РКК, не было обращений за последние полгода, а сама РКК не вложена в «живые» задачи. Вот как описать это в виде критериев в табличной части? Создание дополнительных карточных реквизитов и их заполнение на основе данных в детальных разделах (а также связях, и так далее) не рассматриваем, потому что критерии могут меняться, и каждый раз дорабатывать РКК (и все остальные типы справочников и карточек документов) вслед за изменяющимися критериями, а потом актуализировать уже существующие объекты — это даже не смешно.
Лазейка вроде бы есть: механизм позволяет непосредственно перед архивированием каждого объекта выполнить над ним заданное в правиле ISBL-вычисление. Вычисление предназначено для выполнения действий, связанных с архивированием объекта. В нем же можно реализовать дополнительные проверки, не вписавшиеся в табличную часть с критериями, и при необходимости пропустить архивирование объекта — оставить его оперативным. Очевиден и недостаток такой лазейки: нам придется поочередно примерять наши дополнительные проверки к каждой найденной РКК. А найтись их может немало, ведь часть критериев поиска не удалось описать в настройке. А те, что удалось, могут быть довольно широкими.
Таким образом, проблема состоит в том, что на вход агенту архивирования подается слишком много объектов. Часть из них заведомо неархивируемые, но их все равно приходится обрабатывать.
Что делать
Самый очевидный способ избавить агент от заведомо неархивируемых объектов — это формировать точные критерии поиска. Реализовывать это в виде визуальной настройки "на все случаи жизни" можно, конечно, но очень сложно, потому что необходимо учесть все (в том числе еще не родившиеся) фантазии пользователей. Либо изначально закладывать ограничения и в итоге не решить проблему. А сама система критериев может получиться настолько запутанной, что для ее настройки потребуется лицензия пилота, не меньше.
Есть другой способ. Дело в том, что агент архивирования при обработке настроенных критериев формирует на их основе запрос поиска, возвращающий список ID объектов. Значит, мы можем попробовать написать свой (правильный) запрос и подложить его агенту в качестве критерия. В этом случае агенту останется только выполнить его и обрабатывать полученный список объектов как обычно. Всем проще. Самое главное ограничение тут — для настройки критериев таким причудливым образом необходимо знать физическую структуру данных и уметь писать запросы. Из преимуществ:
- можно написать сколь угодно сложный запрос — критерии поиска получаются максимально точными, что мы и хотели получить,
- в одном критерии можно совместить поиск записей нескольких типов справочников, или типов документов.
Доработанная карточка правила архивирования может выглядеть как-то так (обратите внимание на кнопку "Запрос" на ленте):
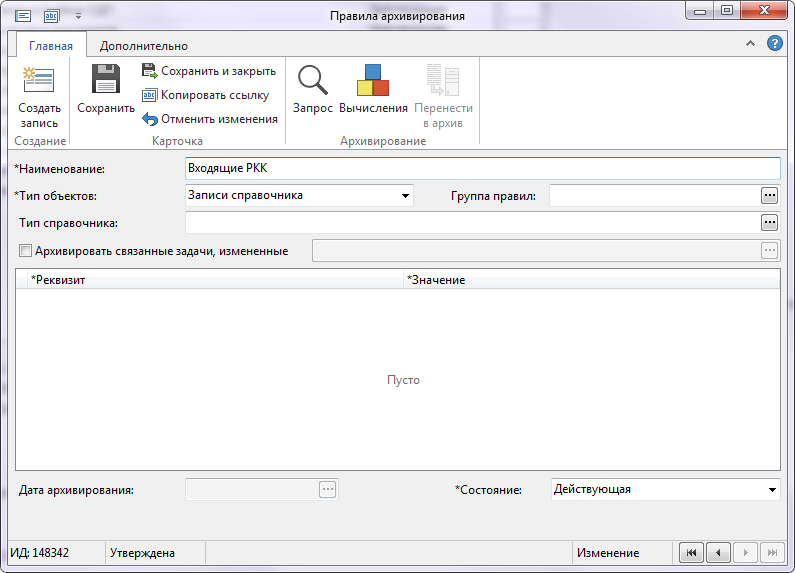
Критерий хранится в текстовом реквизите и пишется в окне текстового редактора, который открывается по нажатию на кнопку "Запрос". Текст критерия для первоначального примера включая условия, которые не поместились в настройку:
declare @RCRefID int, @JrnRefID int
select @RCRefID = Vid from MBVidAn where Kod = 'РКК'
select @JrnRefID = Vid from MBVidAn where Kod = 'ГДЛ'
select rc.Analit
from MBAnalit rc
join MBAnalit jrn on jrn.Analit = rc.GruppaDel and jrn.Vid = @JrnRefID
where RC.Vid = @RCRefID
/* Вид РКК = "Входящие" */
and rc.PriznDok = 'В'
/* Место регистрации = "Канцелярия" */
and jrn.MestoReg = 123456
/* Направлены в дело более 365 дней назад*/
and rc.Data7 < dateadd(day, -365, getdate())
/* Возвращены все выдачи */
and not exists (select 1
from MBAnValR dds
where dds.Vid = rc.Vid
and dds.Analit = rc.Analit
and dds.YesNoT = 'Д'
and dds.Data2T is null)
/* Нет задач по РКК в работе */
and not exists (select att.TaskID
from SBTaskAttach att
join SBTask task on task.XRecID = att.TaskID
and task.State = 'W'
where att.AttachType = 'R'
and att.AttachID = rc.Analit)
/* Дата последнего доступа к документам РКК более 6 месяцев назад*/
and (select max(hist.ActionDate)
from SBLinks link
join SBEDocProtocol hist on hist.EDocID = link.DestID
where link.SourceType = 'R'
and link.SourceID = rc.Analit
and link.DestType = 'E') < dateadd(month, -6, getdate())
Не так уж и сложно.
А что же агент архивирования? Агент должен уметь обрабатывать критерии поиска в новом формате. В стандартном агенте сборка запроса для поиска объектов происходит в функции GetArchiveAddWhere(). Мы заранее озаботились совместимостью, и теперь нам только нужно подменить вызов этой функции чтением нашего запроса. Таким образом, существенной доработки агента и не потребуется. Можно даже сохранить совместимость со стандартной настройкой правил архивирования. Это позволит не писать запрос, когда критерии поиска целиком ложатся в табличную часть правила архивирования.
Что получилось
Мы реализовали в справочнике правил архивирования возможность вместо заполнения табличной части критериев описывать их в виде SQL-запроса. Что нам это дало — скальпель! Теперь мы сможем точно описывать сложные критерии поиска и избавим агент архивирования от неархивируемых объектов. Однако у нас все равно может получиться довольно много объектов, особенно если система активно эксплуатировалась в течение длительного времени, да еще при внедрении в нее занесли ворох исторических данных. На обработку большого количества объектов агент может потратить внушительное количество времени. О том, как можно ускорить работу собственно архивирования — в следующий раз. Пока!
Авторизуйтесь, чтобы написать комментарий