Переезжаем с Microsoft SQL Server на PostgreSQL
Тема перехода с MS SQL Server на PostgreSQL в связи с импортозамещением не теряет своей актуальности и довольно часто встает вопрос о методах и средствах такой миграции. Предлагаю свой способ переезда на PG, реализованный на БД Directum RX Евразийского Национального Университета.
«Вставая на плечи атлантов»
На гильдии разработчиков «Конвертация базы данных с Microsoft SQL Server на PostgreSQL» за авторством Дерюшева Алексея был описан метод миграции базы данных с одной СУБД на другую. В описанном способе используется стороннее ПО, некоторые компоненты которого условно бесплатные (Pentaho Data Integration), а некоторые (JRE) «условно безопасные», и не каждого клиента удастся уговорить установить их на сервер для проведения работ. (Опять же – вспоминаем про импортозамещение). Можно, конечно, создать для этих целей свою виртуальную машину, но перетащит на нее дамп базы нам могут запретить исходя из политики защиты данных. К тому же весь сторонний софт требует ручной настройки посредством конфигурационных файлов. Да и сам процесс конвертации описанный на гильдии напрашивается на более высокий уровень автоматизации.
Directum RX все сделал за нас!
Но ведь, по сути, проводя подготовку к конвертации, большую часть проблемы мы уже возложили на сам Directum RX? Пакет разработки, собранный в среде, поддерживаемой СУБД MS SQL свободно переезжает в RX на PG SQL, (при этом RX сгенерирует и выполнит нужные скрипты для создания схемы БД). Среды разработки, естественно, должны иметь аналогичные версии, а кастомные решения адаптированы под PostgreSQL (процесс адаптации широко освещен в различных материалах, и здесь заострять внимание на нем не имеет смысла). При соблюдении этих условий, после публикации пакета разработки и процесса инициализации мы получаем схему БД, необходимую для рабочей целевой системы. Таким образом RX уже сделал самую главную часть работы – создал скелет будущей базы данных, и остается дело за малым — скопировать данные.
Проблемы внешних связей
Так как речь идет о реляционной БД, в процессе копирования данных мы столкнемся с некоторыми нюансами, в частности, при наличии в схеме внешних ключей (CONTRAINT типа FOREIGN KEY) копирование будет невозможно, так как ссылочные поля копируемой таблицы будут указывать «в пустоту», нарушая правила ограничений. Проблему можно решить, удалив из схемы внешние ключи, а после копирования данных восстановив их. Сделать это можно прочитав список констрейнтов из представления, любезно предоставленного нам разработчиками Postgres, и сохранив его в файл. После переноса данных на основе списка ключей из файла создаются и выполняются скрипты для их генерации, что восстанавливает целевую базу в статусе реляционной.
Есть способ скопировать данные, не удаляя FK – отключить все триггеры в БД до копирования (для каждого FK при его создании добавляется скрытый триггер, который и отслеживает выполнение условий ограничения). Данный способ нам не подходит по тому, что отключенный триггер не отслеживает целостность данных в самом FK, и когда мы его включим обратно - получим на выходе «битые ссылки» (если таковые имелись в ресурсной БД).
Берем больше, кидаем дальше!
Второй нюанс заключается в самом копировании данных. Естественно, что подход на уровне полей таблицы через команду INSERT для нас не приемлем, такая реализация громоздка с точки зрения разработки, и не оптимальна с точки зрения времени выполнения. А что, если призвать на помощь мощности класса NpgsqlBinaryImporter из арсенала библиотеки Npgsql? (Упомянутой библиотекой пользуется и сам RX). Данный «импортер» подходит к строке таблицы, как к массиву объектов бинарных данных, извлекая строку из ресурсной таблицы и вставляя в целевую. Скорость копирования при таком подходе в одиночном процессе при самых скромных ресурсах машины составляет менее 1 часа на 100 ГБ данных.
При всех удобствах и мощности метод имеет один подводный камень, а именно – поля целевой и ресурсной таблиц должны строго совпадать по порядку расположения, иначе, если даже копирование строки состоится, целевые данные могут быть искажены. СУБД лояльна к любому порядку следования полей в таблице, и этот порядок может изменяться по мере модификации сущности в DDS, конвертации базы данных при переходе на новые версии (всем известное EntityVersion, например, а также, перевода идентификаторов с типа int на bigint). Данный факт делает копирование данных без предварительного упорядочивания полей невозможным. Для решения проблемы были выбраны два средства из арсенала SQL– DROP TABLE и CREATE TABLE для целевой таблицы, что может быть проще, тем более, что она пустая? (Здесь я отнюдь не претендую на истину, возможно, проблему можно решить другим способом, и я с радостью выслушаю замечания на этот счет). Ясно, что данный механизм подразумевает под собой сравнение порядка следования полей в таблицах и генерацию скриптов для создания таблиц, но это с лихвой окупается на стадии копирования данных, и база размером в 1ТБ становится вполне переездной за выходные.
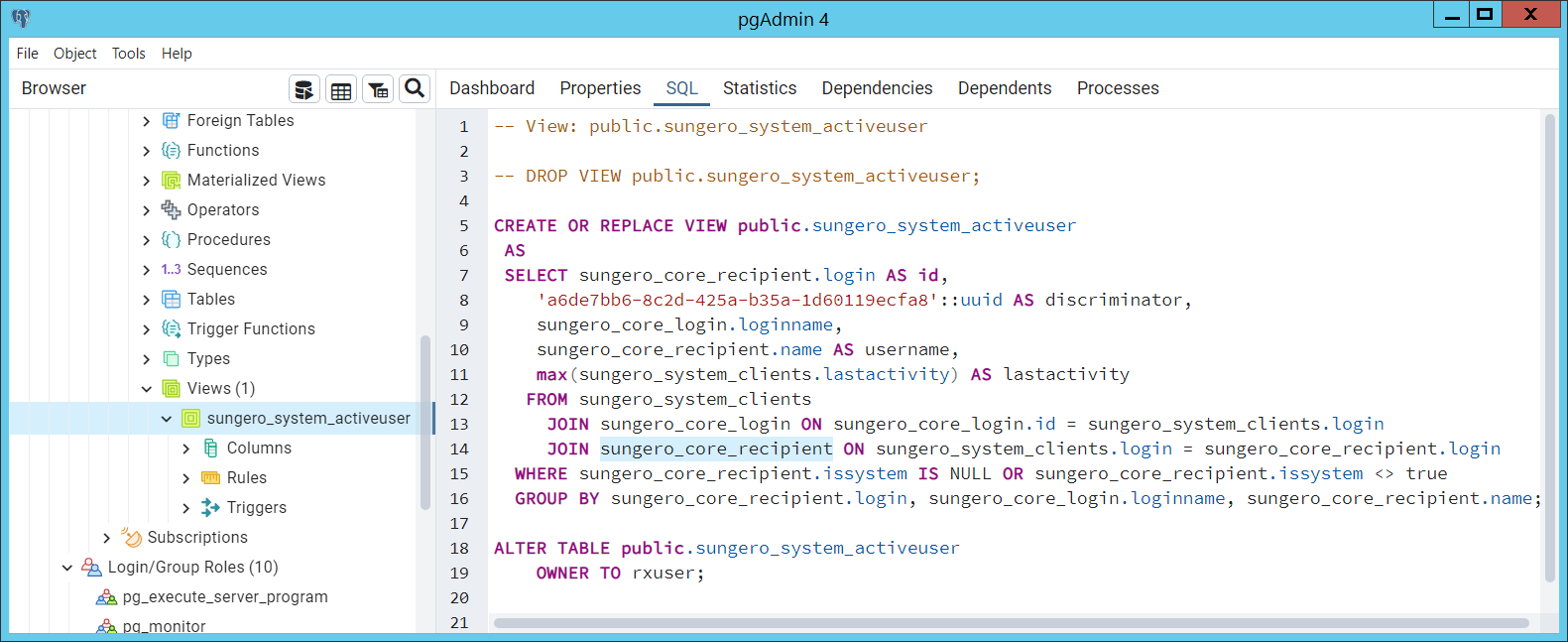
Также необходимо учесть, что представления (View), которые связываю данные из разных таблиц между собой, помешают удалению таблиц. Следовательно, придется позаботиться о сохранении скриптов генерации представлений, удалить их из схемы до выполнения скриптов переформирования таблиц, и восстановить уже после генерации новых таблиц. Если View в базе не создавались разработчиками, по крайней мере одно из нематериализованных представлений мы уже имеем — коробочное представление RX — Sungero_System_Activeuser.
Автоматически формируемые скрипты приложение сохраняет в папке «\\Scripts» рабочего каталога (того, что был выбран в оконном конфигураторе). Расположить файлы скриптов удаления представлений нужно таким образом, чтобы они в списке файлов шли до скриптов генерации таблиц, а скрипты генерации View должны следовать за скриптами таблиц, что можно обеспечить именованием файлов (для скриптов удаления View имена файлов необходимо начать с цифр, например — «00_DropActiveUserView», а имена файлов со скриптами генерации представлений, нужно начать с нескольких z — «zz_CreateActiveUserView» (файлы в папке сортируются по наименованию).
Естественно, все эти действия можно пропустить, если в процессе конвертации не будут перестраиваться таблицы, затронутые представлением (sungero_system_clients, sungero_core_login, sungero_core_recipient). Скрипты генерации View можно подсмотреть в pgAdmin, выбрав представление в дереве объектов базы и перейдя на вкладку SQL.
Что мы будем делать?
Проверяем адаптацию разработки под PostgreSQL, вспоминаем все объекты базы, которые создавали вручную и хотим захватить их с собой при переезде, если такие имеются, пишем скрипты для их генерации вручную, соблюдая синтаксис psql. Устанавливаем среду разработки на Postgres (версии должны совпадать), принимаем пакет разработки и выполняем инициализацию разработки (машина должна иметь доступ к исходной СУБД). Здесь наступает самое время выполнить скрипты рукотворных таблиц, самодельные индексы и представления оставляем на завершающий этап работ. Создаем и разворачиваем бэкап «чистой» базы только что установленного RX на том же сервере Postgres (бэкап нам нужен на случай, если что-нибудь пойдет не так, а это обязательно случится, и, может быть, не раз)
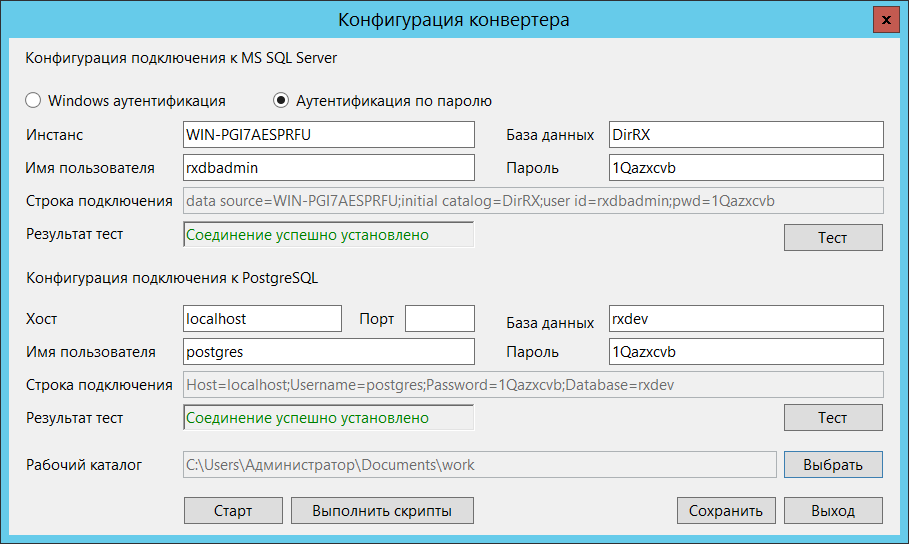
Запускаем приложение, в окошке конфигуратора указывает данные для подключения к исходной и целевой базам, а, так же, рабочую директорию. Проверяем наличие коннекта к базам и жмем кнопку «Старт». Приложение, в свою очередь:
- Сравнивает списки таблиц в ресурсной и целевой базах. (На данном этапе приложение произведет остановку, списки таблиц для копирования можно будет отредактировать в соответствующих файлах, находящихся в рабочей директории приложения).
- Сравнивает списки полей в таблицах на соответствие, если список полей в каких-то одноименных таблицах различаются, приложение завершит работу, выдав соответствующее предупреждение, так как произвести копирование данных будет невозможно. (Для повторной попытки конвертации приводим список полей проблемных таблиц в соответствие путем добавления/удаления оных - на наше усмотрение).
- Создает файлы со списками первичных ключей (PRIMARY KEY), внешних ключей (FOREIGN KEY), ограничений уникальности (UNIQUE CONSTRAINT), проверочных ограничений (CHECK CONSTRAINT), индексов (INDEX), и последовательностей (SEQUENCE).
- Удаляет внешние ключи.
- Очищает целевые таблицы от данных.
- Сравнивает порядок следования полей таблиц, при необходимости, генерирует скрипты и пересоздает целевые таблицы с нужной последовательностью полей.
- Копирует данные.
- Восстанавливает внешние ключи.
- Восстанавливает остальные ограничения.
- Перезапускает последовательности (Sequences) с нужных стартовых значений.
- Пересоздает индексы.
В конфигурационном файле переключаем среду разработки на новую базу и пробуем провести публикацию. Если публикация проходит успешно, пробуем создать новую учетную запись в клиенте. Если учетка создается успешно (без ошибок с повторением первичного ключа), значит последовательность sungero_system_passwordinfo_id_seq перезапущена верно.
Восстановление внешних ключей не всегда проходит без проблем, тем более, если исходная база относится к долгоживущим, и подвергалась разным негативным воздействиям (неполадки в кластере SSD/HDD, вирусная атака, неудачная конвертация при переходе на новую версию, и, наконец вторжение сисадминов, стремящихся исправить то, что и так работало). На этот случай пришлось предусмотреть зацикливание попытки восстановления ключа с паузой для выполнения скрипта, обнуляющего «битые ссылки», когда внешний ключ указывает на несуществующие более данные в ресурсной таблице. При этом скрипт для лечения предлагает само приложение. Суть скрипта заключается в замене битых ссылок на NULL (ибо это естественное состояние для ссылочного типа). Можно принять данное предложение, а можно подойти к проблеме более интеллектуально, заменив, например, битое поле MainTask ссылкой на самое себя для таблицы Sungero_WF_Task, а можно отложить интеллектуальный подход на потом, в любом случае, данных мы при этом не теряем (невозможно потерять одно и то же два раза).
«И увидел Он, что это хорошо…»
Приложение прошло проверку при переводе Directum RX на PostgreSQL в Евразийском Национальном Университете. База ЕНУ на MS SQL Server занимала 51 ГБ дискового пространства, после конвертации на PG «ужалась» до 19 ГБ (за счет отсутствия пустых страниц в индексах при их пересоздании с нуля), продолжительность работы приложения составила 40 минут, 19 из которых ушли на копирование данных, остальное время – на генерацию внешних ключей и индексов. Виртуальная машина, на которой проводились работы, имела одноядерный процессор и 8 ГБ оперативной памяти. При восстановлении внешних ключей было обнаружено некоторое количество «битых ссылок» вирусной этимологии (база подверглась атаке, и в ходе устранения инцидента были удалены некоторые FOREIGN KEY, что обнаружилось мной в MS SQL по ходу работ).
Подробное описание процесса работы с приложением имеется в инструкции к приложению, которое может быть передано по отдельному обращению в организацию (ООО «АрмаДок»). С удовольствием отвечу на вопросы и выслушаю замечания.
Авторизуйтесь, чтобы написать комментарий