Интеллектуальные механизмы. Ожидания и реальность
А вы уже ознакомились с возможностями интеллектуального решения DIRECTUM Ario и оценили его применимость к закрытию потребностей вашего предприятия? Если нет, то эта статья для вас. В статье постараемся сопоставить ожидания наших заказчиков от интеллектуальных механизмов и реальность их внедрения, а также возможности DIRECTUM Ario.
Ожидания: Интеллектуальные механизмы полностью заменят секретарей
Интеллектуальные механизмы возьмут на себя все функции по обработке потока документов в организации. Сотрудники больше не будут задействованы в этом процессе.
Реальность
На первом шаге решение Ario освобождает пользователей от рутины при первичной обработке документов: извлечение текстового слоя, определение вида документа, извлечение реквизитов документа и занесение их в карточку документа, отправка документа ответственному лицу для дальнейшей обработки. А также может заносить информацию о новом контрагенте, переносить данные между ИТ-системами и т.д.
В будущем решение облегчит труд пользователей в ходе подготовки проектов резолюций, автоответов, при аннотировании документов, создании кредитного досье или личного дела сотрудника, реализации интеллектуального поиска и т.д.
Использование решения Ario позволяет двигаться в сторону «умной» ECM-системы, максимально исключающей выполнение рутинных операций пользователями.
Согласно исследованию компании Transparency Market Research, офисный работник тратит до 40% своего рабочего времени на рутину. Повторяющиеся операции с документами в ECM-системах отнимают не только время, но и вызывают негатив у исполнителей и ошибки человеческого фактора.
Использование Ario позволяет снизить рутину и высвободить человеческие ресурсы для более сложной интеллектуальной деятельности. Ario обеспечит:
- корректную классификацию не менее 80% поступающих документов по их видам;
- корректное извлечение 70% реквизитов документов в текстовой выборке (без учета рукописного текста).
Сотрудники остаются важным и неотъемлемым звеном, так как необходимо верифицировать результаты, которые автоматически были занесены. Необходимо контролировать качество данных, чтобы система далее обучалась на правильных данных, особенно в нестандартных ситуациях.
Как это работает
Этапы обработки документа в системе DIRECTUM с применением Ario:
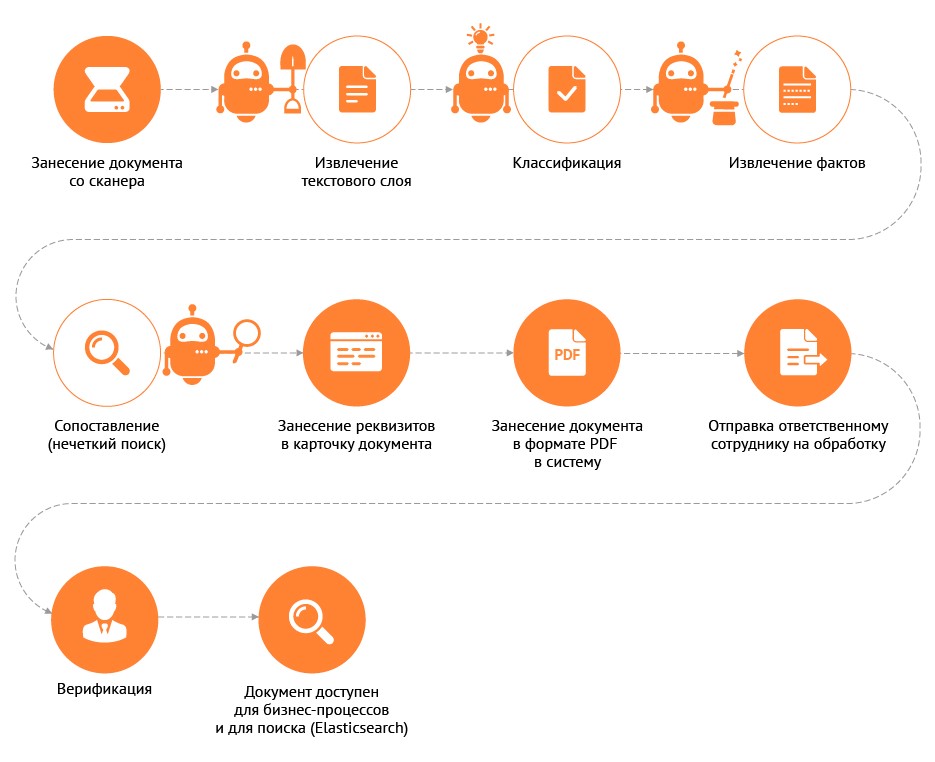
Занесение документа в систему
Документы могут поступить на вход решению из различных источников: электронная почта, потоковый сканер, оператор обмена электронными документами, например, Synerdocs.
В случае массового занесения документов возможно:
- разделение документов в потоке без использования страниц разделителей и штрих-кодов;
- определение ведущего документа в потоке (например, отделение письма от приложений);
- занесения всего потока документов как в виде единого документа, так и в виде комплекта связных между собой документов.
Распознавание текста (извлечение текстового слоя)
В результате обработки скан-образа формируется документ в формате PDF с извлеченным текстовым слоем. Далее полученный текст используется для классификации документов и извлечения фактов, а также для полнотекстового поиска с помощью удобных инструментов поиска (ElasticSearch).
Классификация документов
Классификация документов может осуществляться в различных разрезах: по виду документа, источнику поступления, категории документа, журналу регистрации, месту регистрации и т.д. Классификация происходит на основе результатов машинного обучения на данных заказчика.
Кроме того, Ario теперь анализирует файл, который поступил на вход, и находит первые страницы, определяя таким образом, что файл состоит из нескольких документов, и заносит комплект документов, например, договор и приложение или счет-фактура и акт.
Извлечение реквизитов документов (фактов)
Решение поддерживает извлечение определенного набора реквизитов для следующих видов документов:
- финансовые документы: товарно-транспортная накладная, счет-фактура, корректировочный счет-фактура, универсальный передаточный документ, универсальный корректировочный документ, счет на оплату, акт выполненных работ;
- договорные документы: договор, дополнительное соглашение;
- входящее письмо;
- паспорт гражданина РФ;
- свидетельство о постановке на налоговый учет.
В системе настроен ряд правил для извлечения фактов. Например, у писем извлекается корреспондент, адресат, тема письма и гриф доступа. Из паспорта — серия, номер и дата выдачи документа, а также ФИО и дата рождения гражданина. Из свидетельства — наименование организации/ФИО физического лица, ИНН, ОГРН и КПП организации. Для заказчика может быть разработана поддержка извлечения фактов из специфических видов документов.
Решение не зависит от формы обрабатываемого документа и может успешно применяться на любых видах документов, в том числе неструктурированных.
Извлеченные реквизиты заносятся в карточку документа. Решение встроено в систему DIRECTUM, что позволяет работать в едином интерфейсе ECM-системы, сопоставлять распознанные реквизиты с имеющимися в системе справочными данными. Для специалиста, который проводит верификацию, поля для удобства подсвечены. Например, так выглядит верификация для входящего письма.
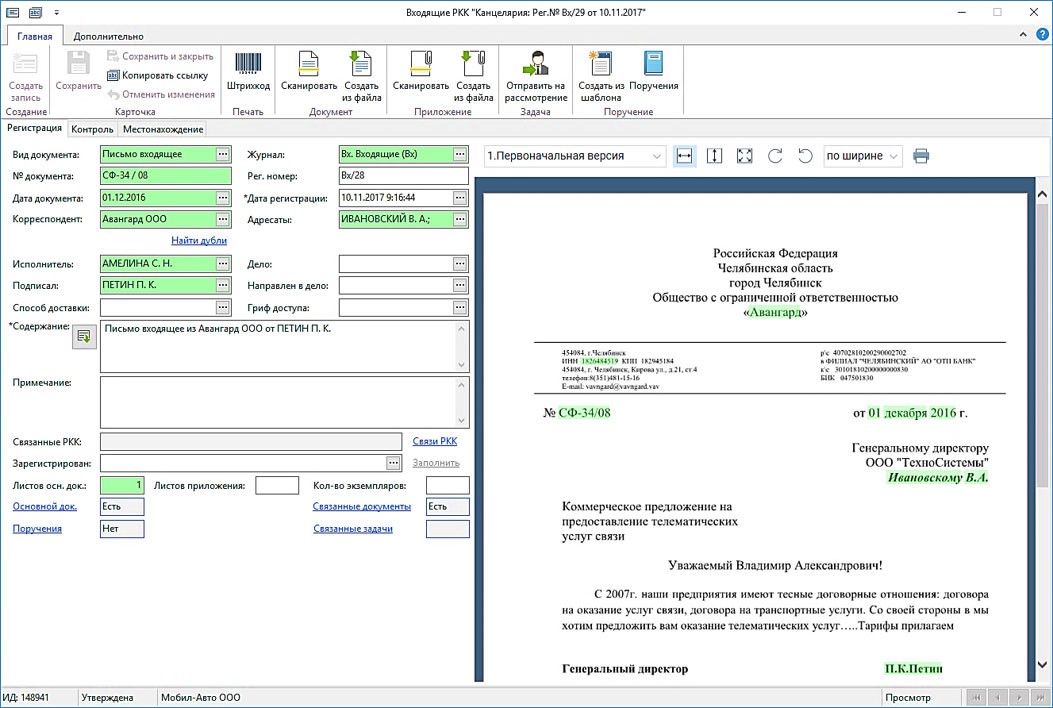
В приведенном примере наименование корреспондента в извлеченном тексте отличается от информации в справочнике системы DIRECTUM (Общество с ограниченной ответственностью «Авангард» и Авангард ООО). Однако алгоритмы «нечеткого поиска», которые используются в решении Ario, позволили сопоставить эти данные.
Отправка документов в обработку
Информация, получаемая по итогам обработки документов с помощью решения, используется в прикладной логике системы DIRECTUM в соответствии с потребностями заказчика. Например, документ может быть вложен в задачу и отправлен на дальнейшее согласование ответственному сотруднику. Может быть реализован процесс потоковой обработки документов или миграции исторических данных.
Процесс потоковой обработки документов:
- Документы массово заносятся в систему из электронной почты и с потокового сканера.
- Производится классификация документов по видам и извлечение их реквизитов.
- Реквизиты документа заносятся в его карточку.
- Документ регистрируется в системе и отправляется на обработку ответственному сотруднику.
Миграция исторических данных:
- Скан-образы документов заносятся в систему из текущего электронного архива.
- Производится классификация документов по видам, извлечение текстового слоя и реквизитов документов.
- Документ помещается в оперативный или долговременный архив организации.
Ожидания: Внедрение слишком сложно
Внедрение интеллектуальных механизмом на предприятии – это довольно сложный и трудоемкий процесс.
Реальность
Для эффективного внедрения Ario достаточно провести комплекс следующих мероприятий:
- Исследование и анализ бизнес-процессов заказчика: включает в себя анализ видов обрабатываемых документов, определение перечня извлекаемых реквизитов, изучение бизнес-процесса, в который встраивается решение.
- Проектирование и адаптация системы DIRECTUM: включает в себя адаптацию сценариев импорта, типовых маршрутов обработки документов.
- Обучение Ario для создания модели классификации по видам документов.
- Проведение тестовой эксплуатации.
- Проведение опытно-промышленной эксплуатации.
Например, для входящих писем средняя продолжительность проекта внедрения силами вендора составляет 2 месяца. Работы по внедрению решения могут осуществляться вендором, партнерами и даже самим заказчиком.
Ожидания: Внедрение окупится на любом предприятии
Достаточно установить решение, обучить его немного, запустить в промышленную эксплуатацию, и внедрение интеллектуальных механизмов окупится моментально на любом предприятии.
Реальность
Рекомендуется внедрять решение на больших объемах обрабатываемых документов, где трудоемкость рутинных операций сопоставима с затратами на автоматизацию.
Политика лицензирования Ario по количеству обрабатываемых документов в месяц позволяет с легкостью рассчитать сроки окупаемости решения*:

(*) Окупаемость рассчитана исходя из стоимости обработки одного документа делопроизводителем.
За помощью в расчете эффективности внедрения Ario на вашем предприятии обращайтесь к вендору или партнерам.
Для этого достаточно предоставить следующую информацию:
- Виды и количество документов в месяц, которые планируется обрабатывать решением.
- Задачи автоматизации: распознавание текста, классификация документов, извлечение реквизитов.
- Источники занесения документов в систему: сканер, электронная почта, системы обмена. Количество точек занесения.
- Дальнейшие действия в системе по итогам обработки документов: регистрация документа, отправка на согласование и т.д.
Надеемся, реальность вас не разочаровала, но приблизила к пониманию, как и для чего можно начать использовать действительно современные интеллектуальные механизмы вместе с DIRECTUM Ario.
Добрый день, коллеги!
1) Есть ли "обратная связь" по работе человека, верифицирующего данные? То есть, например: система распознала номер некорректно, сотрудник его исправил в карточке, а система при этом сама обновила информацию в ранее извлечённом текстовом слое.
2) Проверялось ли, насколько корректной будет работа Elastic search? Извлечённый текстовый слой верифицируется оператором не полностью, а лишь в части извлекаемых реквизитов, соответственно непонятно как учтены недостатки распознавания для целей дальнейшего использования при поиске данных.
3) Рекомендую реализовать подсветку не всех полей в карточке со всеми местами в документе, а подсветку в карточке с динамически изменяемой подсветкой в тексте документа именно тех мест, из которых был извлечён конкретный реквизит (на котором сейчас курсор); ну или сделать подсветку текущего факта более насыщенной.
Артем, по 3) - цвета в карточке менять можно, можно совсем отключить, это прикладная
Артем, спасибо за проявленный интерес. Постараюсь дать пояснения.
>>1) Есть ли "обратная связь" по работе человека, верифицирующего данные? То есть, например: система распознала номер некорректно, сотрудник его исправил в карточке, а система при этом сама обновила информацию в ранее извлечённом текстовом слое.
Когда верификатор корректирует в карточке значение извлеченного реквизита, система обучается.
Приведу наглядный пример:
Из текста документа извлечен реквизит - название контрагента "Ромашка". Система автоматически выбрала из записи справочника Организации "Ромашка НПЗ". Верификатор заменил это значение в карточке на "ПАО Ромашка". В последующем при извлечении "Ромашка" из текста другого документа значение реквизита автоматически заполнится как "ПАО Ромашка".
При этом замена некорректного значения в текстовом слое документа не реализована.
>>2) Проверялось ли, насколько корректной будет работа Elastic search? Извлечённый текстовый слой верифицируется оператором не полностью, а лишь в части извлекаемых реквизитов, соответственно непонятно как учтены недостатки распознавания для целей дальнейшего использования при поиске данных.
Извлеченный текстовый слой действительно не проверяется верификатором.
Но качество извлеченного текстового слоя напрямую влияет на корректность классификации документов, достоверность извлеченных реквизитов, эффективность полнотекстового поиска.
>>3) Рекомендую реализовать подсветку не всех полей в карточке со всеми местами в документе, а подсветку в карточке с динамически изменяемой подсветкой в тексте документа именно тех мест, из которых был извлечён конкретный реквизит (на котором сейчас курсор); ну или сделать подсветку текущего факта более насыщенной.
В тексте документа выделяются только те факты, которые были заполнены в карточке. Одним цветом выделяются достоверно извлеченные факты, другим – менее достоверно. Политру цветов можно настраивать. Верификатор обращает внимание на менее достоверные реквизиты для последующей корректировки при необходимости.
Использование курсора не было реализовано, т.к. оно увеличивает количество действий пользователя (наведение курсора, клик по реквизиту).
Коллеги, благодарю за ответы!
Небольшое дополнение по п.3: менять подсветку целесообразно как раз для целей верификации/корректировки; то есть, дополнительные действия "встать в поле и изменить данные" сотрудник и так произведёт, рекомендую просто помочь ему быстрее найти конкретное место в тексте, где он должен увидеть правильную информацию, если вдруг засомневался в ней.
Артем, обязательно учтем ваше предложение. Благодарим за активность в развитии нашего продукта :)
Авторизуйтесь, чтобы написать комментарий