Постобработка фактов в Directum Ario
Статья актуальна для версий сервисов Ario 2020.11-2021.02
Цель
Сервисы Directum Fact Extractor Learn и Rules извлекают значения фактов в том виде, в котором они явно представлены в извлеченном текстовом слое. Поэтому в результатах работы данных сервисов можно получить, например:
- даты в форматах: «21» января 2017, 21.03.2016;
- сумму документа прописью или числовое значение суммы;
- ИНН/КПП контрагента через дефис;
- несколько фактов, содержащих информацию об одном контрагенте.
Постобработка фактов позволяет:
- привести значения фактов к единому формату. Например, все даты возвращать в формате ДД.ММ.ГГГГ;
- разделить значение одного поля факта в разные поля этого же факта. Например, ИНН/КПП разделить по отдельным полям факта ИНН и КПП;
- позволяет исправить некорректно распознанные значения фактов. Например: «643рубль». В форматере формируется регулярное выражение, которое охватывает варианты некорректного распознавания текста, что позволяет привести исходный факт к правильному факту. В данном случае, «643».
- объединить значения нескольких фактов в один факт.
Постобработка пишется на языке Python. Реализуется класс, в котором уже описывается вся логика по постобработке фактов. Для удобства в дальнейшем будем называть такие классы форматтерами.
Виды постобработки фактов
В Directum Ario существует 2 вида постобработки фактов:
- По типу факта
- По типу грамматики
Постобработка по типу факта
Основной вид постобработки, который применяется ко всем фактам определенного типа, независимо от того, какая грамматика сработала или для какого класса документа происходит извлечение.
В данном виде постобработки не следует фильтровать или удалять значения полей фактов. Основная цель такого способа - это привести все поля факта к единому формату, который однозначно будет восприниматься информационной системой, в которую попадут данные от Directum Ario.
Приведение к единому формату также подразумевает и очищение извлеченные значений от лишних распознанных символов, которые не относятся к факту.
Например, извлеченные факты «21.01.2020-» и «21 января 2020» таким образом приводятся к одному виду: «21.01.2020»
Для того, чтобы написать свой форматтер для определенного типа факта, необходимо:
- Перейти в директорию formatters\fact_formatters сервиса Fact Extractor Service Base
Пример пути для установленных сервисов Ario: "C:\inetpub\Ario\FactExtractorService\formatters\fact_formatters"
- Создать python файл (с расширением ".py").
Наименование файла может быть любым, но лучше придерживать стандарта наименования:
{наименование факта}_{наименование поля факта}_formatter.py
Пример: "document_currency_formatter.py"
Если в файле будет описана постобработка сразу для всех полей факта, то {наименование поля факта} нужно опустить.
- Разработать python класс постобработки.
- Указать данный класс в конфигурации сервиса.
- Перезапустить сервис Fact Extractor Base.
Подробнее о шагах 3 и 4 будет рассказано далее.
Разработка форматтера по типу факта
Для разработки форматтера вам необходимы знания языка Python и понимание 3-х основных вещей:
- Наименование класса не важно, но лучше придерживаться стандарта:
{Наименование факта}{Наименование поля факта}Formatter
Пример: "DocumentCurrencyFormatter"
- Класс должен наследоваться от базового класса-форматтера. Перед этим данный класс необходимо импортировать:
from formatters.fact_formatters.fact_formatter_base import FactFormatterBase
- Вся логика постобработки описывается в методе
__call__.
Данный метод получает на вход 2 аргумента:
- self - объект вашего класса.
- fact - факт с результатами, для которого и применяется логика по постобработке.
Примечание. Для повышения читабельности вашего кода выносите большую по объему логику в отдельные методы.
Пример форматтера для постобработки поля Currency факта DocumentAmount:
"""Форматтер валюты суммы """
import re
from formatters.fact_formatters.fact_formatter_base import FactFormatterBase
class DocumentCurrencyFormatter(FactFormatterBase):
"""
Приведение валюты сумму к числовому коду
Валюта Код
руб 643
доллар 840
евро 978
йена 392
"""
def __init__(self):
super().__init__()
# код валюты: написание валюты
# буквы в большом регистре не используем, в форматере приводим строку к нижнему регистру
self.currency = {
'643': [
r'^[рp][yу][6бbоo]\.?$',
r'^[рp][yу][6бb][\.,][кk][оo0][пn][\.,]?$',
r'^[рp]\.?$',
r'^рубле[ий]\.?$',
r'^ру[б]?л[ья][х]?$',
r'^ru[br]$',
r'^[pр]осс[иы][йи]ский ру[б6оo]л[ьъ]\.?$',
r'^[pр]осси[йи]ский$',
r'^[yу6s]{2}\.?',
r'^[рp][yу][g]nen'
],
'840': [
r'[\$]',
r'^usd$',
r'^доллар$',
r'^доллар сша$',
r'^дол\.?$'
],
'978': [
'^евро;?$'
],
'392': [
'^jpy'
]
}
def __call__(self, fact):
currency_field = self.get_fact_field(fact, 'Currency')
if currency_field is not None:
for currency_code in self.currency.keys():
stop_flag = False
for pattern in self.currency[currency_code]:
pattern_obj = re.compile(pattern)
# проверяем currency_field.value, т.к. ранее был применен CleanValueFormatter
currency_field.value = pattern_obj.sub(currency_code, currency_field.value.lower())
if currency_field.value == currency_code:
stop_flag = True
break
if stop_flag:
break
Добавление форматтера в конфигурацию сервиса
После разработки форматтера остается только указать его в конфигурации сервиса:
- Переходим в основную директорию сервиса Fact Extractor Base
Пример пути для установленных сервисов Ario: "C:\inetpub\Ario\FactExtractorService"
- Отрываем файл
formatters.json - Находим в конфигурации секцию с типом "fact", находим список форматтеров для нашего факта и добавляем наименование разработанного класса в данный список.
- Сохраняем файл и перезагружаем службу сервиса. Готово.
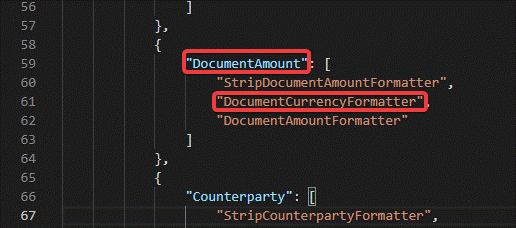
Рис. 1. Пример добавления класса DocumentCurrencyFormatter для факта DocumentAmount.
Постобработка по типу грамматики
Данный вид постобработки применяется ко всем фактам, извлеченным для определенной грамматики. Основная цель - применить необходимую бизнес-логику на обработку извлеченных фактов. Примером может быть фильтрация/удаление значений тех полей фактов, которые по определенным причинам не должны попасть в конечную информационную систему.
Следует понимать, что постобработка по типу грамматики срабатывают после постобработки по типу факта. Благодаря этому при разработке форматтера для грамматик можно быть уверенным, что данные вам пришли уже в определенном формате.
Разработка форматтера по типу грамматики очень схожа с разработкой по типу факта. Далее представлен краткий алгоритм с описанием основных отличий между данными процессами:
- Создайте python файл в директории formatters\grammar_formatters сервиса Fact Extractor Base
Наименование файла: {наименование факта}_{наименование поля факта}_grammar_formatter.py
- Разработайте python класс постобработки.
- Укажите данный класс в конфигурации грамматики.
- Перезапустите сервис Fact Extractor Base.
Разработка форматтера по типу грамматики
- Наименование: {Наименование факта}{Наименование поля факта}GrammarFormatter
- Импорт базового класса и наследование от него
from formatters.formatter_base import FormatterBase
- Вся логика постобработки также описывается в методе
__call__, но вместо аргумента fact на вход подается аргумент facts, который содержит данные по всем фактам и их полям, которые были извлечены данной грамматикой.
Пример форматтера для удаления пустых значений поля Number факта Document, применяемый для множества грамматик:
"""Форматтер правил номера документа."""
from formatters.formatter_base import FormatterBase
class DocumentNumberGrammarFormatter(FormatterBase):
def __call__(self, facts):
self.facts = facts
self.process_document_number()
return self.facts
def process_document_number(self):
facts = []
# Список всех простых номеров
for fact in self.facts:
field = self.get_fact_field_by_type(fact, 'Number')
if field is not None:
facts.append(fact)
for fact in facts:
fields = self.get_fact_fields_by_type(fact, 'Number')
for field in fields:
if field.value is None or len(field.value) == 0:
fact.fields.remove(field)
if len(fact.fields) == 0:
self.facts.remove(fact)
return
Добавление форматтера в конфигурацию грамматики
Для добавления разработанного форматтера в конфигурацию грамматики:
- Перейдите в директорию grammar сервиса Fact Extractor Base
- Перейдите в директорию грамматики, для которой необходимо добавить форматтер
- В файл
formatters.jsonдобавляем наименование разработанного класса - Сохраняем файл и перезагружаем сервис Fact Extractor Base. Готово.
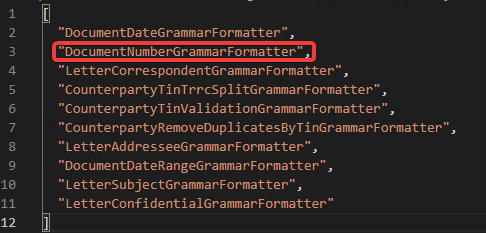
Рис. 2. Пример добавления класса DocumentNumberGrammarFormatter для грамматики Letter.
Авторизуйтесь, чтобы написать комментарий