Отказоустойчивый кластер Elasticsearch для полнотекстового поиска
Работая в компании СТАРКОВ Групп системным инженером уже 1,5 года, я не так давно задался вопросом о том, как построить отказоустойчивый кластер Elasticsearch, который работал бы в кворуме из 3 нод, и прикрутить его к Directum RX.
Предыстория
Насколько я знаю, приложения пишут сразу под возможность использования кластера Elasticsearch, а вот в документации Directum RX я не нашел ничего о кластеризации данного решения и решил немного поэксперементировать в этом направлении.
Важно понимать, что Elasticsearch, даже будучи в единственном экземпляре - это тоже кластер, только из одной ноды.
Перед собой я поставил следующие задачи:
1) Собрать кластер Elasticsearch из 3 нод;
2) Собрать кластер Haproxy и Keepalived из 2 нод;
3) Протестировать работоспособность кластера при падении 1 ноды.
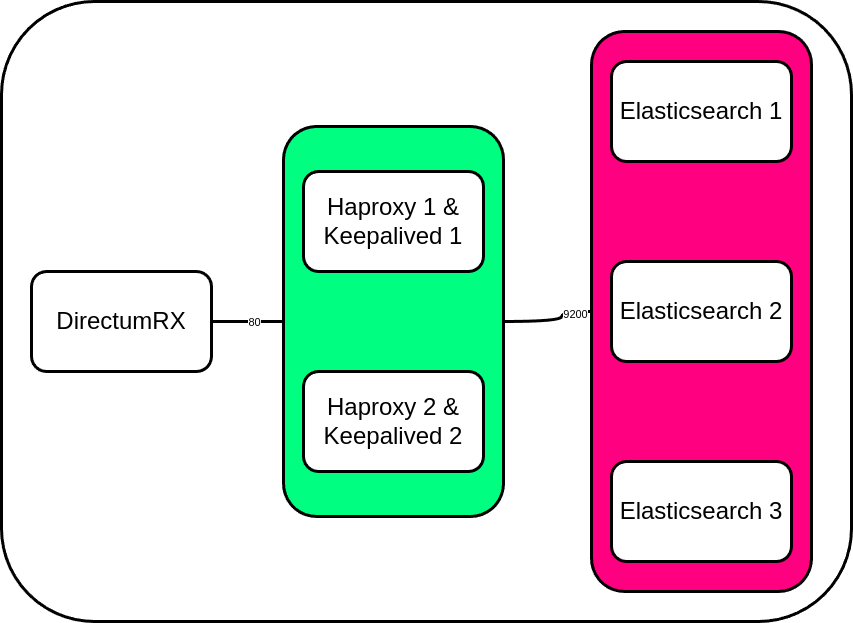
Версии компонентов:
1) DirectumRX - 4.9.153;
2) Elasticsearch - 7.16.3;
3) Keepalived - 2.2.4;
4) Haproxy - 2.4.24;
5) Ubuntu 22.04.5.
IP адреса серверов:
1) Elasticsearch:
1 нода - 192.168.0.106
2 нода - 192.168.0.156
3 нода - 192.168.0.157
2) Haproxy и Keepalived:
1 нода - 192.168.0.159
2 нода - 192.168.0.160
3) DirectumRX:
1 нода - 192.168.0.158
И так, начнем.
Настройка кластера Elasticsearch
Первым делом соберем кластер Elasticsearch. Если вы раньше этого не делали, то ничего страшного. Все намного проще, чем может показаться.
Подготавливаем 3 виртуальные машины, настраиваем их как нам необходимо.
Я обычно добавляю параметр vm.max_map_count=655360 в /etc/sysctl.conf и определяю лимиты в /etc/security/limits.conf:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
Устанавливаем Elasticsearch требуемой версии на все 3 ноды и выполняем:
systemctl daemon-reload
systemctl enable elasticsearch
После этого настраиваем Elasticsearch согласно справки Directum, а именно: добавляем плагины и подкидываем файл с синонимами в /etc/elasticsearch на всех нодах будущего кластера.
Пока ничего не запускаем. Делать это мы будем только после настройки файлов конфигурации.
1. На всех нодах выставляем параметры -Xms<count>g -Xmx<count>g в конфигурационном файле jvm.options. По умолчанию он лежит по пути /etc/elasticsearch/jvm.options.
Например, если мы хотим чтоб наш Elasticsearch использовал 10Гб оперативной памяти, укажем эти параметры следующий образом:
-Xms10g
-Xmx10g
2. Идем на 1 ноду, открываем конфигурационный файл elasticsearch.yml (По умолчанию он лежит там же, где и jvm.options). Вносим следующее содержимое:
# Указываем имя кластера и имя ноды
cluster.name: my-application
node.name: node-1
# Задаем путь к данным
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
# Разрешаем слушать на всех интерфейсах
network.host: 0.0.0.0
# Указываем ip адрес 1 ноды
cluster.initial_master_nodes: ["192.168.0.106"]
# Отключаем GeoIP
ingest.geoip.downloader.enabled: false
# Отключаем модуль безопасности X-Pack
xpack.security.enabled: false
# Указываем на каких сетевых интерфейсах слушать HTTP-соединения Elasticsearch
http.host: 0.0.0.0
# Указываем на каких сетевых интерфейсах будет слушать транспортный протокол Elasticsearch
transport.host: 0.0.0.0
3. Запускаем Elasticsearch командой:
systemctl start elasticsearch
4. Проверяем, что наш кластер создался командой:
curl -k http://localhost:9200/_cat/nodes?v
В ответ мы получим список нод текущего кластера.
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.106 15 97 1 0.02 0.02 0.00 cdfhilmrstw * node-1
Проверить текущее состояние кластера можно командой:
curl -k http://localhost:9200/_cat/health?v
5. Теперь мы должны подключить к нашему кластеру еще 2 ноды. Для этого открываем elasticsearch.yml на всех нодах и дописываем необходимые данные:
1 нода
cluster.name: my-application
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
cluster.initial_master_nodes: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
discovery.seed_hosts: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
http.host: 0.0.0.0
transport.host: 0.0.0.0
2 нода
cluster.name: my-application
node.name: node-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
cluster.initial_master_nodes: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
discovery.seed_hosts: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
http.host: 0.0.0.0
transport.host: 0.0.0.0
3 нода
cluster.name: my-application
node.name: node-3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
cluster.initial_master_nodes: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
discovery.seed_hosts: ["192.168.0.106", "192.168.0.156", "192.168.0.157"]
ingest.geoip.downloader.enabled: false
xpack.security.enabled: false
http.host: 0.0.0.0
transport.host: 0.0.0.0
Как видите, мы добавили еще 2 ip адреса в параметр cluster.initial_master_nodes.
Эти ip адреса соответствуют 2 другим нодам нашего кластера. Данный параметр используется для определения списка нод, которые могут стать мастерами в кластере.
Мы также добавили новый параметр discovery.seed_hosts и указали в него все тот же перечень ip адресов нашего кластера. Он используется для указания списка ip адресов нод, которые могут быть использованы для обнаружения других нод в кластере.
6. Теперь запускаем 2 и 3 ноду:
systemctl start elasticsearch
7. После того, как 2 и 3 ноды запустились, перезапускаем 1 ноду - она же мастер:
systemctl restart elasticsearch
При внесении правок в конфигурационные файлы, обычно рекомендуют мастер-ноду перезапускать в последнюю очередь, чтоб не вызвать неожиданных ошибок.
8. Проверяем работоспособность нашего кластера командами:
curl -k http://localhost:9200/_cat/nodes?v
curl -k http://localhost:9200/_cat/health?v
Вывод должен быть примерно таким:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.157 33 96 0 0.00 0.01 0.00 cdfhilmrstw - node-2
192.168.0.102 14 95 0 0.00 0.00 0.00 cdfhilmrstw - node-1
192.168.0.156 53 97 0 0.02 0.01 0.00 cdfhilmrstw * node-3
И таким:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1730297270 14:07:50 my-application green 3 3 7 3 0 0 0 0 - 100.0%
Во втором выводе важно отметить столбец status, именно он говорит нам о том, как чувствует себя наш кластер. Если статус green, значит все хорошо.
На этом подготовка кластера Elasticsearch завершена. Переходим к настройке Haproxy и Keepalived.
Настройка кластера Haproxy и Keepalived
Здесь все еще проще, и я уверен что вы все это делали не один раз. Однако я немного проговорю некоторые нюансы.
1. Первым делом на серверах выделенных под этот кластер внесем некоторые изменения в настройки параметров ядра системы.
Идем в /etc/sysctl.conf и добавляем пару параметров:
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1 #этими двумя строками отключаем IPv6 net.ipv4.ip_nonlocal_bind = 1 #позволяет отдельным локальным процессам выступать от имени внешнего (чужого) IP-адреса
net.ipv4.conf.all.arp_ignore = 1 #отвечать на ARP-запрос только в том случае, если целевой IP-адрес является локальным, сконфигурированным на входящем интерфейсе
net.ipv4.conf.all.arp_announce = 1 #избегать локальных адресов, которые отсутствуют в целевой подсети этого интерфейса
net.ipv4.conf.all.arp_filter = 0 #выключает связывание IP-адреса с ARP-адресом
net.ipv4.conf.ens160.arp_filter = 1
Кое-что тут нужно будет подправить, оставлю вам небольшую пасхалку на подумать.
После того как закончили вносить правки, применяем их:
sysctl -p
2. Настраиваем master-ноду Keepalived, создаем файл по пути /etc/keepalived/keepalived.yml и вносим в него следующее:
global_defs {
notification_email {
palchikov@starkovgrp.ru
smtp_connect_timeout 30
enable_traps
}
}
vrrp_script haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VRRP1 {
state MASTER # Говорим что наша нода будет мастером
interface enp0s3 # Указываем интерфейс
virtual_router_id 69
priority 50 # Приоритет должен быть выше чем на backup ноде
advert_int 1
garp_master_delay 10
debug 1
authentication {
auth_type PASS
auth_pass 1066
}
unicast_src_ip 192.168.0.159 # Указываем ip адрес master ноды
unicast_peer {
192.168.0.160 # Указываем ip адрес backup ноды
}
virtual_ipaddress {
192.168.0.161/24 brd 192.168.0.255 scope global # Задаем параметры виртуального ip адреса
}
track_script {
haproxy
}
}
3. Настраиваем backup-ноду Keepalived, создаем файл по пути /etc/keepalived/keepalived.yml и вносим в него следующее:
global_defs {
notification_email {
palchikov@starkovgrp.ru
smtp_connect_timeout 30
enable_traps
}
}
vrrp_script haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VRRP1 {
state BACKUP # Говорим что наша нода будет бэкапом
interface enp0s3 # Указываем интерфейс
virtual_router_id 69
priority 49 # Указываем приоритет ниже чем у мастера
advert_int 1
garp_master_delay 10
debug 1
authentication {
auth_type PASS
auth_pass 1066
}
unicast_src_ip 192.168.0.160 # Указываем ip адрес backup ноды
unicast_peer {
192.168.0.159 # Указываем ip адрес master ноды
}
virtual_ipaddress {
192.168.0.161/24 brd 192.168.0.255 scope global
}
track_script {
haproxy
}
}
4. Следующий этап - настроить Haproxy.
Конфигурация на обоих серверах должна быть идентична. У меня получилось следующее, но в реалиях конкретного случая конфигурация может меняться:
frontend haproxy_test
bind *:80
mode http
default_backend haproxy_backend
backend haproxy_backend
mode http
balance source
option http-server-close
option httpchk
server el01 192.168.0.102:9200 check
server el02 192.168.0.156:9200 check
server el03 192.168.0.157:9200 check
Как вы видите, указана балансировка типа Source. Это алгоритм балансировки, при котором активный сервер всегда один, а другие в ожидании. Они включаются по очереди только после выхода из строя активного сервера.
Я также настроил проверку сервисов таким образом, что Haproxy должен получать статус код 200, и если он его не получает, то переводит запросы на другую ноду кластера.
5. Запускаем Haproxy и Keepalived с помощью systemctl start ... и аналогичным образом добавим эти сервисы в автозагрузку.
6. Проверяем, что все у нас работает корректно. Для этого мы идем на мастер-ноду и вводим команду ip a:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:43:22:4d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.159/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.0.161/24 brd 192.168.0.255 scope global secondary enp0s3
valid_lft forever preferred_lft forever
Мы сразу видим наш виртуальный ip адрес.
Вводим эту же команду на бэкап-ноде:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:f3:7d:8b brd ff:ff:ff:ff:ff:ff
inet 192.168.0.160/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
Виртуальный ip не указан, значит пока все работает так, как мы и предполагали.
Далее отключаем Haproxy на мастер-ноде:
systemctl stop haproxy
И еще раз проверяем ip адреса на обеих нодах:
Мастер-нода:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:43:22:4d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.159/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
Бэкап-нода:
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:f3:7d:8b brd ff:ff:ff:ff:ff:ff
inet 192.168.0.160/24 brd 192.168.0.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet 192.168.0.161/24 brd 192.168.0.255 scope global secondary enp0s3
valid_lft forever preferred_lft forever
Магия, не иначе... Идем дальше)))
Первоначальное индексирование в DirectumRX
Рассказывать и показывать как устанавливается и настраивается DirectumRX я думаю смысла нет, однако следует отметить, что в параметре ELASTICSEARCH_URL секции common_config мы указываем наш виртуальный ip адрес и порт, который слушает наш Haproxy. У меня получилось примерно вот так:
ELASTICSEARCH_URL: 'http://192.168.0.161:80'
Создаем в системе какие-нибудь документы, если они были не созданы и/или проводим первоначальное индексирование:
./do.sh initialindexing run --command="-d"
Если мы понимаем, что размер наших индексов будет достаточно большой, мы можем настроить шарды и количество реплик по инструкции Directum "Администрирование (Linux) > Общесистемные настройки > Настройка полнотекстового поиска". Однако у меня реализовать этот функционал не получилось. С чем связано, не знаю.. либо у меня руки кривые, либо еще что... Если у вас был положительный опыт в этом направлении, жду обратную связь. А пока идем дальше...
Проверки и тесты
После проведения первоначального индексирования мы возвращаемся к нашему кластеру Elasticsearch и смотрим что получилось:
curl -k http://localhost:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open rxsearch_document_test_test fitUwqoAQ9msz-ugTLVweQ 1 0 85 0 459.8kb 459.8kb
В данном выводе мы видим, что у нас создался 1 индекс и находится в статусе green. Он также имеет 1 шард и 0 реплик (значения по умолчанию).
Посмотрим, что у нас с шардами происходит:
index shard prirep state docs store ip node
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.156 node-3
rxsearch_document_test_test 0 p STARTED 85 459.8kb 192.168.0.156 node-3
Здесь мы видим, что есть 1 шард, без реплик и заодно видим, на какой ноде находится.
А тут возникает вопрос: а зачем мы создавали еще 2 ноды, если шард один, а реплик нет вообще? Давайте создадим реплики!
Вбиваем команду:
curl -X PUT -k http://localhost:9200/rxsearch_document_test_test/_settings -H 'Content-Type: application/json' -d '{"index" : { "number_of_replicas": 2}}'
После указания порта вписываем имя индекса, а в параметре number_of_replicas вбиваем количество реплик. Я задам 2 реплики.
Проверяем:
index shard prirep state docs store ip node
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 85 459.8kb 192.168.0.157 node-2
rxsearch_document_test_test 0 p STARTED 85 459.8kb 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 85 459.8kb 192.168.0.102 node-1
Наши реплики распространились по двум другим нодам кластера. Этого мы и добивались.
Теперь создадим документ в DirectumRX с кодовым словом Опоки и проверим, проиндексировался ли он.
Проверяем работу полнотекстового поиска:
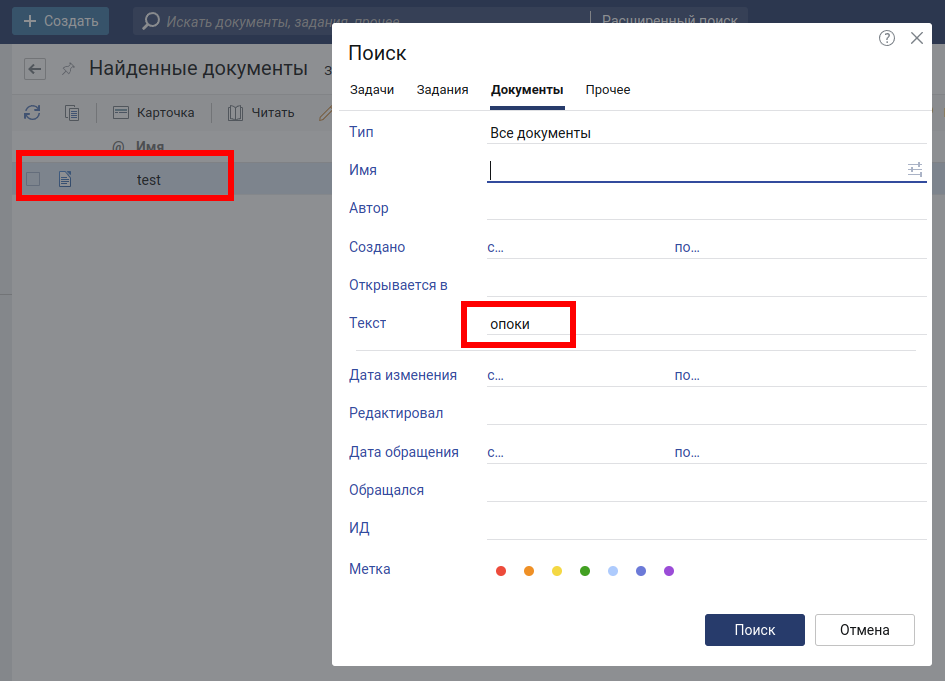
Вот он наш документ. Пока все нормально, идем дальше.
Смотрим, что происходит на сервере с Elasticsearch:
# Проверка до создания документа
root@el02:/home/user# curl -k http://localhost:9200/_cat/shards?v
index shard prirep state docs store ip node
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 85 459.8kb 192.168.0.157 node-2
rxsearch_document_test_test 0 p STARTED 85 459.8kb 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 85 459.8kb 192.168.0.102 node-1
# Проверка после создания документа
root@el02:/home/user# curl -k http://localhost:9200/_cat/shards?v
index shard prirep state docs store ip node
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 86 468.4kb 192.168.0.157 node-2
rxsearch_document_test_test 0 p STARTED 85 459.8kb 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 85 459.8kb 192.168.0.102 node-1
Здесь мы видим, что документ был проиндексирован и, судя по выводу, он находится на 2 ноде. Данные будут синхронизированы через какое-то время. Я жду еще 5 секунд, и проверяю:
index shard prirep state docs store ip node
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 86 468.5kb 192.168.0.157 node-2
rxsearch_document_test_test 0 p STARTED 86 468.5kb 192.168.0.156 node-3
rxsearch_document_test_test 0 r STARTED 86 468.5kb 192.168.0.102 node-1
Все круто! Данные синхронизированы, все работает корректно.
А что будет, если отключить 1 из нод? Например ту, где находится наш шард. В данный момент, наш шард лежит на 3 ноде. Выключаем ее и проверяем, что у нас произойдет:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.0.102 63 96 0 0.19 0.06 0.01 cdfhilmrstw - node-1
192.168.0.157 40 97 3 0.19 0.07 0.02 cdfhilmrstw * node-2
Количество нод - 2, ожидаемо.
Проверим статус кластера:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1730301561 15:19:21 my-application yellow 2 2 6 3 0 0 1 0 - 85.7%
Статус кластера yellow. Пока он функционирует нормально, но если вывести из строя еще одну ноду, кластер разрушится.
Проверим статус индекса:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open rxsearch_document_test_test fitUwqoAQ9msz-ugTLVweQ 1 2 86 0 937.1kb 468.5kb
Статус индекса yellow. В данный момент это связано с тем, что он не может разместить вторую реплику в данном кластере.
Убедимся в этом:
index shard prirep state docs store ip node
rxsearch_document_test_test 0 p STARTED 86 468.5kb 192.168.0.157 node-2
rxsearch_document_test_test 0 r STARTED 86 468.5kb 192.168.0.102 node-1
rxsearch_document_test_test 0 r UNASSIGNED
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.102 node-1
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
Видим, что одна реплика перешла в положение UNASSIGNED. И обратите внимание, что шард переехал на 2 ноду.
Проверим работоспособность кластера из системы Directum RX:
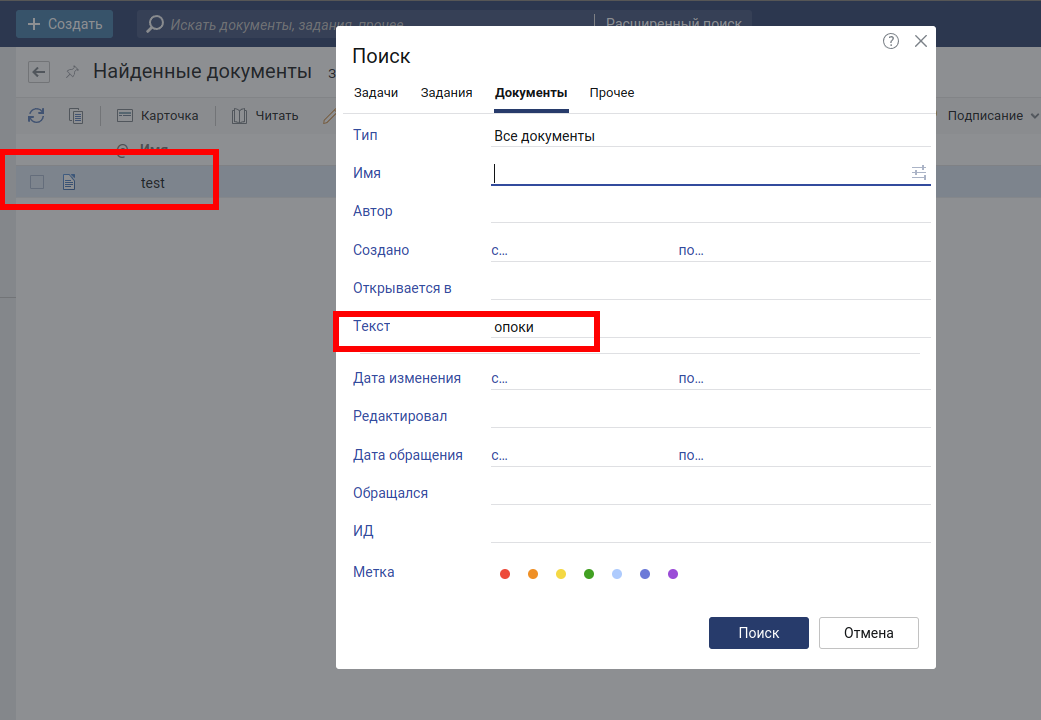
Успех! Документ найден, и все работает корректно.
Теперь добавим новый документ и проверим, добавится ли он в кластер. Для этого создадим документ из того же файла, только назовем его test2.
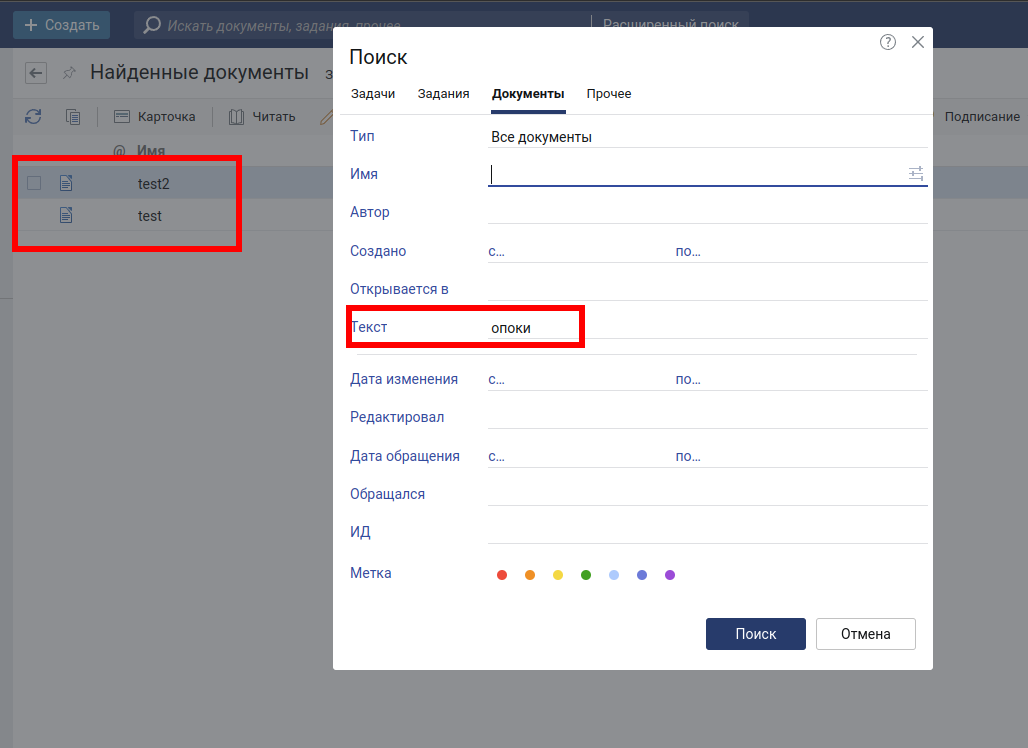
Документ проиндексировался, все нормально.
Включаем 3 ноду и проверяем, что документ синхронизировался в кластере:
index shard prirep state docs store ip node
rxsearch_document_test_test 0 p STARTED 87 477.2kb 192.168.0.157 node-2
rxsearch_document_test_test 0 r STARTED 87 477.2kb 192.168.0.102 node-1
rxsearch_document_test_test 0 r STARTED 87 477.3kb 192.168.0.156 node-3
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 p STARTED 192.168.0.157 node-2
.ds-.logs-deprecation.elasticsearch-default-2024.10.30-000001 0 r STARTED 192.168.0.156 node-3
.ds-ilm-history-5-2024.10.30-000001 0 r STARTED 192.168.0.157 node-2
.ds-ilm-history-5-2024.10.30-000001 0 p STARTED 192.168.0.102 node-1
Видим, что реплика снова добавлена и система работает стабильно. А также видим, что счетчик документов обновился:
root@el02:/home/user# curl -k http://localhost:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open rxsearch_document_test_test fitUwqoAQ9msz-ugTLVweQ 1 2 87 0 1.3mb 477.2kb
root@el02:/home/user# curl -k http://localhost:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1730302325 15:32:05 my-application green 3 3 7 3 0 0 0 0 - 100.0%
Заключение
Данное решение выглядит немного костыльным и работает не совсем так, как мы привыкли ожидать от кластера Elasticsearch. Однако следует отметить, что если стоит задача обеспечить отказоустойчивый кластер полнотекстового поиска, то данный подход можно смело использовать в проектах.
Авторизуйтесь, чтобы написать комментарий