Анализ отложенных операций и работа с ними
Важным показателем хорошей работы системы является отсутствие отложенных операций циклично уходящих на перевыполнение, в связи с ошибками в выполнение экземпляров асинхронных обработчиках, блоках схем задач или другими микро-сервисами. В статье описаны способы отслеживания и остановки таких отложенных операций.
В статье рассматривается работа с СУБД PostgrSQL, поэтому все примеры запросов актуальны для данной СУБД. Для MSSQL запрос будет отличаться.
В список отложенных операций попадают асинхронно выполняемые операции, которые по той или иной причине не смогли успешно завершиться. Чаще всего в список отложенных операций попадают экземпляры асинхронных обработчиков и процессов исполнения блоков схем задач.
Работа сервиса отложенных операций выполняется по следующему принципу:
- При возникновении ошибки сервис Directum RX отправляет сообщение сервису отложенных операций через очередь RabbitMQ;
- Сервис DelayedOperationsService сохраняет сообщение в хранилище отложенных операций;
- По наступлению времени или по запросу сервис DelayedOperatinsService получает сообщение с отложенной операцией из хранилища и возвращает в исходную очередь. Если операция уже неактуальна, то сервис удаляет сообщение;

Все отложенные операции временно хранятся в таблице базы данных sungero_system_delayedoperation.
Таблица содержит следующие поля:
- id - id отложенной операции (первичный ключ таблицы);
- operationid - id экземпляра (обычно это слово Instance / Block / Monitoring + id сущности (документа, задачи, задания, номер блока в схеме задачи и т.д., но оно может быть незаполненным);
- hash - хеш операции;
- message - Json представление класса DelayOperationMessage со свойствами: type, id, operation и time (формат данных bytea);
- headers - системная информация;
- time - время следующего выполнения.
Вся основная информация об отложенной операции хранится в поле message:
- Номер итерации;
- ID сущности, с которой возникла проблем (задача, задание, документ и т.д.);
- Если проблема в схеме задачи, то дополнительно информация о номере блока и номер версии схемы задачи, а также о типе операции, которую не удалось выполнить, например "CompleteProcessMessage";
- Если проблема в работе асинхронного обработчика, то дополнительная информация об аргументах переданных в асинхронный обработчик.
- и т.д.
Так как тип данных в поле message - bytea (Бинарные данные), данные из этого поля нужно преобразовывать в читаемый вид.
Для этого нужно использовать следующую команду:
SELECT id, operationid, hash, "time", headers, encode(message::bytea, 'escape')
FROM public.sungero_system_delayedoperation
WHERE encode(message::bytea, 'escape') LIKE '%%'
ORDER BY id DESC LIMIT 1000
- encode(message::bytea, 'escape') - позволит перевести данные в поле message в читаемый вид;
- LIKE '%%' - позволит найти нужную нам отложенную операцию по включающему тексту, для этого между знаками '%' нужно ввести информацию, которая должна содержаться в отложенной операции (Например id документа, переданного аргументом в невыполненный асинхронный обработчик);
- ORDER BY id DESC - для того, чтобы все новые отложенные операции были вверху списка;
- LIMIT 1000 - выведет информацию о последней 1000 отложенных операций. (ВАЖНО! При использовании SQL запросов обязательно наличие оператора запроса LIMIT, особенно в продуктивной среде, иначе запрос может сильно нагрузить БД, вплоть до полного зависания).
Пример работы с таблицей отложенных операций
К примеру, возникла ситуация, когда миграцией были занесены в систему некоторые документы / задачи, и с ними была запущена операция в асинхронном обработчике. В дальнейшем обнаружили, что операция не выполняется.
В таком случае у нас есть несколько вариантов решения проблемы:
- По выявленной ошибке доработать асинхронный обработчик и проблема решится после публикации;
- Если ситуация такая, что проблема не решится доработкой в АО, но при этом операцию можно остановить для всех экземпляров (допустим документ / задача старые и нужны только как архивные данные), то можно остановить запросы в очереди RabbitMQ;
- Если 2 пункт невозможно выполнить, т.к. есть и старые и новые документы / задачи, то тогда мы точечно можем остановить выполнение АО в отложенных операциях.
В случае с пунктом 3 придется удалять записи из таблицы. Такой вариант можно использовать в крайнем случае, т.к. удаление записей из БД нежелательно.
Контроль количества отложенных операций
Важным пунктом здоровья системы является количественный показатель отложенных операций. Чем больше операций отправляется на перевыполнение, тем сильнее будет нагружена система в целом, т.к. все отложенные операции будут выполнятся на стороне того сервиса, который не смог их выполнить ранее. В связи с этим стоит иногда просматривать количество отложенных операций командой:
SELECT count(*) FROM public.sungero_system_delayedoperation;
Если для мониторинга ошибок используется Grafana, то легко можно понять, какие ошибки идут в отложенные операции по синусоидам графика.
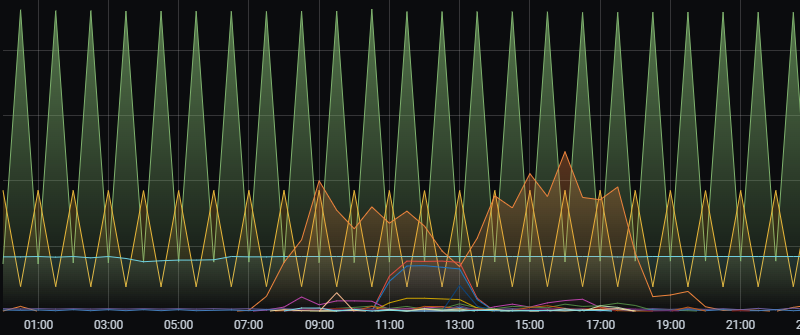
Желтая и зеленая линии на графике явно говорят о повторяющейся ошибке, в результате анализа которой, возможно, придется удалять записи этих операций из таблицы отложенных операций.
Утверждение, что в поле message хранится текст ошибки, не корректно, т.к. это Json представление класса DelayOperationMessage со свойствами: type, id, operation и time.
После десериализации, в зависимости от type, это сообщение выполняется в соответствующем сервисе.
Пример для блока мониторинга, который выполняется в WorkflowBlockService:
Про контроль количества отложенных операций: в "коробке" РХ 4.2 в поручениях есть блок "Мониторинг начала корректировки" со свойством "срок прекращения = 10000 дней", поэтому в отложенные операции попадают записи по всем задачам ActionItemExecutionTask, и после завершения задачи запись остается в отложенных операциях (поле Time при этом 2049-2050 год). Поэтому, например, у нашего клиента в этой таблице более 500тыс записей по этим поручениям, и это не является "плохим" показателем для отложенных операций, так задумано в "коробке". Поэтому предлагаю запрос указать примерно такой (кол-во отложенных операций с пустым временем или с временем менее 10 дней)
select count(1)
from Sungero_System_DelayedOperation
where Time is null or Time < DATEADD(DAY, 10, GETDATE())
Сергей, Очень ценное замечание, поправлю в статье, спасибо!
Юрий, не встречал такого блока мониторинга в 4.1 и 4.3. К тому же не удалось воспроизвести срок прекращения равный 10000 дней, максимум 3 дня. Можете приложить скриншот?
Основная идея запроса поиска длительных отложенных операций в том, чтобы найти операции с большим количеством итераций, то есть явно больше 10 дней.
В Вашем случае лучше исключать подобные блоки мониторинга другим способом из общего запроса, например выделив общую часть из поля message и исключать из запроса эту часть.
Андрей, в 4.1 кажется еще не было Корректировки поручений, а в 4.3 добавили схему V4 для ActionItemExecutionTask. Можете в 4.3 в среде разработки переключить на схему V3 - в ней должно быть видно этот блок и этот срок. По крайней мере в скаченных с partners исходных кодах "Исходные коды для DirectumRX 4.3.23.0.zip\DirectumRXbase.dat\source\Sungero.RecordManagement\Sungero.RecordManagement.Server\ActionItemExecutionTask\ActionItemExecutionTaskScheme.V3.xml" видно этот блок 110 и срок в нем в 10000 дней.
Подскажите куда копать дальше в анализе отложенных операций.
Вижу пилу в графике WPS.
Постоянно повторяющиеся ошибки вида (с несколькими Id):
"Cannot 'Abort process'. Instance does not exist. InstanceId = 672611."
В логах вижу, что все это циклично крутится в DelayedOperatinsService с постоянно увеличивающимся iteration.
Вот логи для ошибки:
"lg":"WorkflowProcessServiceSpan","span":{"status":"Started","name":"Handle process message","messageType":"AbortProcessMessage"}
и сразу
"lg":"WorkflowProcessServiceSpan","span":{"durationMs":15,"status":"Failed","name":"Handle process message","messageType":"AbortProcessMessage"}
"lg":"RabbitMqSubscriber","mt":"Cannot 'Abort process'. Instance does not exist. InstanceId = 672611."
А вот пример хорошей безошибочной обработки:
"lg":"WorkflowProcessServiceSpan","span":{"status":"Started","name":"Handle process message","messageType":"AbortProcessMessage"}
и дальше обработка
"lg":"InstancesStorage","mt":"Process instance loaded. InstanceId = {instanceId}, SchemeId = {instanceSchemeId}","args":{"instanceId":963717,"instanceSchemeId":3}
"lg":"LockManager","mt":"Add lock (Storage: WorkflowProcessService, LockKey: 963717)"
"lg":"RabbitMqPublisher","mt":"Message has been published with confirmation."
...
Я понимаю, что вижу уже следствие. Но как найти причину ошибки, чтобы ее устранить? Что за Process instance, и почему некоторых ID не существует?
Кто-то может поделиться опытом или подсказать в каком направлении двигаться?
Винокуров, instanceId это id задачи, располагается в wf_instance
думаю надо проверить реально есть ли инстанс в таблице и проверить содержимое остальных связанные таблиц
select * from sungero_wf_instance where instanceid = <task_id>
select * from sungero_wf_blockstate where instanceid = <task_id>
select * from sungero_system_delayedoperation where operationid = 'Instance<task_id>'
И если инстанс пропал -- смотреть логи что происходило с задачей
Большое спасибо за помощь!! Информацию по проблеме собрали, будем отрабатывать с прикладниками.
Выяснил, что operationid у проблемных записей пустой, пришлось искать их другими способами.
В процессе изучения таблички с отложенными операциями слепил селект, который вытягивает все записи с количеством повторов больше 10 (с расшифровкой тела message):
select id, operationid, hash, "time", headers, encode(message::bytea, 'escape') from sungero_system_delayedoperation where cast(headers::json->>'Iteration' as numeric) > 10
Может другим новичкам (как мне) пригодится.
И еще дополнение по теме статьи и итогам работы с табличкой sungero_system_delayedoperation.
У меня сложилось впечатление, что в нее попадают блоки не "при возникновении ошибки", а вообще все. У меня сейчас в этой табличке порядка 55 тыс. записей, причем все актуальные. При этом практически все записи "process_service_blocks_out". Предположу, что обработка всех блоков идет через сервис отложенных операций. То ли это в стандарте так (а не так как описано выше в статье и справке), то ли у нас через одно место сделано... Но система при этом функционирует без ошибок. Поэтому количество записей в таблице говорит только о нагруженности системы, но не об ошибках.
Винокуров, вам удалось разобраться, что это за отложенные операции повисли в БД? у нас нашёл небольшое количество таких же, почти все относятся к Abroted
Винокуров, это же как показано на схеме,сохранение операции в хранилище, но почему они висят там долгое время - вопрос интересный
Винокуров, Добрый день! Всё верно, в отложенные операции попадают не только ошибки. Там хранятся и асинхронные обработчики отправленные в retry, там же и блоки мониторинга схем задач, которые ожидают успешного выполнения условия мониторинга и т.д.
Konstantin, я нашел несколько видов проблемных записей. Как уже говорил, у нас практически все записи по обработке в workflow, видимо тот самый мониторинг выполнения. Соответсвенно, как Вы посоветовали, по instanceId можно найти задачу в системе.
Первые - с чего и начинал поиск - это сбойные задачи (дают пилу в графане в WPS, у нас их было 5). Задачи нашел, в системе абсолютно нормальные. По ним в свое время было выполнено прекращение задачи (Aborted), но оно почему-то не отработалось и теперь бесконечно циклится. Причину этого сбоя выяснить не удалось. Удаление одной старой ненужной задачи в системе результата не дало, поэтому записи были удалены из sungero_system_delayedoperation - пила ушла, проблема решена. Но причина не выяснена, вероятен повтор.
Второй вид - несколько записей с асинхронными обработчиками. Это наш самописный функционал. Судя по ошибке у пользователя не создались каталоги на сетевом ресурсе, и эти ошибки повторялось каждые 15 минут (количество итераций несколько десятков-сотен тысяч). Давало ошибки в графану в Worker. Эти записи тоже были удалены из sungero_system_delayedoperation.
Третий вид - полторы сотни записей с очень маленьким id (судя по этому - висят со времен опытной эксплуатации системы). Эти записи с пустым time. Для интереса посмотрел несколько задач в системе - приостановлены по ошибке. Повторный запуск - ошибка. Разбираться с ними смысла нет, можно просто удалить, тогда записи из sungero_system_delayedoperation уходят.
Именно последние записи висят в табличке долгое время, остальные обрабатываются в течение суток. И либо удачно отрабатывают, либо запускаются на следующую итерацию, но уже с новым id.
Сергей, Благодарю за ответ. А вы планируете обращаться в поддержку по этому вопрос? Если да, не могли бы сюда написать, что по итогу решили?
Konstantin, а с чем тут в поддержку обращаться? По самописному функционалу привлекли подрядчиков (это их код). Если по первому виду проблемных записей, то у меня есть подозрение, что эти сбои происходили в моменты перезагрузки системы.
А вообще по поддержке - это нечто. Мой небольшой опыт общения с ними отбил всякую охоту туда обращаться ))) И еще удручает скудность технической информации и ее закрытость.
Сергей,
> а с чем тут в поддержку обращаться?
с тем, что по хорошему, workflow должен анализировать поступающие запросы на мёртвые задачи и сам прекращать обработку данных операций (удалять запись из БД), а не отправлять на новый круг.
Авторизуйтесь, чтобы написать комментарий