История одной интеграции
Пролог
Однажды на проекте по модификации DIRECTUM нам понадобилось доработать интеграцию с SAP. Задача была тривиальной: данные из SAP сливались в промежуточную БД, мы забирали их из этой промежуточной БД и загружали к себе в справочники. Эта схема уже работала, и всё, что нам требовалось с ней сделать, это добавить ещё один справочник.

У нас был мощный сервер разработки, не менее мощный сервер тестирования и продуктив, пока ещё только-только проявляющийся на горизонте. SAP, промежуточная БД, DIRECTUM, один справочник, один сценарий… Что могло пойти не так?
Нет повести прекраснее на свете...
Написание кода сценария и его альфа-тестирование мы смогли уложить в три дня и успели подумать, что на этом дело закончено.

Но, как водится, реальность даже не подумала совпасть с ожиданиями. На пользовательском тестировании выяснилось, что данные мы забрали не все. Вместо одной таблицы в промежуточной БД потребовалось загружать три, объём данных на выходе по сравнению с первоначальным вырос в 2,5 раза. И, разумеется, требования по сохранению быстродействия никто не отменял: все сценарии интеграции выполнялись ночью настолько плотным потоком, что идеальным вариантом было бы не просто сохранить длительность выполнения нашей загрузки на прежнем уровне, но и ускорить её, насколько это возможно.
Акт первый, действие первое. Оптимизация от чайников для чайников.
Первой жертвой в борьбе за быстродействие пало открытие справочников на клиенте.

Вероятно, открывать справочник один раз, а затем искать в нём нужные записи с помощью Locate было приемлемым вариантом, когда этот справочник содержал 15 тысяч записей, но при дальнейшем увеличении количества записей этот код ожидаемо начинал тормозить. За что и был безжалостно пущен под нож:
До:
cRef = CreateReference(RefName)
cRef.Open()
cRef.Locate(cKeyReqNames, cKeyReqValues)
После:
cRef = CreateReference(RefName)
cRef.AddWhere(Condition)
cRef.Open()
На этом этапе производительность сценария оценивалась по его лог-файлу, и время выполнения сценария на тестовом прогоне в БД разработки составила около 6 часов для загрузки данных с нуля и около 3 часов для загрузки обновлений.
Акт первый, действие второе. Факап на базе тестирования.
Будучи весьма довольными проведённой оптимизацией, мы установили обновлённый сценарий в тестовую базу и в тот же вечер запустили его и стали ждать результата.

Данные на тестовой базе могли незначительно расходиться с данными на базе разработки, поэтому мы ожидали, что время выполнения сценария в тестовом контуре составит 8-10 часов. И здесь нас ждало первое разочарование: ни через 8, ни через 10, ни через 12 часов сценарий свою работу не завершил. Не завершил он её и через 16 часов, и даже через 24. Что-то явно пошло не так, и в том же логе сценария мы увидели, что именно: на создание/обновление одной записи он начал тратить от 5 до 8 секунд, что, само собой, не было приемлемым.
Интерлюдия. Прикладной разработчик DIRECTUM и профайлинг ISBL.
Получив неприлично огромную длительность создания/обновления записи, мы задались отнюдь не риторическим вопросом: куда уходит время? Как уважающие себя разработчики, мы знали о таком инструменте, как STDbg.exe, и знали, что помимо отладки он умеет ещё и в профилирование. И незамедлительно использовали эти знания для поиска ответа.
Ответ оказался неутешительным. Несмотря на оптимизацию, проведённую в первом действии, открытие справочника всё ещё съедало существенную долю времени, как и отработка событий сохранения записи. Отключить вычисления на этих событиях возможности не было, и мы задумались о том, как можно их ускорить.
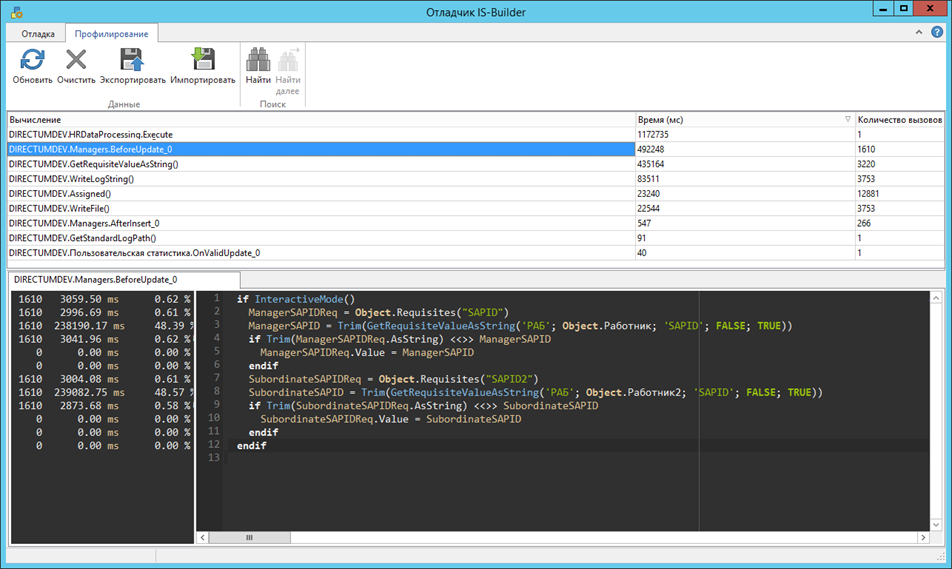
Картину очевидно портила функция GetRequisiteValueAsString, использующаяся на событии Сохранение До. Помимо медлительности она страдала ещё и не самой очевидной обработкой возникающих исключений, а посему тоже отправилась под нож, что не замедлило положительно сказаться на производительности:
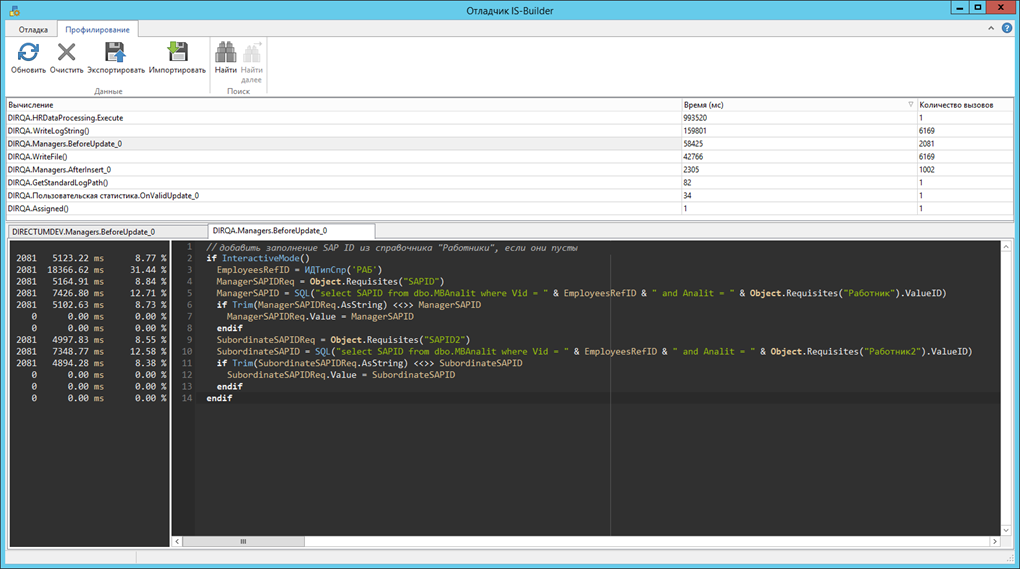
Впрочем, проблемы со скоростью в момент открытия справочника, где прикладных вычислений не было, никуда не делись. Не беда, подумали мы, и отправились на следующий уровень.
Акт второй, действие первое. We need to go deeper: SQL Server Activity monitor и где его найти.
Любое открытие справочника – это всего лишь SQL-запрос, и, как всякий запрос, он может быть отловлен как SQL-профайлером, так и Activity monitor-ом. Поскольку сценарий всё ещё работал, мы воспользовались монитором, где тут же в режиме реального времени увидели, что происходит на сервере.

У платформенного запроса на открытие справочника, который теперь отрабатывал для каждой записи, был довольно высокий показатель Average Duration (около 2c). Заглянув в план выполнения запроса, мы убедились, что для полного счастья нам не хватает индекса для поиска записи справочника по её SAP ID.
Индекс – это краеугольный камень любого поиска, в том числе и поиска строки в таблице БД. Если индекса на таблице нет, поиск по ней осуществляется перебором, что при большом количестве данных может и будет работать медленно. Индекс же ускорит поиск, но займёт дополнительное место на диске и будет обновляться при каждой вставке/изменении/удалении данных в таблицу, поэтому использовать его лучше с оглядкой. В нашем случае профит от добавления индекса был несомненно больше, чем сопутствующие расходы, поэтому сомнения нас не терзали.
После манипуляций с индексами показатель Average Duration для платформенного запроса упал до 0, и, вздохнув с облегчением, мы поставили сценарий на тестовый прогон в БД разработки. Время работы сценария сократилось до 3,5 часов.
Акт второй, действие второе. Дежа вю, или ещё один факап на базе тестирования.
После тестового прогона сценария в БД разработки и мелких оптимизаций ISBL-кода мы, наконец, решились на повторное тестирование. Свет, камера, мотор Экспорт пакета, импорт, запуск – и довольный собой разработчик отправляется пить кофе и ждать результатов тестирования.

Результаты снова оказались неутешительными: 13 часов работы сценария – это лучше, чем 37, но всё ещё неприемлемо, если нам нужно запускать интеграцию каждую ночь.
История повторилась: STDbg, SQL Activity Monitor, но в этот раз всё было чисто. Тестовый прогон с нуля на базе разработки уложился в рекордные 2 часа, но на базе тестирования всё было по-прежнему скверно. Сверили разработку на идентичность, обновили индексы, перезагрузили сервер тестирования – безрезультатно. Что-то шло не так на тестовом контуре, но что именно?
Промучившись над этим вопросом около часа, мы приняли решение поставить эксперимент на продуктиве. Эксперимент был полностью безопасен: из всех доработок устанавливалась только интеграция, установка шла под контролем администратора и в любой момент могла быть прервана, разработчик поддерживал весь этот процесс удалённо. Вечер обещал быть томным…
В итоге ни одна из предосторожностей не оказалась лишней, но эксперимент удался: в продуктиве сценарий выполнялся 3 часа при условии загрузки основной массы данных с нуля. Вздохнув с облегчением, мы отправились спать, а наутро оповестили заказчика об успешном завершении эпопеи.
Эпилог
Из этой истории мы вынесли для себя глубокую (или не очень) мораль, укладывающуюся в несколько простых тезисов:

- Объём и полноту загружаемых данных лучше проконтролировать заранее и по возможности проверить силами заказчика как можно раньше.
-
Производительность лучше тестировать до установки в тестовый контур.
-
Для выявления узких мест в разработке лучше использовать не интуицию, а профайлеры, в нашем случае - ISBL и SQL.
-
Предела совершенству нет, но иногда лучше вовремя остановиться.
-
Эксперименты на продуктиве безопасны, но только при условии, что все участники эксперимента знают, что делают.
- Не все задачи настолько просты, насколько кажутся.
З.Ы. Кстати, вопрос о том, что было не так с тестовым контуром, так и остался открытым. Предлагайте в комментариях свои версии.
Предлагать свои варианты, не понимая что происходило в системе сложно...
На моей практике проблемы чаще всего в 2 вещах: клиент и сервер (спасибо кэп :))
А если по делу:
1. ресурсов машины, где запускался сценарий было достаточно? Существенные тормоза могут быть просто потому что на машине не хватала ОП и/или ЦПУ. Обычно прикладники на это внимание не обращают и сразу бегут смотреть прикладной код.
2. Что показывал activity monitor на SQL сервере? кроме банально тормозных запросов стоит обращать внимание на ожидания. Там фиксируются какой запрос сколько сидит в режиме ожидания и какой ресурс запрос ожидает. Обычно ожидания возникают из-за блокировок (какой нибудь негодяй параллельно запустил какой нибудь другой агент/что нибудь еще интересное и это что то просто начало блокировать ресурсы, которые изменялись интеграцией) и из за дисков (тут все просто, SQL сервер, точнее его диски, могут просто не справляться с вашей скоростью записи/чтения данных).
Андрей, спасибо за варианты :)
1. Заказчик высказывал похожее предположение и сам предложил добавить ресурсов на тестовый сервер, доведя его до характеристик продуктива. То есть dev-сервер был слабее, чем тестовый. Достаточность ресурсов проверяли монитором ресурсов Windows, хватало и ОЗУ, и ЦП, и диска.
2. Ожидания в мониторе тоже проверяли, ничего подобного не было. По дискам было предположение, что на dev-сервере установлен SSD, а на тестовом - HDD, но оно не подтвердилось. Со слов заказчика, оба сервера функционировали на HDD.
У нас было предположение, что поскольку оба сервера виртуальные, а не железные, то могла быть какая-то дополнительная нагрузка на гипервизор с других ВМ, но доступа к нему у нас не было, и проверить это мы не смогли.
За PreprocQuery и GetRequisiteValueAsString надо бить по рукам.
А какой объём данных переносился/обрабатывался в рамках этой разработки?
Роман, у нас в процессе оптимизации родилось предложение оформить замечание к этой функции, распечатать её текст и сжечь в торжественной обстановке а бить по рукам - ну не знаю, пока не залезешь в код этой GetRequisiteValueAsString, она выглядит вполне себе безобидно.
а бить по рукам - ну не знаю, пока не залезешь в код этой GetRequisiteValueAsString, она выглядит вполне себе безобидно.
По объёму данных: до модификаций было ~30к записей, после первой фазы стало ~45к, в самом конце - ~75к. То есть общий объём вырос в два с половиной раза.
Александра, вместо функции GetRequisiteValueAsString() используйте ReferenceRequisiteValue(), она получает значение реквизита быстро и без применения объектной модели.
Как совершенно верно заметил Алексей, есть системная функция, которая берёт значение реквизита.
Но как водится есть один минус, у этих функций чуть-чуть разные сигнатуры и предназначение, ReferenceRequisiteValue может также записывать значение реквизита.
Так как в 90% случаев необходимо просто получить значение реквизита, без вычислений мы просто напросто сделали drop in замену GetRequisiteValueAsString назвав её GetRequisiteValueAsStringSQL.
На простом примере взять значение "Рег номера" из РКК (как самый большой справочник):
Получаем такую картину:
- стандартные функции всегда инициируют справочник, как следствие идёт столько запросов, сколько есть табличных частей у справочника, в случае с РКК это основная таблица и до MBAnValR8.
- все запросы отрабатывают быстро, кроме GetRequisiteValueAsString по коду записи, и как не прискорбно данная конструкция встречается в типовой разработке чаще всего, как вывод - всегда берите значение по ИД.
GetRequisiteValueAsString по коду записи:
GetRequisiteValueAsString по ИД записи:
ReferenceRequisiteValue:
GetRequisiteValueAsStringSQL по ИД и по Коду:
Если же не отключать выполнение событий при открытии справочника, то GetRequisiteValueAsString выполняется ещё дольше, но всё зависит от конкретных справочников.
Это не самая большая база данных, 1,5 млн записей в РКК, версия Директум 5.3.
Но это всё ерунда, по сравнению с супер штукой "Дополнительные реквизиты справочников".
Роман, судя по запросу в трейсе, GetRequisiteValueAsString по коду ещё и без индекса будет искать запись, потому что ltrim и rtrim. Потому да, лучше брать значение реквизита прямым SQL-запросом и по ИД.
А дополнительные реквизиты - это боль, да. Если правильно помню, при программной работе со справочником набор загружаемых реквизитов можно ограничить, это не помогает? Или проблемы при работе в визуальном режиме?
С ними простое решение: нет дополнительных реквизитов - нет проблем!
Там происходят ужасные join при любом действии со справочником, соответственно стандартная разработка под них ни разу не адаптирована. Правда проблемы ощущаются на больших количествах записей, сотнях и миллионах. В связке РКК-Поручения для реквизита Исполнители их проще удалить и не использовать.
А по ltrim(rtrim или rtrim(ltrim достаточно каждому поискать (например через ISBLScan Viewcode) по своей базе и посмотреть объёмы бедствия.
По теме же статьи: иногда при миграциях больших объёмов, либо сложной логике, можно генерировать записи справочника прям в SQL через процедуры и т.п. Конечно есть минус, что логику событий придётся писать на SQL, но тут надо смотреть конкретные условия. Если на каждую из 75000 записей надо сходить в SAP или веб-сервис и т.д., то возможно даже через самописные утилиты имеет смысл делать. Хотя 75000 записей / 2 часа = 10,4 записи в секунду, всё-таки не highload.
Ну и многопоточность можно всегда оформлять в каком либо виде, вместо одного потока, запускать сразу 5-10-15 с градациями по диапазонам ID/дат/времени и т.п.
Авторизуйтесь, чтобы написать комментарий