Выполнение запросов в PostgreSQL
Статья будет полезна начинающим разработчикам. Рассматривается внутреннее устройство PostgreSQL. Ниже описана общая картина выполнения запросов в СУБД, а также рассматриваются инструменты профилирования запросов.
Подготовка тестовых данных
Для начала создадим таблицы, к которым будем строить запросы в дальнейшем.
CREATE TABLE Regions
(
Id SERIAL PRIMARY KEY,
Name CHARACTER VARYING(30)
);
CREATE TABLE Cities
(
Id Serial Primary KEY,
Name CHARACTER VARYING(50),
RegionId INTEGER REFERENCES Regions (Id)
);
Опустим запросы наполнения таблиц данными, будем считать, что в каждой таблице есть по несколько строк записей.
Создадим представление Locations на основе таблиц Regions и Cities:
CREATE OR REPLACE VIEW Locations AS
SELECT
Cities.Id as CityID,
Cities.Name as CityName,
Regions.Name AS RegionName
FROM Cities
LEFT JOIN Regions
ON Cities.Id = Regions.Id;
Простые SQL-запросы
Теперь рассмотрим работу PostgreSQL на примере простого запроса к представлению Locations:
SELECT
CityID,
CityName,
RegionName
FROM Locations
WHERE CityID = 1;
Общая схема выполнения запроса выглядит так:

Выполнение запроса можно разделить на следующие этапы:
- Установка подключения к серверу СУБД
- Трансформация SQL-запроса
- Планирование запроса
- Исполнение запроса
- Завершение соединения
Установка подключения к серверу СУБД
В PostgreSQL реализуется модель «клиент-сервер». Для взаимодействия клиент отправляет запрос на сервер. На сервере СУБД главный процесс (postmaster) запускает отдельный серверный процесс для нашего клиентского подключения. Далее SQL-запрос передаётся на сервер в виде сообщения в текстовом виде по специальному протоколу PostgreSQL.
Разбор SQL-запроса
На сервере PostgreSQL входящий запрос подвергается лексическому, синтаксическому и семантическому анализу:
- Лексический анализ. Сначала лексический анализатор разбивает текст запроса на ключевые слова (SELECT, FROM, WHERE и т.д.), строковые и числовые литералы и другие идентификаторы. Для каждого найденного ключевого слова или идентификатора будет сгенерирован символ языка, который затем передаётся синтаксическому анализатору.
- Синтаксический анализ. Синтаксический анализатор проверяет полученный набор лексем на соответствие грамматике языка, после чего он строит дерево из лексем запроса.
- Семантический анализ. Семантический анализатор обращается к системным каталогам и дополняет дерево запроса ссылками на конкретные объекты базы данных, с указанием типов данных и другой информацией.
Схематично дерево запроса для нашего примера можно изобразить в следующем виде:

Примечание
Посмотреть подробное дерево запроса после этапа разбора можно в логфайлах сервера, заранее включив необходимые настройки. Включить можно двумя способами:
1. В файле конфигурации postgresql.conf включить параметр debug_print_parse (on).
2. Включить debug_print_rewritten из текущего подключения, использовав команду:
set debug_print_parse to on;
Лог-файл для нашего примера доступен по ссылке: postgresql.log
Трансформация SQL-запроса
На этапе трансформации происходит преобразование имён представлений в узлах дерева запроса в новые поддеревья, которые соответствуют этим представлениям. Для этого применяется система правил, которая ищет в системных каталогах подходящие правила и выполняет преобразование дерева запросов. Трансформация необходима для предоставления планировщику полной информации о таблицах и их связях между собой для построения оптимального плана выполнения запроса.
Дополненное дерево запроса для нашего примера после трансформации будет иметь следующий вид:
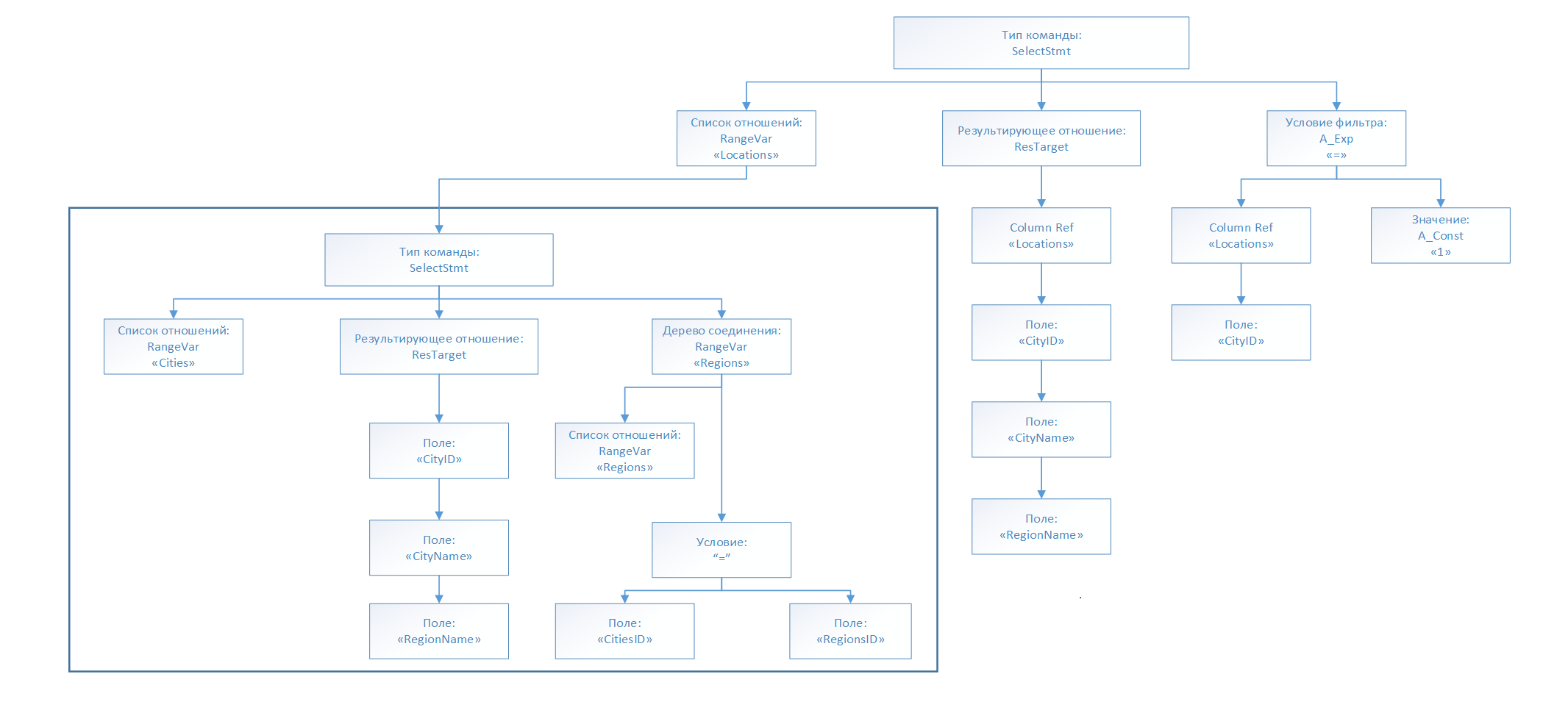
Примечание
Посмотреть преобразованное дерево запроса можно в логфайлах сервера, заранее включив необходимые настройки. Включить можно двумя способами:
1. В файле конфигурации postgresql.conf включить параметр debug_print_rewritten (on).
2. Включить debug_print_rewritten из текущего подключения, использовав команду:
set debug_print_rewritten to on;
Лог-файл для нашего примера доступен по ссылке: postgresql.log
Планирование запроса
На данном этапе выполняется поиск наиболее оптимального способа выполнения нашего запроса. Для этого планировщик осуществляет перебор возможных планов выполнения, оценивает затраты на исполнение и присваивает каждому определённую стоимость. Оценка затрат основывается на математической модели с использованием статистики об обрабатываемых данных, которая накапливается в процессе анализа и при выполнении некоторых DDL-операций, а также уточняется при очистке.
В первую очередь планировщик вырабатывает планы сканирования для таблиц с учётом наличия у них индексов, для которых могут создаваться отдельные планы. Далее происходит выработка планов соединения таблиц, при этом планировщик рассматривает все возможные способы соединения и выбирает самый выгодный. Существует три основных стратегии соединения: соединение с вложенным циклом, соединение слиянием и соединение по хэшу. В конечном итоге планировщик формирует дерево плана, состоящее из отдельных операций. Ниже приведены основные из них:
- Seq Scan – последовательное сканирование;
- Index Scan – индексное сканирование;
- Bitmap Index Scan – сканирование с построением битовых карт;
- Merge Join – соединение слиянием;
- Nested Loop – соединение с вложенным циклом;
- Hash Join – соединение по хэшу;
- Sort – операция сортировки по столбцам;
- Aggregate – вычисление агрегатных функций;
- GroupAggregate – группировка отсортированного набора;
- Unique – удаление повторяющихся данных;
- Limit – прекращение операции, после выбора нужного количества строк.
Для просмотра выбранного плана можно использовать команду EXPLAIN. В её выводе для каждого узла дерева плана отводится строка с описанием базового типа узла, оценки стоимости выполнения (cost), ожидаемое число строк (rows), ожидаемый средний размер строк (width). Команду EXPLAIN можно использовать с параметром ANALYSE, которая выполнит запрос и выведет фактический план, дополненный информацией о времени планирования и исполнения. Команду можно использовать для оценки фактического времени выполнения запроса, однако не стоит забывать, что использование параметра ANALYSE требует реального выполнения запроса в БД. Команда EXPLAIN (ANALYZE, BUFFERS) позволяет проанализировать операции ввода-вывода данных, для каждого узла в итоговом плане будет выведена строчка buffers, содержащая информацию об объёме прочитанных данных:
- Shared hit. Данные были считаны из буфера в оперативной памяти.
- Read. Данные были считаны с диска.
- Dirtied. Объём «грязных» данных, найденных в процессе выполнения.
Визуализацию планов можно посмотреть в pgAdmin или с использованием сторонних сервисов. Примеры таких сервисов: https://explain.tensor.ru/ и https://explain.dalibo.com/.
В нашем случае планировщик построил следующий план выполнения:

Nested Loop (cost=0.30..16.35 rows=1 width=72)
-> Index Scan using cities_pkey on cities (cost=0.15..8.17 rows=1 width=40)
Index Cond: (id = 1)
-> Index Scan using regions_pkey on regions (cost=0.15..8.17 rows=1 width=8)
Index Cond: (id = cities.regionid)
Сначала PostgreSQL выполнит обходы по индексам таблиц, чтобы найти удовлетворяющие условию записи, далее СУБД выполнит их соединения с помощью метода соединения вложенными циклами. Можно заметить, что в итоговый план запроса не попало никакой информации о представлении Locations, к которому мы создали запрос на выборку данных.
Для сравнения можно посмотреть на план запроса на получение всех записей из представления Locations:
SELECT
Id,
CityName,
RegionName
FROM Locations;
Планировщик построил следующий план выполнения:
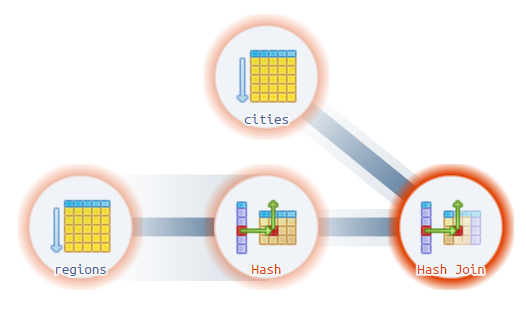
Hash Join (cost=37.00..62.16 rows=1200 width=72)
Hash Cond: (cities.regionid = regions.id)
-> Seq Scan on cities (cost=0.00..22.00 rows=1200 width=40)
-> Hash (cost=22.00..22.00 rows=1200 width=8)
-> Seq Scan on regions (cost=0.00..22.00 rows=1200 width=8)
Для получения итогового набора СУБД последовательно просканирует таблицу Regions, в узле Hash полученные записи поместятся в хэш-таблицу в оперативной памяти, далее выполнится сканирование записей таблицы cities, которые будут сопоставляться с хэш таблицей при соединении данных в узле Hash Join.
Для нашего запроса фактический план будет выглядеть следующим образом:
Nested Loop (cost=0.30..16.35 rows=1 width=32) (actual time=0.320..0.322 rows=1 loops=1)
Buffers: shared hit=2 read=2
-> Index Scan using cities_pkey on cities (cost=0.15..8.17 rows=1 width=36) (actual time=0.107..0.108 rows=1 loops=1)
Index Cond: (id = 1)
Buffers: shared hit=1 read=1
-> Index Only Scan using regions_pkey on regions (cost=0.15..8.17 rows=1 width=4) (actual time=0.205..0.205 rows=1 loops=1)
Index Cond: (id = cities.regionid)
Heap Fetches: 1
Buffers: shared hit=1 read=1
Planning Time: 0.196 ms
Execution Time: 0.376 ms
Исполнение запроса
Исполнение плана выполнения начинается с создания в памяти обслуживающего процесса объекта, который хранит в себе состояние выполняющего запроса в виде дерева, повторяющего структуру плана. Такой объект называется порталом, а его работа происходит по принципу конвейера. Выполнение запроса происходит рекурсивно, каждый корневой узел дерева обращается к дочерним узлам для получения входных данных, далее он производит необходимые преобразования и расчёты, назначенные ему планировщиком, и передаёт их вверх по дереву.
В конце концов исполнитель формирует результирующий набор строк, который возвращается клиенту в виде серии сообщений. Например, для простых запросов на выборку данных PostgreSQL отправляет сообщение RowDescription, описывающее структуру столбцов. Далее СУБД для каждой строки результирующего набора формирует сообщений DataRow и отправляет их последовательно клиенту. Завершается передача результатов выборки сообщением CommandComplete. По готовности безопасно принимать новые команды, PostgreSQL отправляет клиенту сообщение ReadyForQuery.
Завершение соединения
Для завершения работ по текущему клиентскому подключению, клиент отправляет серверу сообщение Terminate и закрывает соединение. Со своей стороны, СУБД также закрывает подключение и завершает обслуживающий процесс.
Дополнительные материалы:
Авторизуйтесь, чтобы написать комментарий