PostgreSQL: Логирование, трекинг долгих запросов и автообслуживание
1. Введение
Прочитав эту статью, вы узнаете, как настроить и использовать логирование, как идентифицировать и устранять проблемы с долгими запросами, а также как правильно применять инструменты автообслуживания для поддержания базы данных в оптимальном состоянии без вмешательства администратора.
2. Логирование и трекинг долгих запросов
Эффективность работы базы данных PostgreSQL напрямую зависит от оптимизации запросов. Для идентификации и анализа длительных запросов можно использовать такие инструменты, как pg_profile и pgbadger, предоставляющие ценную информацию о производительности и статистике запросов. В этом разделе мы рассмотрим, как настроить логирование длительных запросов и сбор статистики в PostgreSQL.
2.1. Расширения pg_profile
pg_profile — это расширение для PostgreSQL, разработанное для мониторинга производительности базы данных. Оно позволяет собирать, анализировать и визуализировать статистику работы сервера, помогая идентифицировать и устранять узкие места.
2.1.1. Настройка PostgreSQL
Все настройки указываются в файле postgresql.conf.
- Раскомментируем строку shared_preload_libraries и добавляем параметр pg_stat_statements:
Расширение pg_stat_statements позволяет собирать статистику о выполнении SQL запросов.shared_preload_libraries = 'pg_stat_statements' - Настраиваем параметры сборщика статистики:
track_activities = on track_counts = on track_io_timing = on track_wal_io_timing = on track_functions = pl track_activity_query_size = 10000 log_min_duration_statement = 3000
- track_activities = on: Этот параметр включает отслеживание активности в базе данных. Когда он включен, PostgreSQL будет вести учет активных подключений и предоставлять информацию о них в системных представлениях, таких как;
- track_counts = on: Включает сбор статистики, такой как количество выполненных запросов, количество строк, затронутых запросами, и т.д. Эта информация доступна в системных представлениях, таких как pg_stat_database и pg_stat_all_tables;
- track_io_timing = on: При включении этого параметра PostgreSQL будет вести учет времени, затраченного на ввод/вывод операций. Эта информация также будет доступна в системных представлениях, таких как pg_stat_database;
- track_wal_io_timing = on: Аналогично track_io_timing, этот параметр включает отслеживание времени операций ввода/вывода, но для записей в журнале транзакций (WAL - Write-Ahead Logging);
- track_functions = all/pl: Этот параметр отвечает за отслеживание выполнения функций.
All - включает отслеживание для всех функций, включая пользовательские, а также встроенные.
pl - включает отслеживание только для функций языков PL/pgSQL; - track_activity_query_size: определяет максимальный размер текста SQL-запроса, который будет отслеживаться и сохраняться в системных представлениях, таких как pg_stat_activity.
- log_min_duration_statement = 3000: Этот параметр устанавливает пороговое значение продолжительности выполнения запроса в миллисекундах, после которого он будет записан в журнал (Минимальное значение параметра 3s, для систем с кол-ом пользователей более 1000 - 5s)
- Настраиваем параметры расширения pg_profile и pg_stat_statements:
pg_stat_statements.max = 20000 pg_stat_statements.track = 'top' pg_stat_statements.save = off pg_profile.topn = 100 pg_profile.max_sample_age = 7 pg_profile.track_sample_timings = on
- pg_profile.topn: количество верхних объектов (операторов, отношений и т. д.), которые будут отображаться в каждой отсортированной таблице отчета. Также этот параметр влияет на размер выборки — чем больше объектов вы хотите отобразить в своем отчете, тем больше объектов нам нужно держать в выборке;
- max_sample_age: Время хранения образцов в днях. Образцы, возрастом pg_profile.max_sample_age и более дней, будут автоматически удалены при следующем вызове take_sample();
- track_sample_timings: когда этот параметр включен, pg_profile будет отслеживать подробное время взятия проб.
2.1.2. Установка
- Скачиваем последний релиз с репозитория проекта pg_profile.
- Распаковываем файлы расширения в папку расширений PostgreSQL:
echo $(pg_config --sharedir)/extension #выводим путь до папки psql sudo tar xzf pg_profile--*.tar.gz --directory=<путь к папке psql>/extension - Подключаемся к БД под пользователем postgres:
psql -U postgres - Переключаемся к БД:
\c <db_name> -
Создаём расширения в БД pg_profile:
create schema profile; create extension pg_profile schema profile; CREATE EXTENSION dblink; CREATE EXTENSION pg_stat_statements; - Перезапускаем СУБД:
systemctl restart postgresql
2.1.3. Настройка построения отчетов
- Создаём каталог для готовых отчетов и выдаём права на него пользователю, под которым запущен postgresql (обычно это postgres):
sudo mkdir -p /home/postgres/reports sudo chown postgres:postgres /home/postgres/reports - Добавляем создание отчёта в cron пользователя postgres:
crontab -e -u postgres - Добавляем записи (Время выполнения опционально):
psql -d pg_profile -qtc "select snapshot();" psql -d pg_profile -Aqtc "select get_report(tstzrange(now() - interval '1 day 1 hour', now()));" -o /home/postgres/reports/report_`date --date="yesterday" +\%Y\%m\%d`.html
2.1.4 Пример использования
- Открываем файл с отчетом и переходим к пункту Top SQL by execution time.
Информация! Таблица отчёта показывает запросы с наибольшей длительностью выполнения, определяемой по значению поля Exec (s).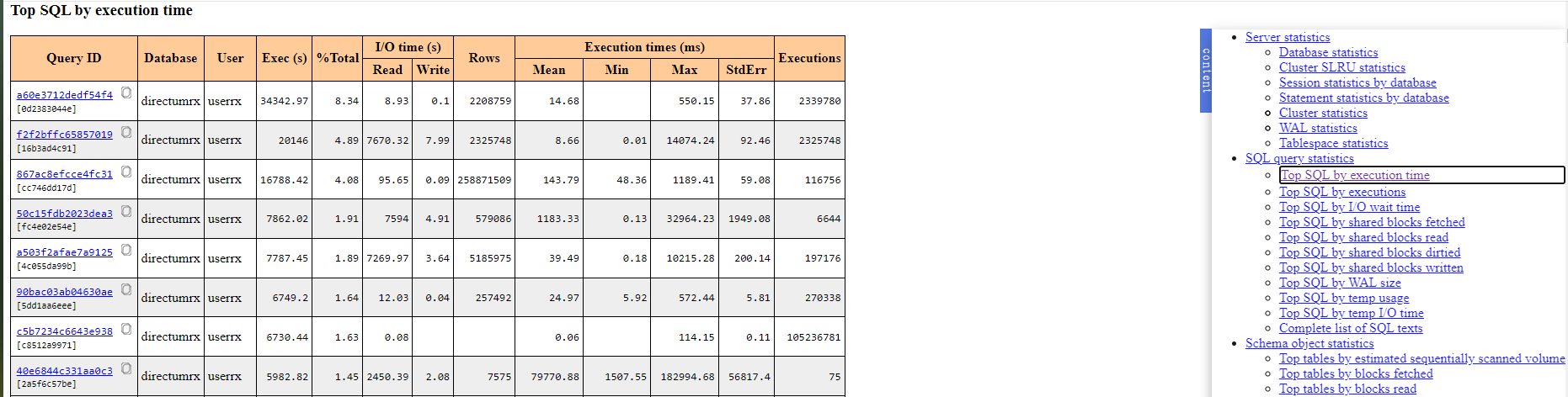
- По нажатию на ссылку из столбца «Query ID», мы перейдем к самому запросу.

- Ищем интересующие нас запросы из отчёта pg_profile в лог-файлах PostgreSQL.
- Нас интересует следующая информация — сам запрос и его параметры:
- Тело запроса:
2023-12-18 11:10:03 +05 [10.12.132.35]: [WebServer] [35750]: [7-1] LOG: duration: 19459.582 ms execute [unnamed](unnamed): /* Web Server : tr=cl-1baddb59-ef2836 : id=347783 / / Web Server : tr=cl-1baddb59-ef2836 : AllOutgoingDocumentsSC : id=347783 / select electronic0_."id" as col_0_0_, electronic0_.Discriminator as col_1_0_ from public."sungero_content_edoc" electronic0_ where electronic0_."id" in (select outgoingle1_."id" from public."sungero_content_edoc" outgoingle1_ where outgoingle1_."discriminator"='d1d2a452-7732-4ba8-b199-0a4dc78898ac' and (exists (select accesscont2_."id" from public."sungero_system_accessctrlent" accesscont2_ where accesscont2_."granted"=$1 and accesscont2_."operationset" & $2=$3 and (accesscont2_."recipient" in ($4 , $5 , $6 , $7 , $8 , $9 , $10 , $11 , $12 , $13 , $14 , $15 , $16 , $17 , $18 , $19 , $20 , $21 , $22 , $23 , $24 , $25 , $26 , $27 , $28 , $29 , $30 , $31 , $32 , $33 , $34)) and accesscont2_."secureobject"=outgoingle1_."secureobject")) and outgoingle1_."businessunit_docflow_sungero"=$35 and (extract(year from outgoingle1_."documentdate_docflow_sungero")=$36 or $37=extract(year from outgoingle1_."created") and (outgoingle1_."documentdate_docflow_sungero" is null)) and outgoingle1_."regstate_docflow_sungero"=$38 and ((outgoingle1_."documentdate_docflow_sungero">=$39 and outgoingle1_."documentdate_docflow_sungero"<=$40 or outgoingle1_."documentdate_docflow_sungero"=$41) and outgoingle1_."documentdate_docflow_sungero"<>$42 or (outgoingle1_."documentdate_docflow_sungero" is null) and (outgoingle1_."created">=$43 and outgoingle1_."created"<=$44 or outgoingle1_."created"=$45)) and ((outgoingle1_."subject_docflow_sungero" is not null) and outgoingle1_."subject_docflow_sungero" ~ $46 or (outgoingle1_."regnumber_docflow_sungero" is not null) and outgoingle1_."regnumber_docflow_sungero" ~* $47 or 1=0 or (outgoingle1_."name" is not null) and outgoingle1_."name" ~* $48) order by outgoingle1_."id" desc limit $49) order by electronic0_."name" ASC NULLS FIRST, electronic0_."id" ASC NULLS FIRST limit $50 - Параметры запроса:
2023-12-18 11:10:03 +05 [10.12.132.35]: [WebServer] [35750]: [8-1] DETAIL: parameters: $1 = 't', $2 = '1', $3 = '1', $4 = '64', $5 = '68', $6 = '70', $7 = '71', $8 = '72', $9 = '77', $10 = '131', $11 = '132', $12 = '133', $13 = '138', $14 = '139', $15 = '193', $16 = '925', $17 = '34843', $18 = '35412', $19 = '42935', $20 = '43480', $21 = '44383', $22 = '45916', $23 = '46406', $24 = '48085', $25 = '48097', $26 = '48563', $27 = '6', $28 = '42195', $29 = '42196', $30 = '65', $31 = '43488', $32 = '44386', $33 = '47309', $34 = '49011', $35 = '925', $36 = '2023', $37 = '2023', $38 = 'Registered', $39 = '2023-01-01 00:00:00', $40 = '2023-12-31 23:59:59', $41 = '2023-01-01 00:00:00', $42 = '2024-01-01 23:59:59', $43 = '2023-01-01 00:00:00', $44 = '2023-12-31 23:59:59', $45 = '2023-01-01 00:00:00', $46 = '783[/]23', $47 = '783[/]23', $48 = '783[/]23', $49 = '10000', $50 = '1000'
- Далее объединяем их через утилиту
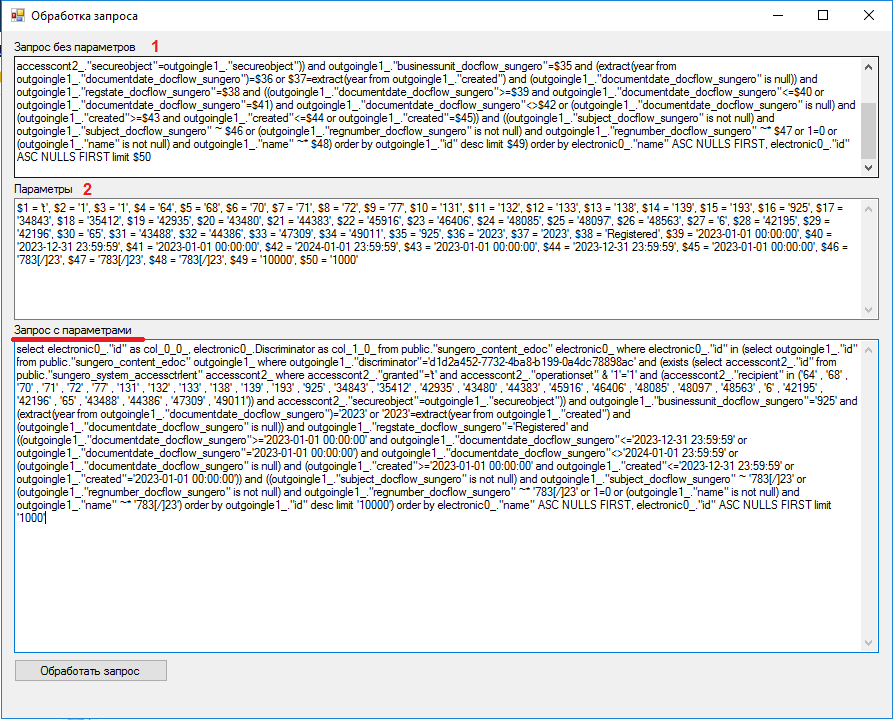
- Анализ запроса рассмотрим в главе: "2.3 Как получить выгоду от отчетов".
2.2. pgBadger как инструмент анализа логов
pgBadger - это инструмент анализа и отчетности для журналов PostgreSQL. Он анализирует журналы базы данных PostgreSQL и создает детальные отчеты о производительности, статистике запросов, использовании индексов, времени выполнения запросов и многом другом. Pgbadger может помочь в оптимизации производительности базы данных, выявлении узких мест и улучшении общей производительности системы на основе данных из журналов PostgreSQL.
2.2.1. Установка
- При использовании pgBadger для анализа логов postgresql, не обязательно устанавливать его в продуктивных контурах, достаточно установить его у себя локально и применять его для составления отчетов из предоставленных логов. Установка на ВМ с ОС Linux:
apt install pgbadger - Настройка логирования:
Пример конфигурации.lc_messages = 'en_US.UTF-8' ## - английская локализация журналов log_destination = 'stderr' ##- запись логов уровня shared_preload_libraries = 'pg_stat_statements' ##- подключение библиотеки для сбора статистики pg_stat_statements.track = 'top' ##- отслеживание трудоёмких ресурсов log_min_duration_statement = 3000 ##- Этот параметр устанавливает пороговое значение продолжительности выполнения запроса в миллисекундах, после которого он будет записан в журнал log_line_prefix = '%t [%h]: [%a] [%p]: [%l-1] ' ##- Этот параметр определяет формат префикса для строк журнала. В данном случае строка включает время (%t), идентификатор процесса (%p), уровень журналирования (%l), текст запроса (%q), имя пользователя (%u) и имя базы данных (%d). logging_collector = on ##- включение сбора логов log_directory = '/var/log/postgresql/' ##- директория логов log_filename = 'postgresql-%Y-%m-%d.log' ##- формат записи логов и ротаци - Так же необходимо создать экстеншен для сбора статистики в базе.
su postgres psql \c "<DB name>"; CREATE EXTENSION pg_stat_statements; - Проверьте наличие английской локали:
- Выполните команду
localectl list-locales - Установите английскую локаль (enUS.UTF-8), если она отсутствует:
- Запустите команду
dpkg-reconfigure locales - Выберите в списке английскую локаль (enUS.UTF-8)
- Запустите команду
- Выполните команду
- Перезапускаем СУБД:
systemctl restart postgresql
2.2.2. Запуск построения отчетов
pgbadger <путь до лог файла> -o otchet.html
Также можно запустить построение отчета с использованием любых префиксов, которые настроены в логировании postgresql.
pgbadger -j 4 -p '%t [%h]: [%a] [%p]: [%l-1]' <путь до лог файла> -o otchet.html
В итоге мы получим отчет в формате html, который можно анализировать в браузере.
Основные ключи при построении отчета:
- -m — указание количество символов в запросах при построении отчета. (Необходимо использовать при очень крупных запросах)
- -t — количество запросов, попадающих в TOP
- -j — количество потоков при построении отчета
- -p — описание префикса для построения отчета
2.2.3. Пример использования
Пример был взят с проекта, испытывающего проблемы с производительностью системы. Для проведения анализа, как описано выше, было настроено логирование PostgreSQL, после чего были скачаны и проанализированы логи, на основе которых был составлен отчет pgBadger.
В отчете нас интересует вкладка «TOP» где можно увидеть самые длительные запросы (нас интересует первый запрос)
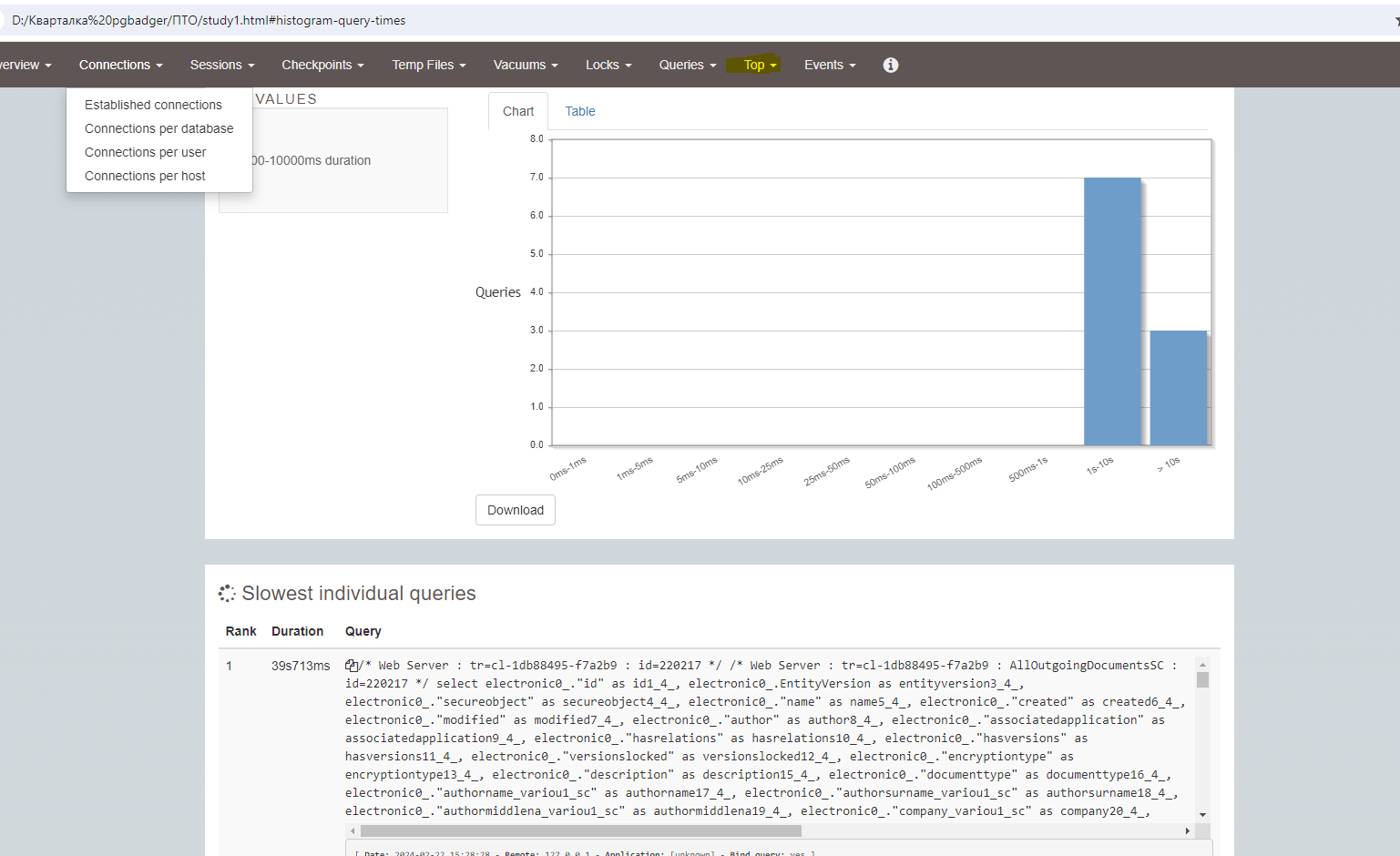
2.3. Как получить выгоду от отчетов
Здесь пригодится Tensor Explain — сервис для разбора и визуализации планов запросов. С его помощью можно ещё быстрее и нагляднее представить, как выглядит запрос для базы данных: лёгкий ли он, есть ли у него проблемы и в каких местах.
2.3.1. Анализ запроса
Для анализа запроса необходимо создать план его выполнения. Для этого добавляем ключевое слово EXPLAIN и опции (ANALYZE, BUFFERS) в начало нашего запроса далее выполняем его в PostgreSQL.
Список всех опций для EXPLAIN:
- ANALYZE - Выполняет фактический запуск запроса, собирая статистику выполнения. Полезно для точной оценки производительности запроса.
- VERBOSE – Покажет расширенную информацию плана запроса, включая дополнительные детали.
- COSTS - Покажет расчетные затраты на выполнение каждого шага плана запроса (по умолчанию включено).
- BUFFERS – Покажет статистику использования буферов, что помогает понять, сколько операций чтения и записи было выполнено с буферами данных.
Этот параметр часто используется вместе с ANALYZE.
- TIMING - Покажет время выполнения каждого шага плана запроса. По умолчанию включено, если используется ANALYZE.
- SUMMARY - Включить или выключить вывод общего обзора выполнения запроса. Полезно для получения краткой сводной информации.
Включено по умолчанию, если используется ANALYZE.
- FORMAT - Определяет формат вывода плана запроса. Возможные значения: TEXT (по умолчанию), XML, JSON, YAML.
- SETTINGS - Включает в вывод параметры конфигурации, установленные на уровне сессии, которые могли повлиять на выполнение запроса.
Примечание: Стоит отметить, что запросы на изменение данных не следует выполнять с опцией ANALYZE, данная опция подразумевает выполнение запроса.
Затем копируем полученный план выполнения запроса и анализируем его с помощью сервиса explain.tensor.ru. На скриншоте в левой части видно узлы запроса и цветные иконки с рекомендациями по оптимизации. Из показателей можно заметить, что наибольшую выгоду даст создание индексов, однако не стоит игнорировать и другие рекомендации. Здесь нас интересовал совет тензора относительно недостающего индекса, он помечен на скриншоте.
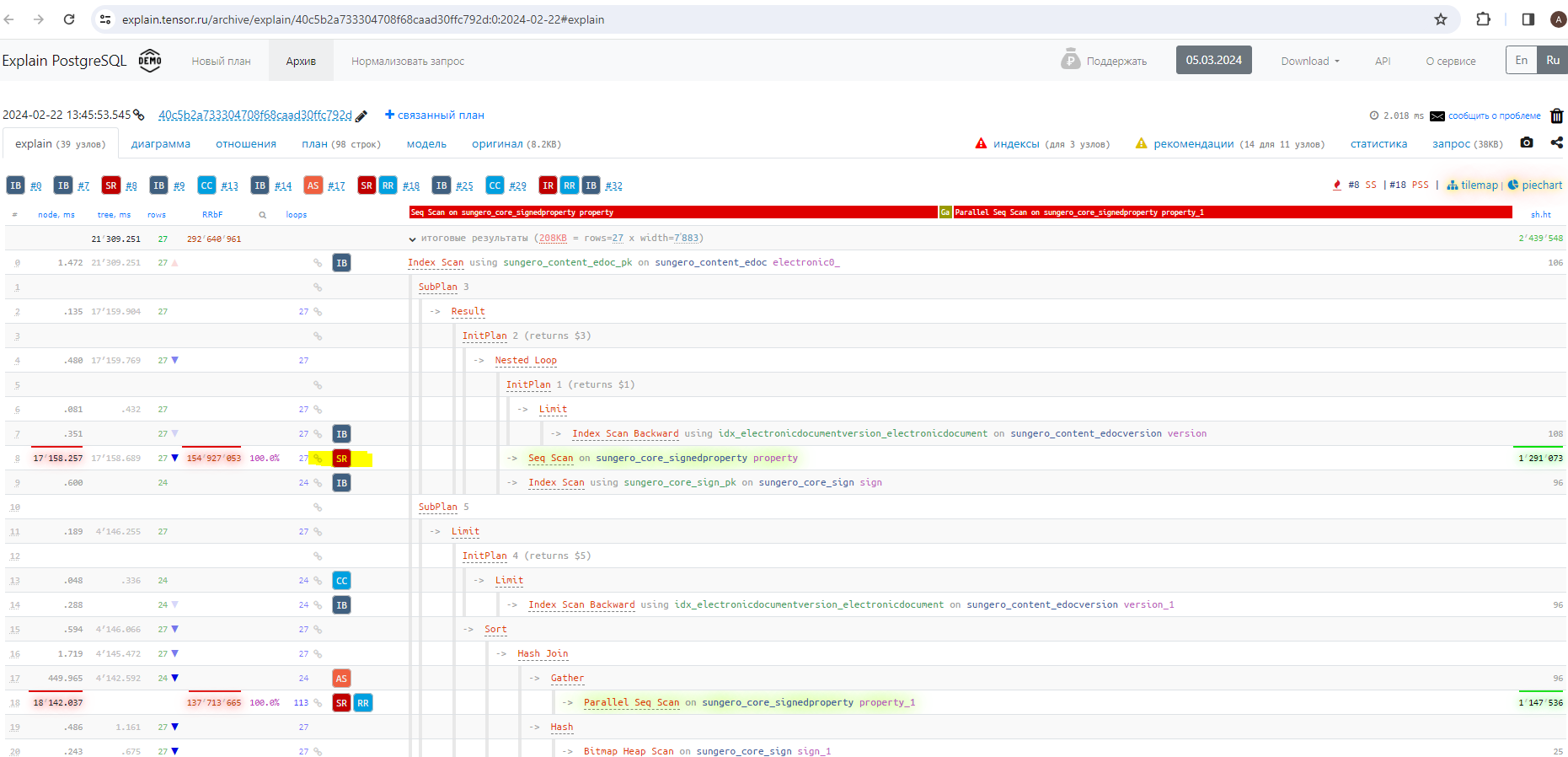
2.3.2. Зачем нужны индексы
Индексы в PostgreSQL могут значительно ускорить выполнение запросов, особенно тех, которые включают операции выборки по ключам или фильтрацию данных. Однако с индексами также связано несколько потенциальных проблем, которые могут негативно сказаться на производительности и управляемости базы данных:
- производительность операций записи: вставки, обновления и удаления становятся медленнее, так как каждый индекс, связанный с таблицей, должен быть обновлен при изменении данных. Чем больше индексов на таблице, тем больше времени необходимо для выполнения этих операций;
- использование дискового пространства: индексы занимают дополнительное дисковое пространство. В зависимости от количества и типа индексов, это может значительно увеличить общую потребность в дисковом пространстве;
- планирование запросов: слишком большое количество индексов может усложнить работу планировщика запросов (Query Planner). В некоторых случаях это может привести к выбору неоптимальных планов выполнения запросов.
2.3.3. Создание индекса
Для создание индексов в PostgreSQL нам нужно выполнить запрос, который выдал explain.tensor.ru (выделен на скриншоте) в postgresql.
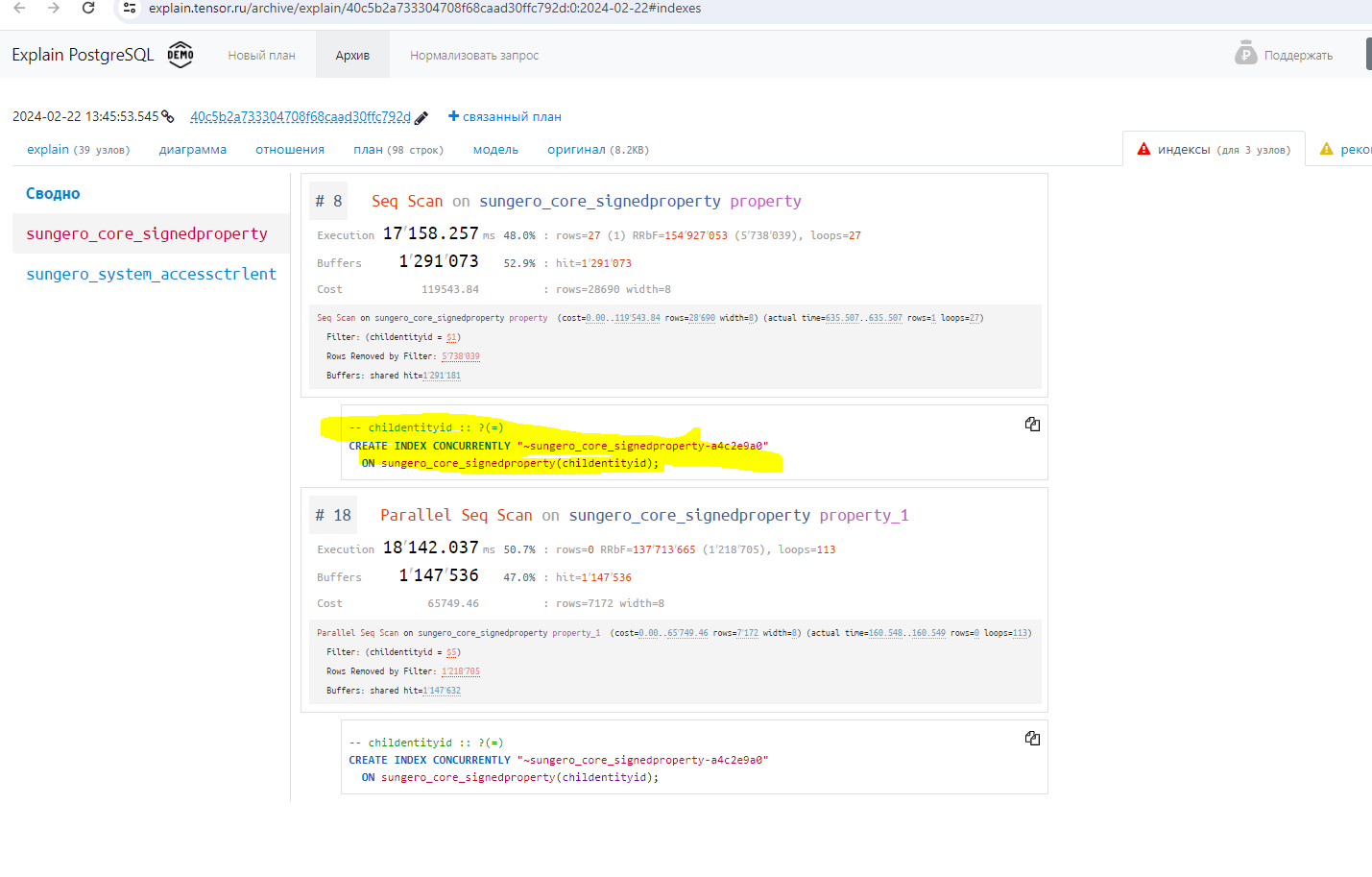
После создания индекс, быстродействие данного селекта увеличилось примерно в 12 раз.
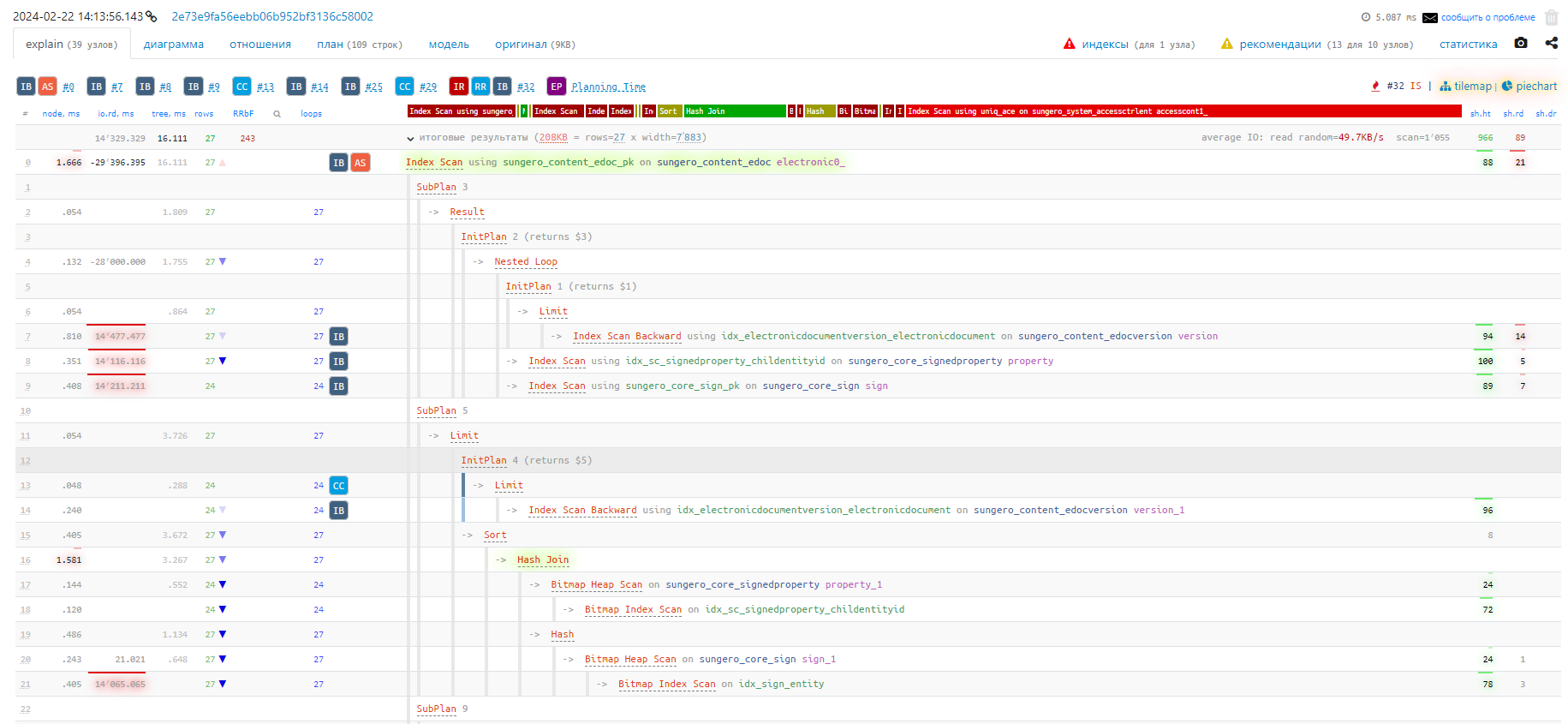
Так выглядит план запроса после создания индекса: ссылка
3. Автообслуживание
Автообслуживание в PostgreSQL включает в себя механизм под названием autovacuum. Это фоновый процесс в PostgreSQL, который автоматически выполняет команды VACUUM и ANALYZE на ваших таблицах.
3.1. Зачем это нужно?
Этот инструмент играет ключевую роль в поддержании производительности и стабильности базы данных за счет следующих функций:
- Очистка мертвых строк: при каждом обновлении или удалении строк в PostgreSQL старые версии строк остаются в таблице до тех пор, пока не будет выполнен VACUUM. Эти мертвые строки занимают место и могут замедлить производительность системы.
- Обновление статистики: Команда ANALYZE обновляет статистику распределения данных в таблицах. Эта информация критически важна для оптимизатора запросов, который использует статистику для выбора наилучшего плана выполнения запросов.
3.2. Настройка autovacuum
Все настройки производятся в конфигурационном файле postgresql.conf
- Первым делом необходимо включить данный параметр:
autovacuum = on - Следующий параметр отвечает за то, сколько фоновых процессов будет вакуумировать. Вакуум затрагивает не только таблицы, но и индексы. В качестве значения autovacuum_max_workers нужно указывать примерно половину имеющегося количества ядер. По умолчанию значение равно 3.
autovacuum_max_workers - Данный параметр считает суммарную стоимость работы каждого воркера (по умолчанию равна 400). Например, он прочитал страницу – это стоит один балл. Он удалил запись с этой странички, это стоит 5 баллов. Воркеров по умолчанию – 3. Если мы увеличиваем количество воркеров autovacuum_max_workers в 2 раза, то нам нужно увеличить и стоимость autovacuum_vacuum_cost_limit в два раза.
autovacuum_vacuum_cost_limit - Когда ВСЕ воркеры наберут в сумме своей работы 400 баллов, они встанут в паузу, которая указана в настройке autovacuum_vacuum_cost_delay. Они все остановятся, подождут 20 миллисекунд и опять начнут дальше убираться. Это сделано для того, чтобы система «продышалась».
autovacuum_vacuum_cost_delay - По умолчанию, настройка autovacuum_vacuum_scale_factor, при которой AutoVacuum сработает на таблице, равна 10% (т.е. с последнего AutoVacuum в этой таблице должно поменяться 10% строк). С данным параметром нужно экспериментировать, подбирать опытным путём.
autovacuum_vacuum_scale_factor - По умолчанию равен 20%. Т.е. PG статистику по умолчанию посчитает только после изменения 20%.
autovacuum_analyze_scale_factor
3.2.1. Пример конфигурации
autovacuum = on
autovacuum_max_workers = 8
autovacuum_vacuum_cost_limit = 2400
autovacuum_vacuum_cost_delay = 20ms
autovacuum_vacuum_scale_factor = 0.01
autovacuum_analyze_scale_factor = 0.005
3.3. Мониторинг процессов autovacuum
select count(1) from pg_stat_progress_vacuum;
Данный запрос выдаст количество процессов автовакуума, которые работают на момент выполнения этого запроса. Результат этого запроса в среднем за рабочее время должен быть меньше вашей настройки максимального количества воркеров. Работа воркеров должна занимать 1-2 процента рабочего времени базы данных. Не больше. Если это не так, вы не подобрали оптимальные настройки: либо переборщили с резкостью настроек, либо недостаточно выделили воркеров.
SELECT schemaname, relname, last_vacuum, last_autovacuum FROM pg_stat_all_tables;
Данный запрос выведет информацию о времени последнего вакуума и автовакуума, а также таблицы, над которым выполнялась операция. Мониторинг длительности операций и запросов. В этом нам поможет отчёт pg_profile.
Авторизуйтесь, чтобы написать комментарий