Развертывание отказоустойчивых служб Redis и RabbitMQ для сервисов DirectumRX
Продолжаем серию статей по настройке отказоустойчивости сервисов для DirectumRX. В данной статье рассмотрим готовую реализацию отказоустойчивых Redis и RabbitMQ.
Почему эта тема актуальная:
- Многие сервисные службы DirectumRX являются микросервисами, которые обмениваются между собой метаданными через очереди сообщений. В случае выхода из строя очереди, потери данных в очереди может быть нарушена логика работы системы.
- Многие крупные заказчики реализуют на своей стороне отказоустойчивую и масштабируемую инфраструктуру. Основным требованием в этом случае является реализация отказоустойчивости каждого узла.
Подготовка экспериментального стенда
Спроектируем инфраструктуру стенда от общего к частному:
- Требуется, чтобы клиентское приложение обращалось к одному IP-адресу или одному доменному имени и портам для подключения к сервису RabbitMQ и Redis.
- Клиентское приложение ничего не знает про отказоустойчивость сервисов и не может влиять на выбор работающего узла.
Уточним схему, введем узел реверс-прокси, который будет перенаправлять обращения к определенному порту на необходимый сервис:
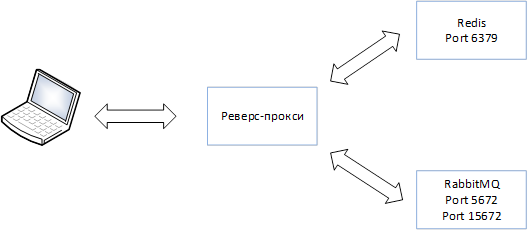
В предыдущих статьях подобная схема рассматривалась (Реализация отказоустойчивого Redis в рамках горизонтального масштабирования DirectumRX, Горизонтальное масштабирование и отказоустойчивость Redis для сервисных служб DirectumRX), в качестве реверс-прокси предлагалось использовать HAProxy.
Отказоустойчивость HAProxy может быть реализована за счет использования системной службы Keepalived. Сервис Keepalived реализует механизм «плавающего» виртуального IP адреса. В случае выхода из строя одного из узлов, виртуальный адрес переназначается дублирующему узлу. Для автоматического переключения IP адреса используется протокол VRRP (Virtual Router Redundancy Protocol).
Реализация вариантов отказоустойчивости Redis подробно рассмотрена в статье Горизонтальное масштабирование и отказоустойчивость Redis для сервисных служб DirectumRX. В данном случае будем использовать вариант Redis Cluster, поскольку этот вариант является наиболее простым в реализации и надежным.
Настройка отказоустойчивости RabbitMQ будет рассмотрена также. Для отказоустойчивости RabbitMQ используется встроенная функциональность обмена сообщениями между нескольких узлами RabbitMQ.
В итоге получаем следующую схему размещения сервисных служб:
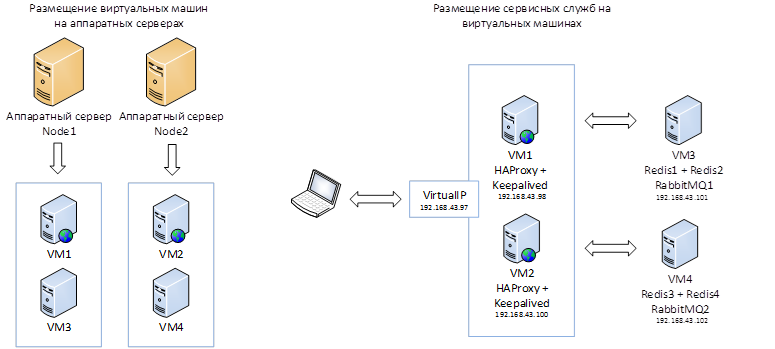
Для реализации простейшей отказоустойчивости требуется минимум два аппаратных узла, на которых будут размещаться виртуальные машины с сервисными службами. В случае выхода из строя одного из узлов сервисные службы должны быть доступны.
Для реализации кластера Redis рекомендуется использовать минимум 3 пары MASTER-SLAVE, в нашем случае будем использовать 4 пары, равномерно распределенные по 2 виртуальным машинам, которые в свою очередь размещены на двух разных физических серверах.
Сервисы RabbitMQ также должны размещаться на разных аппаратных узлах.
В рамках данного эксперимента примем допущение, что на всех виртуальных машинах в качестве ОС развернут дистрибутив ubuntu 18.04. Для других Linux настройка будет практически идентичной, могут отличаться некоторые команды, которые будут использоваться при развертывании, также могут отличаться расположения конфигурационных файлов сервисных служб.
Настройка HAProxy в режиме балансировки нагрузки
HAProxy - это специализированный инструмент, предназначенный для обеспечения высокой доступности и балансировки нагрузки, и используется повсеместно известными онлайн сервисами. Подробнее о HAProxy можно почитать на странице разработчика.
Установим HAProxy на узлы VM1 и VM2:
sudo apt install haproxy
В конфигурационные файлы на узлах HAProxy /etc/haproxy/haproxy.cfg, добавим настройки для проксирования запросов к узлам Redis и RabbitMQ (в том числе для Management Panel):
Блок настроек для Redis:
frontend ft_redis
bind *:6379 name redis
mode tcp
default_backend bk_redis
backend bk_redis
mode tcp
option tcp-check
tcp-check connect
# Если настроен доступ к узлам Redis по паролю, то дополнительно указываем пароль.
# tcp-check send AUTH\ TestPass\r\n
# tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
# Работаем только с MASTER, т.к. SLAVE по умолчанию работает только на чтение.
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
# Будем переключаться на следующий узел, если узел будет не доступен 2 секунды.
# Указываем порты MASTER-узлов Redis.
server Redis1 VM3:6381 check inter 2s
server Redis2 VM3:6382 check inter 2s
server Redis3 VM4:6383 check inter 2s
server Redis4 VM4:6384 check inter 2s
Блок настроек для RabbitMQ:
frontend ft_rabbitmq
bind *:5672 name rabbitmq
mode tcp
default_backend bk_rabbitmq
backend bk_rabbitmq
mode tcp
# Будем переключаться на следующий узел, если узел будет не доступен 2 секунды.
server RabbitMQ1 VM2:5672 check inter 2s
server RabbitMQ2 VM4:5672 check inter 2s
frontend ft_rabbitmq_management_panel
bind *:15672 name rabbitmq
mode tcp
default_backend bk_rabbitmq_management_panel
backend bk_rabbitmq_management_panel
mode tcp
# Будем переключаться на следующий узел, если узел будет не доступен 2 секунды.
server RabbitMQ1 VM3:15672 check inter 2s
server RabbitMQ2 VM4:15672 check inter 2s
Разворачиваем сервис Keepalived:
sudo apt install keepalived
По умолчанию конфигурационный файл keepalived отсутствует в папке сервиса. Необходимо его создать:
sudo nano /etc/keepalived/keepalived.conf
После чего занесем в конфигурационный файл на одном узле (на VM1 будет располагаться MASTER-узел):
vrrp_instance LVS_HAP {
# Указывает на то, в каком состоянии стартует текущий узел.
state MASTER
# Интерфейс для виртуального IP.
interface eth0
# Уникальное имя виртуального роутера.
virtual_router_id 97
# Приоритет данного узла перед остальными.
# Узел с наибольшим приоритетом переходит в состояние MASTER при старте.
# Пусть MASTER имеет приориет 2, а вспомогательный имеет приотритет 1.
priority 2
# Как часто происходит обновление состояния кластера.
advert_int 1
# Аутентификация. Используется для синхронизации между узлами.
authentication {
auth_type PASS
auth_pass HACLUSTER
}
# Виртуальный IP адрес.
virtual_ipaddress {
192.168.43.97
}
}
На другом узле (на VM2 будет располагаться SLAVE-узел):
vrrp_instance LVS_HAP {
# Указывает на то, в каком состоянии стартует текущий узел.
state SLAVE
# Интерфейс для виртуального IP.
interface eth0
# Уникальное имя виртуального роутера.
virtual_router_id 97
# Приоритет данного узла перед остальными.
# Узел с наибольшим приоритетом переходит в состояние MASTER при старте.
# Пусть MASTER имеет приориет 2, а вспомогательный имеет приотритет 1.
priority 1
# Как часто происходит обновление состояния кластера.
advert_int 1
# Аутентификация. Используется для синхронизации между узлами.
authentication {
auth_type PASS
auth_pass HACLUSTER
}
# Виртуальный IP адрес.
virtual_ipaddress {
192.168.43.97
}
}
Данные конфигурационные файлы отличаются настройками:
- state MASTER и state SALVE
- priority 2 и priority 1
После перезапуска служб Keepalived в сети появится виртуальный IP адрес, который будет привязан к MASTER-узлу.
Проверить подключенные к сетевому интерфейсу виртуальные адреса можно с помощью команды:
ip ad sh eth0
Результат корректного выполнения команды:
eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP gr oup default qlen 1000
link/ether XX:XX:XX:XX:XX:XX brd XX:XX:XX:XX:XX:XX
inet 192.168.43.98/18 brd XXXXXXXXX scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.43.97/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::215:5dff:fe12:1c5a/64 scope link
valid_lft forever preferred_lft forever
Где «inet 192.168.43.97/32 scope global eth0» - искомый виртуальный адрес.
Настройка отказоустойчивого HAProxy завершена.
Настройка кластера Redis
Настройка кластера Redis выполняется по инструкции представленной в статье Горизонтальное масштабирование и отказоустойчивость Redis для сервисных служб DirectumRX. Но есть ряд отличий.
Поскольку для корректной работы кластера Redis требуется не менее трех MASTER-реплик, для симметрии мы будем использовать два виртуальных узла и разместим на них четыре MASTER-реплики и четыре SLAVE-реплик:
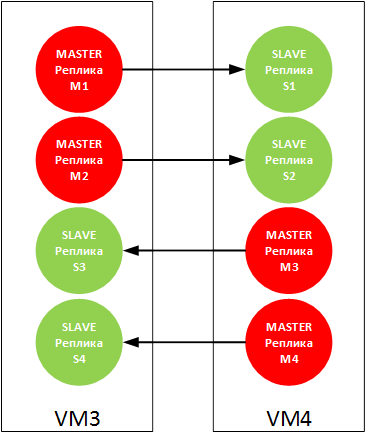
Для пары M1 – S1 будем использовать порт 6381
Для пары M2 – S2 будем использовать порт 6382
Для пары M3 – S3 будем использовать порт 6383
Для пары M4 – S4 будем использовать порт 6384
Итоговый скрипт создания кластера Redis:
redis-cli --cluster create VM3:6381 VM3:6382 VM3:6383 VM3:6384 VM4:6381 VM4:6382 VM4:6383 VM4:6384 --cluster-replicas 1
Настройка кластера RabbitMQ
RabbitMQ – это сервис, фактически реализующий шину для обмена сообщениями между внешними сервисами и приложениями по протоколу AMQP (Advanced Message Queuing Protocol). RabbitMQ реализован на языке Erlang. Процессы Erlang не имеют разделяемой памяти, все взаимодействия выполняются путем обмена сообщениями между процессами, что позволяет обмениваться данными как между различными ядрами, так и между несколькими компьютерами, объединенными в сети.
Проще говоря, уже «из коробки» RabbitMQ обладает возможностями масштабирования. Подключение узлов расширения фактически выполняется путем подключения новых узлов к первому.
Каждый узел кластера RabbitMQ будет иметь доступ ко всем очередям кластера и будет доступен как самостоятельный узел. Как и в случае с Redis, чтобы реализовать переключение на работающий узел также потребуется использовать HAProxy.
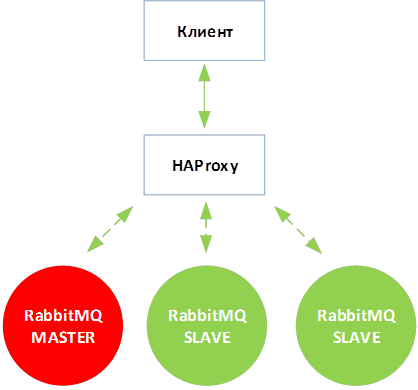
Для того, чтобы можно было подключить SLAVE-узлы к MASTER необходимо, чтобы файл /var/lib/rabbitmq/.erlang.cookie на всех подключаемых узлах был идентичный. В данном файле содержится уникальный ключ по которому процесс Erlang будет иметь доступ к процессам Erlang на других узлах.
Развернем RabbitMQ на узлах VM3 и VM4:
sudo apt install rabbitmq-server
Также на узлах развернем Management Panel для удобного управления кластером RabbitMQ:
sudo rabbitmq-plugins enable rabbitmq_management
Выполним копирование файла .erlang.cookie с узла VM3 на VM4:
sudo scp /var/lib/rabbitmq/.erlang.cookie VM4:/var/lib/rabbitmq/.erlang.cookie
После чего, перейдем на узел VM4 и выполним присоединение узла:
sudo rabbitmqctl stop_app # Остановить приложение RabbitMQ.
sudo rabbitmqctl reset # Сбросить процессы RabbitMQ.
sudo rabbitmqctl join_cluster rabbit@VM3 # Подключить узел VM4 к VM3
sudo rabbitmqctl start_app # Запустить приложение RabbitMQ.
Для проверки состояния кластера можно выполнить команду:
sudo rabbitmqctl cluster_status
Результат работы команды:
Cluster status of node rabbit@VM3 ...
[{nodes,[{disc,[rabbit@VM3,rabbit@VM4]}]},
{running_nodes,[rabbit@VM3]},
{cluster_name,<<"rabbit@VM3">>},
{partitions,[]}]
Также за состоянием кластера можно следить из веб-панели управления:

Заметим, что по умолчанию очередь будет создаваться и храниться только на одном из узлов. В случае выхода из строя какого-либо узлов, его (узла) очереди не будут доступны в кластере.
Для того, чтобы очереди перераспределялись по узлам необходимо настроить политику зеркалирования очередей HA-MODE:

Name – наименование политики.
Pattern – выбираем все очереди «.*»
Apply to – можно выбрать для каких сущностей будет доступно это правило, для агентов маршрутизации сообщений (Exchanges) или для очередей (Queues), в нашем случае выберем для всех.
Priority – выбираем минимальный приоритет (0), чтобы политика не влияла на какие-либо дополнительные политики. Максимальное значение 255. Чем больше число, тем выше приоритет.
Definition – определяет задаваемый параметр политики. Параметр «ha-mode» определяет зеркалирование очередей. Укажем значение параметра «all», чтобы зеркалирование выполнялось для всех очередей.
Данную операцию можно также выполнить из командной строки:
sudo rabbitmqctl set_policy HA ".*" '{"ha-mode": "all"}'
Настроенная на одном узле политика тут же применяется и на других узлах.
Настройка кластера RabbitMQ завершена.
Вместо заключения
После завершения настройки необходимо выполнить тестовые отключения узлов и убедиться, что сервисы остаются доступны, а при включении узлов настройки кластера автоматически восстанавливаются.
Дополнительные ссылки, которые могут быть полезны при выполнении настроек:
Redis
- Официальная инструкция по настройке кластера Redis.
- Информация на настройке периодичности снапшотов ключей Redis.
RabbitMQ
Keepalived
HAProxy
Подскажите , а каковы параметры требуемого железа в зависимости от скорости и размера поступающих пакетов ? Грубо насколько должны отличаться требования к RAM и CPU для пакетов в 100 кб поступающих со скоростью 1 шт\сек , 100 шт\сек и 10000 шт\сек ?
Подскажите пожалуйста, для чего в config.yaml указывать:
QUEUE_ADDITIONAL_HOSTS:
endpoint:
- '@hostName': 'test-test'
'@port': '5672'
- '@hostName': 'test-test'
'@port': '5672'
?
Если это явно указать нужен ли ha-proxy?
Я почему-то подумал, что это и есть балансировка, только со стороны RX
Ilja,
Авторизуйтесь, чтобы написать комментарий