Приручаем Elasticsearch
Данная статья будет полезна тем, кто задумался о программном использовании полнотекстового поиска напрямую, например для сложных кастомных запросов по нестандартным полям. Ну или для тех, кто захотел попробовать написать свой вариант полнотекстового поиска.
При прочтении данной статьи рекомендую заранее вооружиться доступным и работающим Elasticsearch и пользоваться им во время прочтения.
Вода и предыстория
Однажды заказчик рассказал, что они внутри компании очень любят и активно используют полнотекстовый поиск и хотели бы видеть нечто подобное в модуле нормативных документов. В таком случае поиск этот должен искать заданную пользователем фразу в тексте или карточке документа в разрезе определённых типов и видов документов. И мы задались вопросом: «А можно так???».
Механизмы объектной модели D5 не позволяли в полной мере реализовать преимущества полнотекста. Например, мы с вами можем указать в критериях поиска ISearchCriterion реквизит «Наименование» или «Примечание» или любой другой строковый реквизит со строковым типом. И поиск в таком случае будет осуществляться без использования словоформ. В критериях поиска фабрики поисков для полнотекстового поиска доступны только поля с типом текст.
Тогда я решил посмотреть в сторону Elasticsearch и его прямой эксплуатации на благо решения нашей задачки.
Elasticsearch термины и структура
С версии Directum 5.6 для полнотекстового поиска стал использоваться движок Elasticsearch (далее – ES)– популярная (в том числе в области Big Data) поисковая система с открытым исходным кодом, любимая и почитаемая многими за свою скорость и гибкость. ES поддерживает сложные агрегации, геофильтры и т.д. На данный момент она же используется и в Directum RX, что не удивительно, на самом деле.
Немного о терминах и структуре, дабы понимать, о чём будет речь далее. Это очень важно, т.к. термины в целом знакомые, но в смежных областях означают немного другое.
Основные термины
Проще всего основные термины объяснить проводя аналогии с базами данных. Ниже приведена таблица с аналогичными терминами из, наверняка, знакомого вам SQL.
|
SQL |
Elasticsearch |
|
База данных |
Индекс |
|
Таблица |
Тип |
|
Строка |
Документ |
|
Колонка/поле |
Поле |
|
Схема таблицы/БД |
маппинг |
* Начиная c 6-й версии ES у индекса может быть только один тип.
Структура и хранение
В Elasticsearch данные хранятся в виде документов JSON, причём поддерживается хранение вложенных объектов. Пример структуры документа:
{
"id": 1,
"name": "Фёдор",
"age": 75,
"email": "fedor@gmail.com",
"address": {
"street": "1Qwerty",
"city": "Cry City"
},
"phones":[
"123-956-45-45",
"112"
]
}
Кстати, элементы "id", "name" и т.д. это и есть ни что иное, как название полей документов.
Mapping
Так же вам будет встречаться такой термин, как Mapping, по-другому его ещё можно назвать схемой. По сути mapping определяет в каком виде будет хранится документ(структура и типы полей), и каким образом он индексируется. Здесь же можно указать анализаторы и дефолтные значения и т.д.
«_»
Полезно будет понимание того, что все свойства, и ключи, начинающиеся со знака «_» являются системными. Например поле _id, которое есть у каждого документа или поле _type – ни что иное, как его тип, или url-ключ _search, который задаёт API поиска(реализует поиск).
Основной способ взаимодействия с Elasticsearch — REST API. По умолчанию API —интерфейс Elasticsearch работает на порту 9200. Api Elasticsearch можно классифицировать на следующие виды:
- API документов: CRUD (Create Retrieve Update Delete) операции с документами
- API поиска: поиск чего бы то ни было
- API Индексов: управление индексами (создание, удаление …)
- API Cat: вместо JSON данных возвращаются в табличном виде
- API кластера: для управления кластером
Нас же будет интересовать API поиска и API Индексов.
Запросы
Начнём с простого. Так как это REST API нам понадобится браузер с любым расширением для работы с http запросами, либо Postman.
В postman для тела используем следующие настройки:

Во-первых, проверим, строку подключения. В Directum 5 её можно найти в константе ESServerURL (В моём случае это http://localhost:9200).
Проверка доступа осуществляется с помощью простого http запроса по тому же адресу. Если коннект налажен, то мы должны получить примерно следующее:
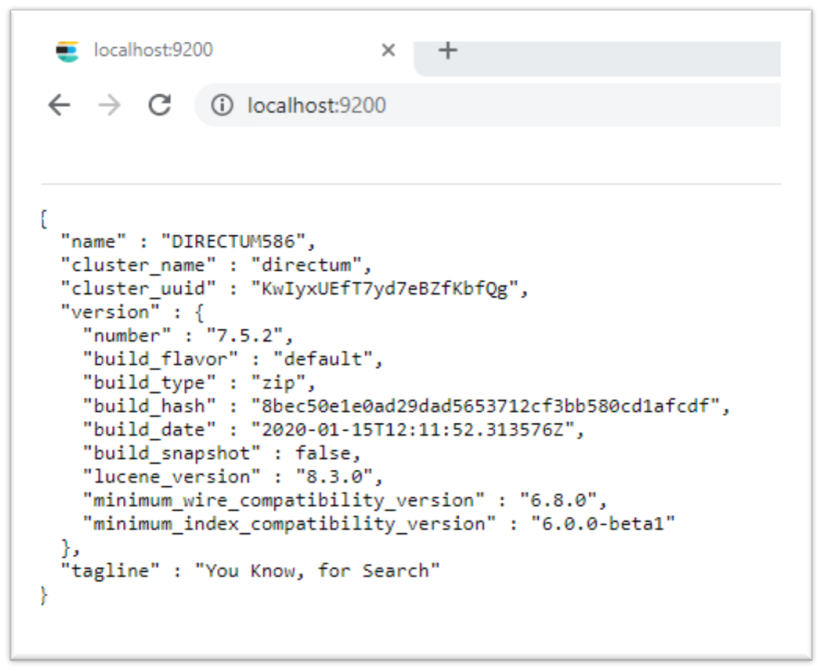
О доступе стоит поговорить отдельно, ведь для D5 это порождает некоторые проблемы.
Согласно справке для ES настраивается безопасный доступ, что означает, что у простых пользователей прямого доступа к API не будет. И это правильно, ведь движок не в курсе прав доступа на те или иные документы и без разбора может выдать тексты документов тем пользователям, у которых на это нет прав, но это касается лишь «Продвинутой» части пользователей, способной писать и слать запросы.
Так. Что вариантов решения этой проблемы мне на ум приходит всего 2:
- Ослабление политики безопасности доступа к ES, что не очень приемлемо, но в ряде случаев не критично;
- Выполнять запросы на сервере (через серверные события или задачу), а результаты пользователю отправлять задачей.
В RX же проблема должна решаться серверными функциями.
Возможно, кто-то сможет придумать, как договориться со службой поиска, чтобы через неё отправлять свои запросы.
Когда необходимо выполнить поиск, используется HTTP-запрос к _search Api. Индекс и тип, по которому должен выполняться запрос, указывается в URL-адресе. Индекс и тип являются необязательными. Если индекс и тип не указаны, Elasticsearch выполняет запрос по всем индексам в кластере. Поисковый запрос в ES может быть выполнен двумя разными способами:
- Передавая запрос поиска в качестве параметров запроса.
- Передавая запрос поиска в теле запроса.
Простые запросы
Самый простой запрос, возвращающий результаты поиска по слову «Фёдор», будет выглядеть так:
http://localhost:9200/_search/?q=Фёдор
Данный запрос будет искать по всем полям всех индексов и всех типов документов, короче везде.
Запрос более точечный, для поиска среди конкретных индексов и типов будет выглядеть следующим образом:
http://localhost:9200/dir_document_versions,dir_document_versions_ru/ _doc/_search/?q=Фёдор
Этот запрос уже ищет не по всем индексам, но всё ещё продолжает искать по всем полям документов. Рассмотрим запрос, где нам необходимо найти совпадения по определённым полям карточки, или только в тексте документа:
http://localhost:9200/dir_document_versions/_search/?q=content:Фёдор
Здесь уже совпадения будут искаться только среди поля content. в D5 это поле содержит текст тела документа.
Ответы
Мы поговорили о запросах, а что же с ответами? Если после выполнения запроса вам пришёл ответ со статусом 200, то запрос вы составили корректно. Вне зависимости от того, нашлось ли что-то по вашему запросу, или нет вы получите ответ в виде json’а.
Ниже приведён слегка упрощённый (урезанный в плане полей) пример ответа:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.1208954,
"hits": [
{
"_index": "dir_document_versions",
"_type": "_doc",
"_id": "163098_1",
"_score": 3.1208954,
"_source": {
"extension": "TXT",
"is_hidden": false,
"…": "…"
}
]
}
}
Если по вашему запросу ничего не найдётся, то свойство hits будет пустым т.е.
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 6,
"successful": 6,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.1208954,
"hits": []
}
}
Описание структуры ответа:
{
"took" : // Время потраченное на получение данных
"timed_out": // Был ли превышен тайм-аут, если он был задан для запроса.
"_shards": {
"total": // Количество осколков задействованных при запросе
"successful": // Количество осколков вернувших успешный результат
"failed": // Количество осколков с ошибкой
},
"hits": {
"total": // Общее количество документов
"max_score": // Максимальный балл всех документов
"hits": [
// Список документов
]
}
}
В основном в json ответа нас будет интересовать свойство hits. Именно оно и содержит всю информацию о найденных по нашему запросу документах в виде массива объектов.
* По умолчанию свойство hits.hits: [] будет содержать не больше 10 элементов (документов)! При этом значение в свойстве hits.total может иметь значение больше 10.
Перейдем к сложными запросам, потому что, ну а толку нам от простых-то?)
Но сначала…
Где взять индексы и поля?
Это вполне логичный вопрос, раз мы вплотную подошли к сложным запросам, ведь нам точно нужно знать и понимать какие поля указывать и что там вообще хранится.
Индексы
Для получения индексов очень удобно использовать следующий запрос:
http://localhost:9200/_cat/indices
В ES для D5 я получил следующий результат:
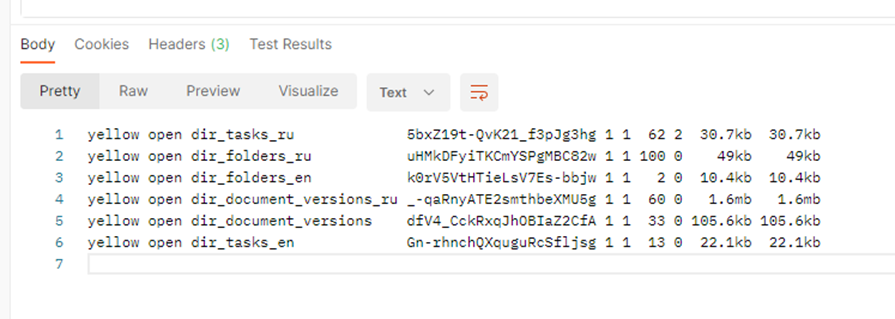
В этом случае параметр _cat позволил получить результаты в виде красивенькой таблички.
К сожалению, это пока что для меня это единственный запрос, работающий с параметром _cat.
Собственно наименования индексов находятся в третьей колонке, а четвёртой их uuid.
На всякий случай, выделю полученные имена индексов:
|
dir_tasks_ru |
|
dir_folders_ru |
|
dir_document_versions_ru |
|
dir_folders_en |
|
dir_document_versions |
|
dir_tasks_en |
Отличий между индексами dir_document_versions и dir_document_versions_ru я так и не нашёл. Тем не менее в моей системе есть документы как с одним, так и с другим индексом не зависимо от того, на каком языке содержимое документа. Возможно, индексы *_ru используются там, где тело документа хранится в кодировке windows-1251. Этот вопрос потребует более детальной проработки. Названия индексов вполне себе интуитивно понятны, поэтому расшифровывать их не вижу смысла.
Поля
Такс, индексы мы получили, теперь неплохо было бы узнать поля, не так ли? В этом нам, как раз поможет mapping.
Следующий запрос вернёт схемы всех индексов
http://localhost:9200/_mapping
Поскольку такой запрос вернёт схемы всех индексов результат данного запроса будет страшно большим. Рекомендую смотреть маппинг отдельных индексов, тем более что индексы мы уже знаем. Даже не просите прикладывать результат всего ответа на этот запрос…
http://localhost:9200/dir_document_versions_ru/_mapping
И даже здесь весь результат выкладывать не буду, приложу урезанную схему:
{
"dir_document_versions_ru": {
"mappings": {
"dynamic_templates": [...],
"properties": {
"archive_tag": {
"type": "boolean"
},
"author_value_id": {
"type": "keyword"
},
"card": {
"properties": {
"card_type_value_id": {
"type": "keyword"
},
"d0": {
"properties": {
"createdate_date": {
"type": "date",
"format": "dd.MM.yyyy HH:mm:ss||dd.MM.yyyy HH:mm||dd.MM.yyyy"
}
}
}
}
},
"content": {
"type": "text",
"term_vector": "with_positions_offsets",
"fields": {
"exact": {
"type": "text",
"analyzer": "default",
"search_analyzer": "exact_search_analyzer",
"search_quote_analyzer": "standard"
}
},
"analyzer": "ru_en_analyzer",
"search_analyzer": "search_analyzer",
"search_quote_analyzer": "standard"
}
}
}
}
}
Интересующие нас поля содержатся в свойстве properties.
Например archive_tag, author_value_id, content и есть наши искомые поля индекса dir_document_versions_ru.
Типы полей указаны в свойстве type для каждого поля из блока Properties.
Описание всех типов, поддерживаемых ES есть в этой статье.
Важно понимать, что для полнотекстового поиска используются поля с типом text. Данные в полях с типом keyword, будут искаться по точному совпадению.
Обратите внимание, что поле card составное, поэтому его использование как поле для поиска напрямую не даст результатов. Но есть возможность искать по его дочерним полям, указывая их через точку. Например:
{
"query": {
"match": {
"card.name" : "Фёдор"
}
}
}
card.name в D5 соответствует наименованию документа.
Но проще всего оценить структуру и содержимое документа выполнив прямой запрос на конкретный документ. Получим документ с ид 163098.
http://localhost:9200/_search?q=id:163098
В ответе можно будет увидеть примерно следующее:
"hits": [
{
"_index": "dir_document_versions",
"_type": "_doc",
"_id": "163098_1",
"_score": 3.1208954,
"_source": {
"extension": "TXT",
"is_hidden": false,
"edition": 5,
"access_count": 1,
"language": "uk",
"signature_type_value_id": "0",
"archive_tag": false,
"content": "Иванов Фёдор Иванович",
"content_type": "text/plain; charset=windows-1251",
"storage_id": 163085,
"rights": [
103576
],
"id": 163098,
"author_value_id": 103576,
"editor_value_id": 44866,
"content_length": 27,
"modified_date": "09.06.2022 19:06:22",
"life_stage_value_id": "Д",
"size": 26,
"card": {
"d0.kind_value_id": [
115045
],
"d0.modifydate_date": [
"09.06.2022 19:06:22"
],
"d0.note_text": [
"Fedor - Иванов Фёдор Иванович"
],
"name": "Новый текстовый документ",
"d0.editor_value_id": [
44866
],
"kind_value_id": 115045,
"d0.createdate_date": [
"09.06.2022 19:05:49"
],
"card_type_value_id": 3141,
"author_value_id": 103576,
"life_stage_value_id": "2"
},
"since": "09.06.2022 19:06:25"
}
В результате этого запроса мы можем найти системное свойство _source, которое как раз и содержит перечень полей документа и их значения.
*При поиске по полям нужно учитывать регистр! Т.е. результат запроса:
http://localhost:9200/_search?q=iD:163098
будет пустым т.к. у нас есть поле id, но нет поля iD.
Ну что ж. теперь мы знаем наши индексы и наши поля и можем приступать к более сложным запросам!
Сложные запросы
Мы рассмотрели способы поиска через параметры запроса, однако такой способ подойдёт только для простых запросов. Для более сложных нам понадобится указывать необходимые нам условия в теле запроса. Здесь уже не обойтись без postman или расширений. Я буду использовать postman.
Для начала рассмотрим простой запрос, аналогичный предыдущему из простых.
http://localhost:9200/dir_document_versions/_search
Тело запроса:
{
"query": {
"match": {
"content" : "Фёдор"
}
}
}
Структура json тела запроса:
{
"size" : // Количество документов в ответе. По умолчанию 10.
"from" : // Смещение результатов
"timeout" : // Тайм-аут запроса. По умолчанию его нет.
"_source" : // Поля которые попадут в ответ.
"query" : { // Запрос }
"aggs" : { // Агрегация }
"sort" : { // Сортировка результата }
}
Для начала подробнее о запросах "query":{}
Типы запросов и их применение или, что пишем внутри query?
В следующих примерах я буду опускать строку запроса, т.к. везде мы будем использовать одну и ту же:
http://localhost:9200/_search/
Мы уже знакомы с простеньким запросом полнотекстового поиска по полю card.name
Match
{
"query": {
"match": {
"card.name" : "Фёдор"
}
}
}
Match указывает на то, что нам нужно искать совпадения в указанном поле по указанной строке.
multi_match
Поиск по нескольким полям. Сам по себе Match указывает на необходимость поиска среди конкретного поля, но что, если нам необходимо искать среди нескольких полей? Match так не умеет, а вот multi_match запросто! Для этого в свойстве fields нужно перечислить список полей, где мы хотим выполнять поиск.
{
"query": {
"multi_match": {
"query": "Фёдор",
"fields": [
"card.name",
"content"
]
}
}
}
* В таких запросах по умолчанию значение для поля _score будет выбираться по лучшему результату из указанных полей (в режиме best_fields).
Вообще, просто, что бы вы знали, есть и другие способы вычисления _score и с этим можно поиграться, но, пожалуй, оставлю это вам на самостоятельное изучение, потому что для наших задач это будет излишне.
match_phrase
Обычный match разбивает запрос на слова и производит поиск по каждому слову в отдельности. Когда вам важен порядок слов вам нужно использовать match_phrase.
{
"query": {
"match_phrase": {
"content": "основной документ"
}
}
}
Если вы допускаете, что между словами может быть несколько любых других слов, укажите их допустимое количество в поле "slop": <n>
{
"query": {
"match_phrase": {
"content": {
"query": "основной документ",
"slop": 1
}
}
}
}
Например, такой запрос вернёт документ в тексте которого есть фраза «… основного нормативного документа …».
match_all и match_none
Один из них возвращает все документы, а второй – никакие. Надеюсь, не нужно пояснять, какой из них что возвращает? Такие запросы мне редко встречались на просторах интернета и, скорее всего, из-за того, что реальное практическое применение они имеют лишь в некоторых сложных логических запросах. Во всяком случае вы будете знать, что такая возможность существует. На практике запросы выглядят так:
{
"query": {
"match_all": {}
}
}
И так:
{
"query": {
"match_none": {}
}
}
Внутри "match_all" можно ещё прописать увеличение значения для параметра _score:
{
"query": {
"match_all": {"boost":3.2}
}
}
Вот данный запрос, например, увеличит всем полученным документам значение _score в 3.2. раза. По умолчанию _score = 1.0(это при использовании "match_all")
Term
{
"query": {
"term": {
"id" : 163098
}
}
}
Term – поначалу рекомендую его использовать для запроса чисел, бинарных значений, дат. Проще говоря для поиска по точному значению или для фильтрации по ID. Данный запрос используется для поиска одного термина в инвертированном индексе. В следствие чего поиск по тексту может быть не так очевиден, как могло бы показаться на первый взгляд. Приведу пример.
Есть у меня документ с полем "card":{"name": "Новый текстовый документ", …}
Такой запрос как:
{
"query": {
"term": {
"card.name" : "Новому"
}
}
}
Не вернёт мне данный документ. В то время, как подобный match запрос, вполне себе справится с этой задачей:
{
"query": {
"match": {
"card.name": "Новому"
}
}
}
Документ я смогу получить с помощью term только в том случае, если я буду указывать всё слово целиком и только в нижнем регистре. Т.е. "новый" или "текстовый" или "документ" – позволят получить этот документ. Так же этот документ мне не вернётся если целиком указать всё наименование, т.к. оно состоит из нескольких слов.
terms
{
"query": {
"terms": {
"id" : [103485, 163099]
}
}
}
Чтобы запросить более одного термина, мы должны использовать запрос терминов "terms". Если документ соответствует любому из условий, он попадает в результат.
Выше приведён пример запроса документа с id равным 103485, или 163099.
query_string
Этот тип запроса поддерживает Lucene синтаксис, который позволяет и нам и пользователю создавать сложные запросы в google-style.
{
"query": {
"query_string": {
"fields": [
"card.name^3",
"content^2"
],
"query": "Документ"
}
}
}
Расшифрую запрос: для поиска будут использоваться поля card.name и content. Искать будем по значению Документ. Вот эти символы в конце полей: ^3 и ^2 означают boost для значения _score в результате запроса. Т.е. за совпадения искомого в поле card.name очки _score будут увеличены в 3 раза, а для совпадения в поле content очки увеличатся в 2 раза.
Или вот такой запрос:
{
"query": {
"query_string": {
"query": "card.\\*:(Фёдор OR Документ)"
}
}
}
Этим запросом мы будем искать значения полей в карточке(то есть все поля, начинающиеся с "card.") соответствующим значению Фёдор, либо значению Документ.
Если не указывать fields и в query не указывать поле, по которому нужно искать, то поиск будет производиться по всем полям:
{
"query": {
"query_string": {
"query": "документ"
}
}
Данный запрос вернёт все документы, где в полях упоминается документ
*В интернете вы можете найти упоминание волшебного поля _all которые можно использовать для поиска по всем полям, но с версии 6.0 оно удалено.
Я очень долго не понимал, почему у меня при поиске по нему ничего не находит, пока умные люди не подсказали. По крайней мере в D5 его точно нет – просто знайте.
Т.е. запросы
{
"query": {
"match": {
"_all":"документ"
}
}
}
И
{
"query": {
"query_string": {
"query":"_all:документ"
}
}
}
Будут возвращать вам пустой результат.
Range
{
"query": {
"range": {
"id": {
"gte": 1000,
"lte": 5000000
}
}
}
}
Range, подобно between, рассчитан на диапазон. Удобен при работе с датами. Ниже приведена таблица с разъяснением полей этого типа запроса привычными нам символами сравнения.
|
Поле |
Значение |
Расшифровка аббревиатуры |
|
gt |
> |
Greater than |
|
gte |
>= |
Greater than or equal to |
|
lt |
< |
Less than |
|
lte |
<= |
Less than or equal to |
Т.е. запросом из примера мы отбирали все документы id которых находилось в диапазоне от 1000 и до 5000000
Bool
Используется для объединения запросов. Т.е. мы можем использовать два match вместо multi_match. Именно эта штука позволяет комбинировать все описанные ранее запросы! Покажу на примере:
{
"query": {
"bool": {
"should": [
{
"match": {
"card.name": "Фёдор"
}
},
{
"match": {
"content": "Фёдор"
}
}
]
}
}
}
should – указывает на то, что в результате нас устроит совпадение с одним из полей. Когда нужно, что бы в результат попадали только те документы, у которых имеются совпадения по всем условиям внутри bool, то мы должны указать must. А если есть необходимость исключить документы с определенными условиями то указываем must_not.
Если проще, то:
- should = "or"
- must = "and"
- must_not = "not"
Bool может иметь под запросы bool. Базовая структура запроса bool выглядит следующим образом:
{
"query": {
"bool": {
"must": [],
"must_not": [],
"should": [],
"filter": []
}
}
}
По умолчанию Bool для расчета итогового балла _score добавляются оценки всех запросов.
А что ещё есть по мимо разновидностей query?
Filter
{
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "Предмет договора"
}
}
],
"filter": [
{
"term": {
"card.card_type_value_id": 3283
}
}
]
}
}
}
Очевидно, такой запрос как filter, фильтрует набор данных по указанным параметрам. В данном случаем мы фильтруем через запрос term по полю соответствующему id типа карточки документа. Т.е. Данным запросом мы ищем совпадения во всех полях по строке Предмет договора, но только среди типов документов с id = 3283.
Одна из особенностей Filter является в том, что результаты его фильтрации не учитываются для поля _score. Что в нам в данном запросе не нужно и, кроме того, ускоряет поиск в целом.
Тут можно было бы закончить, ведь искомый мной запрос, который бы решил задачу заказчика найден, но… есть один нюанс, о котором стоит рассказать.
from и size
{
"from": 0,
"size": 10,
"query": {
"query_string": {
"query": "Документ"
}
}
}
Если вы уже забыли, что по умолчанию вам будет возвращаться не больше 10 документов, то возможно вы уже бьётесь в истерике от непонимания «Да почему 10 то??? Value же = 51!».
А всё по тому, что Elasticsearch бережно делит результат на страницы для оптимизации. Отличным примером этого механизма подойдёт поисковик гугл, где на вторую и третью страницу поиска переходят крайне редко. Уже уловили связь?
Size как раз и показывает количество документов на «странице», а поле from означает с какого по счёту документа, начнётся наша страница результата. Счёт страниц начинается с 0. Мы можем начать с третьего по счёту документа! И тогда наш запрос будет выглядеть следующим образом:
{
"from": 2,
"size": 10,
"query": {
"query_string": {
"query": "Документ"
}
}
}
Напоминаю вам, что по умолчанию порядок документов в результате определяется значением поля _score(очки релевантности). От большего значение к меньшему.
И раз уж мы заговорили о порядке перечисления документов…
Sort
{
"from": 0,
"size": 500,
"query": {
"query_string": {
"query": "Документ"
}
},
"sort":{
"modified_date":{
"order": "desc"
}
}
}
Не трудно догадаться, что с помощью Sort мы определяем порядок документов. Это важно, учитывая особенности работы представления результатов в виде отдельных блоков, именуемых страницами.
Так же сортировать можно сразу по нескольким полям:
{
"from": 0,
"size": 500,
"query": {
"query_string": {
"query": "Документ"
}
},
"sort": [
{
"author_value_id": {
"order": "desc"
}
},
{
"modified_date": {
"order": "desc"
}
}
]
}
При сортировке с использованием нескольких полей результаты сначала сортируются по первому полю, а затем по другим полям. Если значение первого поля уникальны, следующие поля не будет иметь эффекта. Только если два или более документов имеют одно и то же значение первого поля, второе поле будет использоваться для сортировки.
_source
{
"_source":[
"id",
"author_value_id"
],
"query": {
"query_string": {
"query": "Документ"
}
}
}
По умолчанию в полученном результате каждый документ, содержащийся в массиве hits[] в поле _source будет иметь перечень всех полей документа. Подозреваю, что прям все поля для нас будут избыточны, поэтому можно указать, какие поля документов мы хотим получить. Выше предоставлен пример запроса, в котором указывается, что в результате должны содержаться поля "id" и "author_value_id". Документ в ответе будет выглядеть следующим образом:
"hits": [
{
"_index": "dir_document_versions_ru",
"_type": "_doc",
"_id": "103479_1",
"_score": 5.42464,
"_source": {
"id": 103479,
"author_value_id": 103576
}
},
…]
Поле _source также поддерживает подстановочные знаки для имен полей. Мы можем с помощью символа * указать Elasticsearch что нам нужно в результате в _source включить поля, которые начинаются с «e…» и все дочерние элементы «card.», как показано здесь:
{
"_source":[
"card.*",
"e*"
],
"query": {
"query_string": {
"query": "Документ"
}
}
}
Результат вы можете посмотреть сами.
Как же всё-таки с этим работать из Directum 5?
Ответ: просто! В D5 уже есть готовая функция ESExecuteRequest()
Покажу на примере:
method = 'POST'
indexis = CreateStringList()
indexis.Delimiter = ','
indexis.Add('dir_document_versions_ru')
indexis.Add('dir_document_versions')
API = '_search'
queryBody = '{
"_source": [
"id"
],
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "договор"
}
}
],
"filter": [
{
"term": {
"card.card_type_value_id": 3283
}
}
]
}
}
}'
SearchRes = ESExecuteRequest(method; indexis.DelimitedText; API;; queryBody)
DocsInRes = JSONToObject(SearchRes)
DocsCount = DocsInRes.hits.hits.length
docIds = CreateStringList()
docIds.Delimiter = ','
I = 0
while I < DocsCount
hit = JSONToObject(SearchRes & Format('.hits.hits[%s]'; I))// DocsInRes.hits.hits[I] не работает т.к. массивы JS и ISBL отличаются.
docIds.add(hit._source.id)
I = I + 1
endwhile
ShowMessage(docIds.DelimitedText)
В D5 есть и другие функции и сценарии по работе с ES. Все они бережно собраны в группу функций «SearchEngine» - рекомендую к просмотру.
Думаю, на этом пора заканчивать.
Заключение
Надеюсь, для вас это было интересно и полезно. И как минимум, ваши познания в области полнотекстового поиска расширились.
Вообще кейс с точечным полнотекстовым поиском, наверное, крайне непопулярный и реализуется на каком-нибудь проекте с малой долей вероятности. Но зато теперь и ваши границы понимания возможностей кастомизации системы расширены.
Elasticsearch очень огромный по своим механикам, и я лишь поведал вам о том, что как мне показалось, было бы полезным именно в совокупности с Directum. Я ни в коем случае, не претендую на роль магистра наук по ES, ведь сам эту тему начал изучать недавно. И по сути своей данная статья является структурированным сборником моих заметок, которые собирались в процессе изучения. Дерзайте дальше. Надеюсь, я помог вам влиться в эту тему!)
P.S.
Сейчас у меня появилась мысль по организации полнотекстового поиска для записей справочника и возможно мысль внезапно материализуется, но это уже другая история.
Самая понятная статья с описанием и примерами, в которых использовано актуальное API Elasticsearch (8.9.0) из тех, что удалось найти за последние дни. Для старта - самое оно. Спасибо!
топчик, спасибо
Авторизуйтесь, чтобы написать комментарий