Распределённое отказоустойчивое хранилище документов на GlusterFS
Введение
Одна из основ работы любого ЭДО – это хранение документов. В частности, будем рассматривать на примере нашей любимой интеллектуальной системы управления цифровыми процессами и документами Directum RX. Как все мы знаем DirectumRX в своей работе использует систему хранения документов, а именно сервис хранения документов Storageservice, который сохраняет в предопределенную настройками папку бинарные образы документов, файлы формата. blob, сервис хранения файлов предпросмотра PreviewStorage, который так же сохраняет образы документов в предопределённую настройками папку.
Все эти сервисы, исходя из возможностей DirectumRX, могут масштабироваться горизонтально, их может быть сколько угодно, исходя из потребностей заказчика. Установка может производиться как в рамках одного сервера под разными инстансами, так и в рамках нескольких серверов. Как уже сказали выше, все образы документов складываются в предопределенную папку, назовем ее storage для StorageService и preview для PreviewStorage.
Согласно правильному ИТ-подходу к хранению чего-либо, будь то документы или базы данных, все должно подлежать резервному копированию. Обычно для резервного копирования образов документов используется такая утилита как Rsync - программное обеспечение с открытым исходным кодом, которое можно использовать для синхронизации файлов и папок с локального компьютера на удаленный и наоборот. Утилита позволяет копировать не только все файлы целиком, но и учитывать, например, измененные файлы, или новые файлы, и копировать только их. Иногда компании используют возможности гипервизоров для создания резервной копии – полностью копируют виртуальную машину и сохраняют ее образ, например, с помощью NetBackup или Кибер Бэкап.
Почему была написана эта статья…
Когда один наш заказчик попросил действительно отказоустойчивое хранение документов, стандартные решения не подошли. В данный момент чаще всего используется несколько вариантов:
- Виртуальная машина с сервисом хранилищ в кластере, сетевое дисковое хранилище. Отказоустойчивость обеспечивается миграцией виртуальной машины на другую ноду кластера средствами гипервизора с небольшим перерывом в обслуживании.
- Несколько серверов с сервисом хранилищ, общий расшаренный каталог (или сетевое хранилище) для хранения файлов, все сервера физически смотрят на один каталог, отказоустойчивость обеспечивается за счет RAID.
- Несколько серверов (виртуальных машин?) с сервисом хранилищ, синхронизация файлов через RSync.
Как видим, идеально распределённого варианта с максимальным использованием современного программного обеспечения… почему то просто не нашлось...
Концепция решения
Вот мы и подошли плавно к теме нашей статьи, а именно к возможности распределённого отказоустойчивого хранения файлов (в нашем случае образов документов) в реальном времени с помощью программного обеспечения GlusterFS
Что такое Gluster - распределённая, параллельная, линейно масштабируемая, удобная и простая в использовании и настройке файловая система с возможностью защиты от сбоев, которая работает в пользовательском пространстве используя FUSE технологию (filesystem in userspace), т.е. работает поверх основной файловой системы. Может быть «размазана» по разным серверам с целью защиты от сбоев и/или повышения производительности дисковой системы.
Простыми словами, предположим у нас папки сохранения образов документов storage и preview расположены на сервере server1, мы создаем в DirectumRX документ «Тестовый», соответственно в папке storage создается бинарный образ «1qwerty0987654321.blob». открываем документ с помощью предпросмотра и в папке preview также создается образ «1qwerty0987654321p». С помощью GlusterFS мы можем настроить так, что эти файлы автоматически реплицируются в реальном времени в те же самые папки, но на server2 и на server3 и т.д. в зависимости от того сколько резервных узлов gluster мы настроим.
GlusterFS позволяет нам отказаться от постоянного копирования файловых хранилищ, осуществляя репликацию в реальном времени.
Как работает Gluster
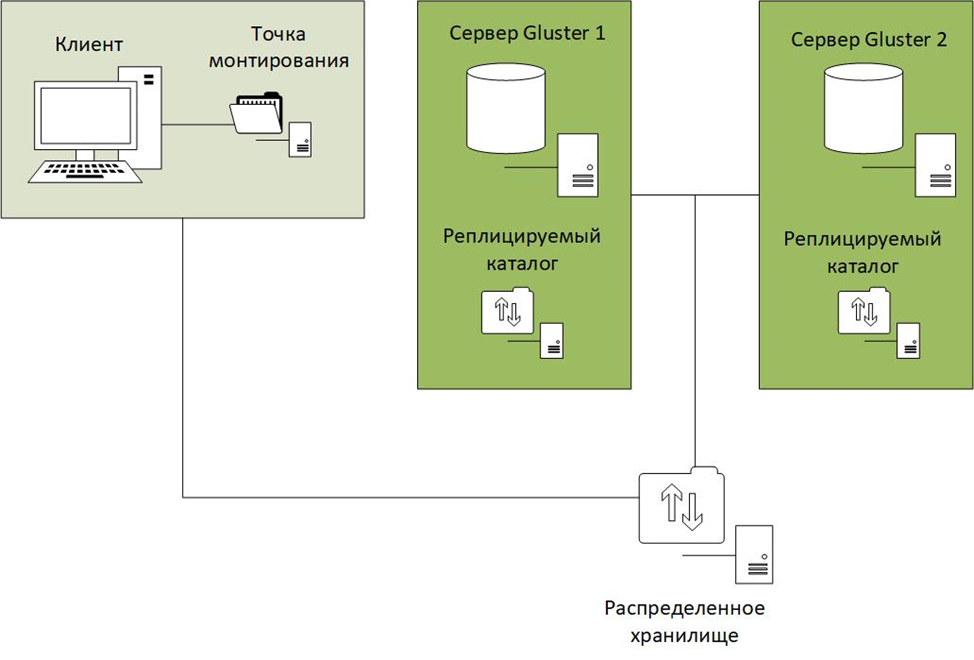
Существует несколько способов настройки репликации в Gluster:
- Distributed volume – Распределенный. При данной настройке данные будут распределяться в случайном порядке между всеми серверами, которые входят в том Gluster (распределенное хранилище).
- Replicated volume – Реплицируемый. При данной настройке данные зеркально копируются между всеми серверами Gluster (аналог бэкапа), в каждой папке тома одни и те же данные.
- Striped volume – Разделенный по частям. Данные разбиваются на части и каждая часть хранится в разных папках тома, такой тип распределения подходит для очень больших файлов, например видеоконтент.
- Distributed Striped volume - Распределенный и разделенный по частям. При такой настройке файлы будут разбиваться на части, и куски файлов будут распределяться по папкам и храниться в случайном порядке.
- Distributed Replicated volume – Распределенный и реплицируемый. При этой настройке данные будут распределяться в случайном порядке между папками и каждая папка имеет свою зеркальную копию.
Пример установки
Разберем одну из самых часто используемых схем – Replicated volume (аналог бэкапа) Предположим, что у нас 2 ноды GlusterFS, на которые устанавливается gluster-server:
root@server1:~#apt-get install python-software-properties
root@server1:~#apt-get update
root@server1:~#apt-get install glusterfs-server -у
root@server2:~#apt-get install python-software-properties
root@server2:~#apt-get update
root@server2:~# apt-get install glusterfs-server -у
Проверка кластера (Проверяем подключение с первого сервера на второй и наоборот):
root@server1:~# gluster peer probe server2.domen.ru
root@server1:~# gluster peer statusNumber of Peers:1Hostname: server2.example.comUuid: 73497589-hjfsioj98494f0-8jf094f30jjState: PeerinCluster (Connected)
Создаются каталоги для реплицируемых данных, правильно они называются брики (brick):
root@server1:~# mkdir /mnt/repl1root@server2:~# mkdir /mnt/repl2
Создается распределённый том:
root@server1:~# gluster volume create replicated replica 2 transport tcp server1:/mnt/repl1 server2:/mnt/repl2 forceMultiple bricks of a replicate volume are present on the same server. This setup is not optimal.Do you still want to continue creating the volume? (y/n) yvolume create: replicated: success: pleasestartthe volume to access dataroot@server1:~# gluster volume start replicatedvolumestart: replicated: success
В данном случаи все файлы будут реплицироваться на все папки. Т.е. во всех папках gluster будет находиться один и тот же контент:
Далее на клиентских машинах (в случае DirectumRX – на серверах с сервисами хранилищ) устанавливается glusterfs-client
root@client1:~#apt-get install python-software-propertiesroot@client1:~#apt-get updateroot@client1:~#apt-get install glusterfs-client
Монтируется сетевая папка по имени созданного распределенного тома, при этом не играет роль имя сервера, на котором создан данный том. Если у нас 2 ноды Gluster – то любой из этих серверов прописывается в точку монтирования.
root@client1:~# mkdir /mnt/replica
root@client1:~# mount.glusterfs server1:/replicated /mnt/replica/
root@client1:~# df -h

Схема кластера из двух серверов GlusterFS обеспечивает постоянное реплицируемое хранение файлов. Но есть один нюанс, данная схема подходит для систем с минимальным простоем при сбое, т.е. во время работы каждая нода кластера попеременно является арбитром, храня и метаданные и тела, и при выходе из строя одной их них на долгое время (более суток), существует вероятность split-brain, когда при восстановлении работы вышедшей из строя ноды не все тела документов подгрузятся на нее. Когда система находится в состоянии split brain (термин означает – каждый узел считает себя главным), данные или метаданные (разрешения, uid / gid, расширенные атрибуты и т.д.) файла находятся в несоответствии между элементами реплики и недостаточно информации, чтобы авторитетно выбрать копию как нетронутую и исправить поврежденные или недостающие данные несмотря на то, что все элементы установлены и подключены. В этом случае рекомендуется создавать кластер GlusterFS из трех нод, одна из которых будет арбитром, т.е. будет хранить на себе метаданные.
Например:
root@server1:~# gluster volume create replicated replica 2 arbiter 1 transport tcp server1:/mnt/repl1 server2:/mnt/repl2 server3:/mnt/repl3 force
Таким образом кластер с управляющим сервером более устойчив к split-brain и являются рекомендуемым для резервного копирования данных в реальном времени.
Преимущества использования
- Повышение отказоустойчивости файлового хранилища – документы автоматически хранятся уже в трёх экземплярах.
- Основное хранилище доступно всегда и не подвергается повышенным нагрузкам при снятии резервной копии, так как храним документы в основном хранилище, а резервную копию делаем на реплицированной ноде.
Заключение
Распределенное хранение документов на основе GlasterFS успешно внедрено у заказчика, построен кластер с арбитром, реплицируется как storageservice, так и previewservice с previewstorage со всеми служебными подкаталогами. Пройдены нагрузочные испытания, клиент доволен, а это самое главное!
GlusterFS является отличным решением для репликации и создания резервных копий файлов и документов, также он предоставляет возможности объединения систем хранения, находящихся на разных серверах в одну параллельную файловую систему.
Евгений, а как проводили нагрузочные испытания?
Василий, В реальном времени отключали сеть от одного брика, потом от другого, параллельно пользователи создавали документы, пользовались предпросмотром
Очень интересно
День добрый! По скорости работы Хранилища при интенсивном использовании есть сложности?
Дмитрий, проблем не возникает
Авторизуйтесь, чтобы написать комментарий