Настройка приведения наименований фактов к единому виду в Directum Ario
Цель
Как показал опыт проектов Акелон, самым эффективным способом извлечения фактов является совместное использование правил и моделей.
Ниже на примере будет разобрано, как привести наименования извлеченных фактов от сервисов Learn и Rules к единому виду.
Процесс настройки для версии сервисов Ario 2020.10 и выше
Для настройки соответствия наименований фактов модели фактам правил необходимо:
- Перейти по пути fact_extraction/renamers/configs сервиса Fact Extractor Learn.
Пример пути для установленных сервисов Ario:
"C:\inetpub\Ario\FactExtractorServiceL\fact_extraction\renamers\configs".
- Создать файл с расширением ".json" и наименованием необходимого класса.
Имя класса должно быть на английском языке с заглавной буквы и совпадать с наименованием грамматики для класса документа. Пример для входящего письма: "Letter.json".
- Заполнить файл согласно структуре, описанной ниже.
- Перезапустить сервис Fact Extractor Learn.
Структура соответствия наименований фактов модели наименованиям фактов правил
- Верхнеуровневый объект - словарь, в котором:
- Ключ - наименование атрибута, используемого при разметке факта.
- Значения - словарь с ключами:
- "name". Значение - наименование факта, используемого при извлечении фактов с помощью текстовых правил.
- "rename_fields". Значение - словарь, в котором:
- Ключ - наименование атрибута, используемого при разметке факта.
- Значение - наименование поля факта "name", используемых при извлечении фактов с помощью текстовых правил.
- "add_fields" (необязательное). Значение словарь, в котором:
- Ключ - наименование дополнительного поля
- Значение - строковое значение дополнительного поля
Поле "add_fields" является необязательным. Как правило, оно используется для дополнительной типизации одноименных фактов.

Рис. 1. Пример структуры соответствия наименований для класса Letter.
Процесс настройки для версии сервисов Ario 2020.08 и Ario 2.0
Для настройки соответствия наименований фактов модели фактам правил необходимо:
- Перейти по пути formatters\grammar_formatter сервиса Fact Extractor Base.
Пример пути для установленных сервисов Ario:
"C:\inetpub\Ario\FactExtractorServiceL\fact_extraction\renamers\configs".
- Создать файл с расширением ".py".
Наименование файла может быть любым, но лучше придерживать стандарта наименования: {Наименование класса документа}_renamer_grammar_formatter.py
Пример: letter_renamer_grammar_formatter.py
- Разработать свой класс соответствия наименований.
- Указать данный класс, как изменяющий наименования фактов для моделей, в конфигурации сервиса.
- Перезапустить сервис Fact Extractor Base.
Подробнее о шагах 3 и 4 будет рассказано далее.
Разработка класса соответствия наименований
Откройте python файл с помощью любого текстового редактора. Первое, что необходимо сделать, это импортировать базовый класс, от которого будем наследоваться.
from formatters.grammar_formatters.renamer_grammar_formatter_base import RenamerGrammarFormatterBase
Теперь нужно разработать свой Python класс для соответствия наименований:
- Задать наименование: {Наименование класса документов}RenamerGrammarFormatter
- Отнаследоваться от базового класса
- Создать функцию инициализация класса и вызывать в ней инициализацию базового класса
- В функции инициализации для объекта класса (self) добавить свойство name_mapping и присвоить ему словарь, в котором:
- ключами являются имена фактов модели
- значениями должны быть кортежи (неизменяемые списки) с именем факта правила и его полем
- можно добавлять дополнительные поля, но при этом обязательно указывать их значение. Например, 'Type=signatory'.
Пример кода для класса документа Letter:
from formatters.grammar_formatters.renamer_grammar_formatter_base import RenamerGrammarFormatterBase
class LetterRenamerGrammarFormatter(RenamerGrammarFormatterBase):
def __init__(self):
super().__init__()
self.name_mapping = {
'NUMBER': ('Document', 'Number'),
'DATE': ('Document', 'Date'),
'SUBJECT': ('Document', 'Subject'),
'NUMBER_BASE': ('Letter', 'ResponseToNumber'),
'DATE_BASE': ('Letter', 'ResponseToDate'),
'CONFIDENTIAL': ('Letter', 'Confidential'),
'ADDRESSEE': ('Letter', 'Addressee'),
'CORRESPONDENT': ('Letter', 'CorrespondentName'),
'RECIPIENT': ('Letter', 'CorrespondentName', 'Type=recipient'),
'TIN_CORRESPONDENT': ('Counterparty', 'TIN'),
'TRRC_CORRESPONDENT': ('Counterparty', 'TRRC'),
'TIN_TRRC_CORRESPONDENT': ('Counterparty', 'TINTRRC'),
'SIGNATORY': ('LetterPerson', 'Name', 'Type=signatory'),
'RESPONSIBLE': ('LetterPerson', 'Name', 'Type=responsible'),
'PERSON_OTHER': ('LetterPerson', 'Name'),
'COUNTERPARTY': ('Counterparty', 'Name'),
'DATE_OTHER': ('OtherDate', 'OtherDate'),
}
Добавление своего класса в конфигурацию сервиса
Информацию о разработанном классе необходимо добавить в файл formatter.json, расположенному в корне папки сервиса Fact Extractor Base.
В данном файле находится список, в котором указаны 3 словаря. В самый первый словарь с "type": "grammar" в секции "formatters" для необходимого класса документа указать наименование своего разработанного класса соответствий наименований.
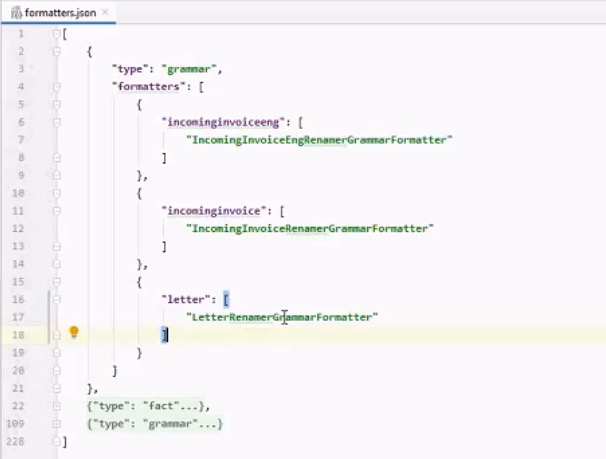
Рис. 2. Пример подключения форматера переименования для класса Letter в конфигурации сервиса Fact Extractor Base.
Авторизуйтесь, чтобы написать комментарий