Универсальное решение для эффективной обработки сущностей в «промышленных» объемах
Предпосылки
При переходе с Directum 5 на RX в рамках одного из проектов компании СТАРКОВ Групп наша команда столкнулась с рядом сложностей, связанных с обработкой исторических данных.
Сама миграция прошла успешно, однако уже после внедрения начали проявляться проблемы, которые по разным причинам не были учтены заранее. Для их оперативного решения мы использовали привычные инструменты: фоновые процессы, асинхронные обработчики и загрузку данных из Excel-файлов, предоставляемых заказчиком.
Под «привычными инструментами» подразумевается создание отдельного фонового процесса либо асинхронного обработчика под каждую конкретную задачу. Это стандартный и быстрый способ разработки в Directum RX, который подходит для большинства задач, когда ожидаемый объем данных не нагружает сервер и занимает приемлемое время обработки.
Основные проблемы
При работе с сотнями тысяч записей появляются ключевые трудности:
- низкая производительность фоновых процессов при больших объемах данных в однопоточном режиме;
- неконтролируемая нагрузка на сервер при использовании асинхронных обработчиков;
- ошибки частного характера, требующие анализа логов и ручного вмешательства;
- отсутствие наглядной визуализации прогресса выполнения;
- высокие трудозатраты на разработку индивидуальных решений под каждую задачу.
Стандартные инструменты (фоновые процессы, асинхронные обработчики) предоставляют базовые возможности, но не предлагают готовой инфраструктуры для массовой обработки данных. Разработчик каждый раз вынужден вручную писать сложный код для:
- параллелизации;
- управления очередями;
- обработки ошибок и блокировок;
- логирования и мониторинга прогресса.
Это не только замедляет разработку, но и делает процессы менее надежными.
При этом Directum RX «из коробки» уже имеет механизм, решающий все эти проблемы в частном порядке для правил назначения прав. Для минимизации нагрузки используется расписание фонового процесса, а количество документов в пакете и количество пакетов, для которых выдача прав должна запускаться одновременно настраиваются через конфигурационный файл. К сожалению, в этом замечательном механизме отсутствует переиспользуемая инфраструктура.
Все это привело нас к мысли о необходимости создания единого подхода — шаблонного решения для массовой обработки сущностей.
Концепция шаблона
Прежде всего следует отметить, что решение основано на стандартных подходах к проектированию, используемых в Directum RX, но объединяет их в удобный шаблон, который:
- Управляет нагрузкой — контролирует активные процессы и ограничивает нагрузку на сервер.
- Дает контроль через веб-клиент — позволяет включать и отключать процессы, настраивать лимиты.
- Обеспечивает мониторинг — отображает прогресс обработки и наличие ошибок.
- Минимизирует усилия разработчика — быстрое подключение новых процессов.
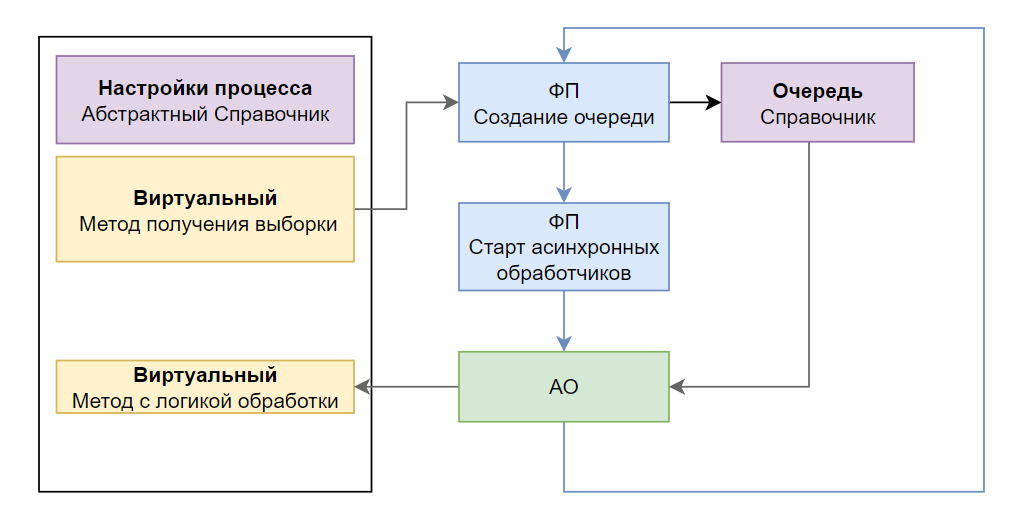
Рис.1. Упрощенная схема процесса
Пример работы с решением
Ситуация: после миграции в RX было обнаружено, что у более чем 28 000 приказов на командирование отсутствуют данные на вкладках «Командируемые» и «Организации». Требуется заполнить их из Excel-файлов, предоставленных заказчиком.
Заполняем реквизиты карточки соответствующего процесса:
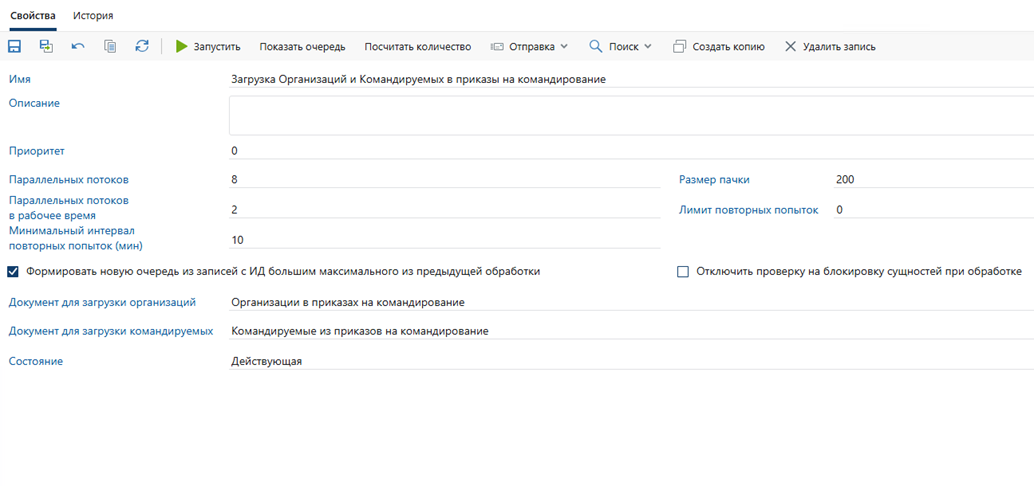
Рис.2. Пример вида карточки настройки процесса
- Приоритет — определяет порядок обработки при одновременном выполнении нескольких процессов. Чем выше приоритет, тем раньше создаются очереди для этого процесса.
- Важно: следует учитывать ограничения общего количества потоков.
- Параллельных потоков — максимальное количество одновременно работающих обработчиков для этого процесса. Ограничено общим лимитом потоков системы (хранится в БД).
- Параллельных потоков в рабочее время (опционально) — если задано, в рабочее время используется этот лимит вместо основного.
- Особенности: используются календари рабочего времени, возможно переопределение логики.
- Размер пачки — количество сущностей, обрабатываемых одним потоком за итерацию.
- Рекомендации: оптимально: 100–500. Максимум: 1000 (для ресурсоемких задач уменьшите значение).
- Лимит повторных попыток — сколько раз повторять обработку сущностей при ошибках.
- Особенности: блокировки обрабатываются автоматически (не учитываются в лимите).
- Минимальный интервал повторных попыток (мин) — минимальная задержка перед повторным запуском очереди с ошибками.
- Формировать новую очередь из записей с ИД большим максимального из предыдущей обработки — включать, если сущности не должны обрабатываться повторно.
- Эффект: исключает дублирование (выборка начинается с последнего обработанного ИД).
- Без настройки: исключаются только сущности с ошибками.
- Отключить проверку на блокировку сущностей — включать, если логика не требует блокировки объектов.
- Важно: блокировки будут обрабатываться как обычные ошибки.
- Документ для загрузки организаций/командируемых — ссылки на документы в системе, содержащие файлы с данными, которые необходимо загрузить. Эти свойства были добавлены модификацией для данной задачи.
После запуска процесс автоматически создает очередь и начинает обработку данных. Если при обработке возникли ошибки, в карточке будет отображаться уведомление.
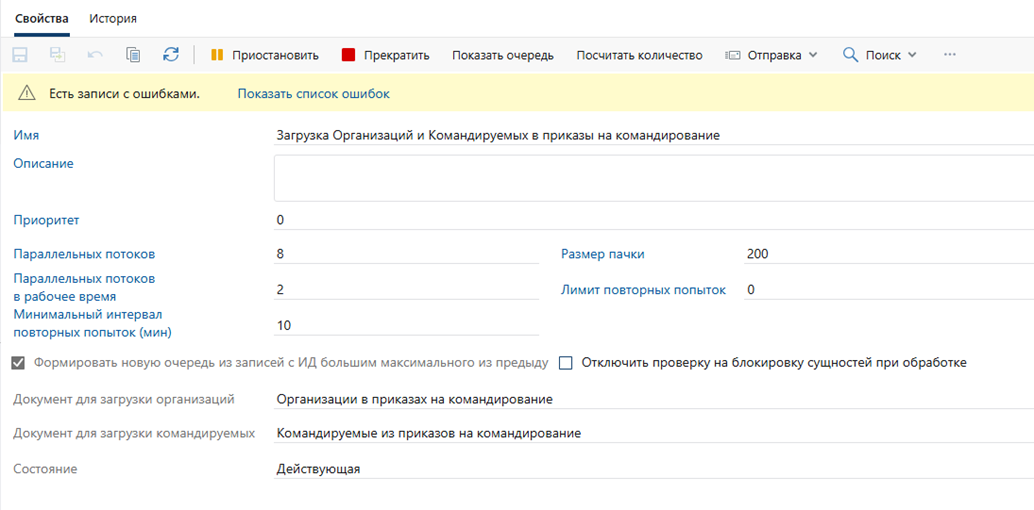
Рис.3. Уведомление о наличии ошибок.
Можно посмотреть связанные очереди по действиям "Показать очередь" или "Показать список ошибок".
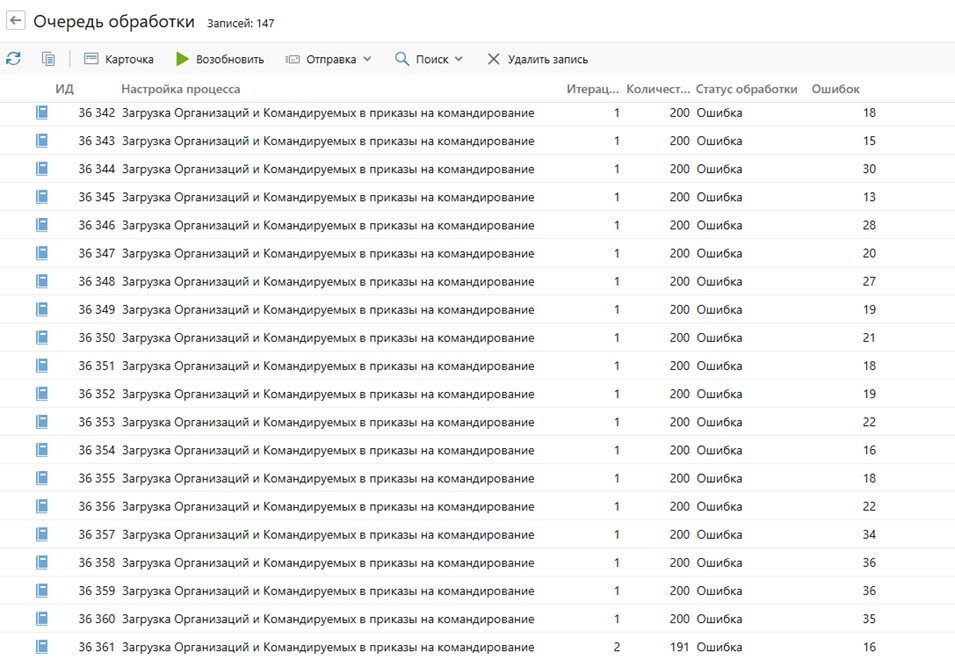
Рис.4. Список элементов очереди, связанных с настройкой
На вкладке Ошибки в карточке очереди можно перейти к деталям с указанием текста ошибки и посмотреть Stack trace. А кликнув по ссылке с идентификатором, можно открыть карточку объекта, при обработке которого возникла ошибка:
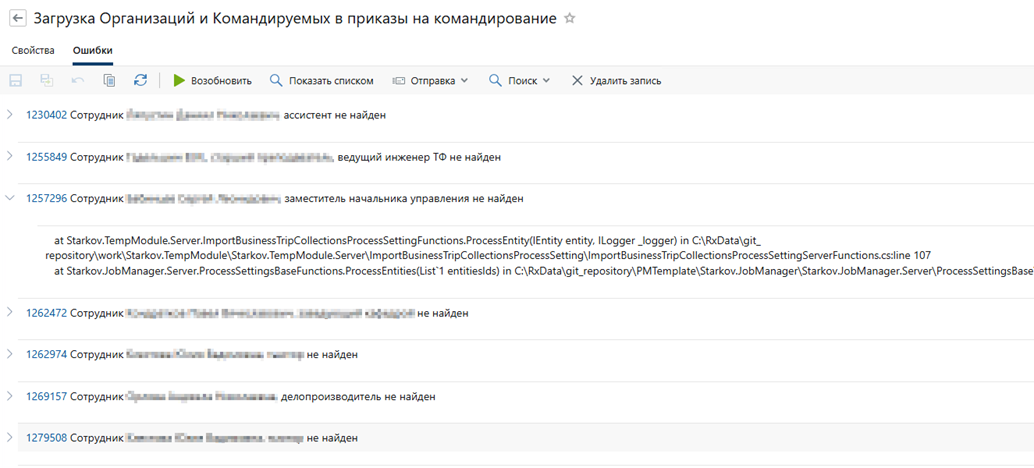
Рис.5. Вкладка с ошибками карточки очереди
После устранения причины ошибки, элемент очереди можно вернуть в работу действием «Возобновить». Повторно будут обработаны только записи, в которых были ошибки.
Создание нового процесса разработчиком
Для создания нового обработчика, на рабочем слое своего решения требуется создать справочник-наследник от абстрактного предка из шаблона ProcessSettingBase («Настройка процесса»). При необходимости можно расширить форму дополнительными свойствами — например, свойства-ссылки на документы с файлами, как в рассмотренном выше случае. Далее потребуется переопределить несколько методов, необходимых для кастомизации логики:
/// <summary>
/// Получить все сущности.
/// </summary>
public override IQueryable<Sungero.Domain.Shared.IEntity> GetAllEntities()
{
// Вернуть результат метода GetAll() типа сущности, который будет в обработке.
}
/// <summary>
/// Получить сущности для обработки.
/// </summary>
public override IQueryable<Sungero.Domain.Shared.IEntity> GetEntitiesForProcessing()
{
// Ваша логика получения объектов (наследников IEntity), которые требуется обработать
}
Опционально, вместо метода GetEntitiesForProcessing можно перекрыть метод GetEntitiesIdsForProcessing, возвращающий IQueryable<long >, если получение идентификаторов сущностей предполагается не из репозитория, а ,например, из файла, как в примере выше.
/// <summary>
/// Обработать сущность.
/// </summary>
/// <param name="entity">Сущность для обработки.</param>
/// <param name="_logger">Преднастроенный экземпляр логгера с контекстом (settingId, processId).</param>
public override void ProcessEntity(Sungero.Domain.Shared.IEntity entity, Sungero.Core.ILogger _logger)
{
// Ваша логика обработки, которая должна применятся к каждому объекту
}
Чтобы ускорить работу, мы рекомендуем сразу добавлять инициализацию записи настройки процесса с предустановленными параметрами по умолчанию.
А что в шаблоне?
1. Абстрактный справочник-конфигуратор «Настройка процесса» — содержит настройки. Вот основные:
- количество параллельных потоков;
- количество параллельных потоков в рабочее время;
- размер пачки в потоке;
- количество повторных попыток в случае ошибок и интервал между ними.
2. Параметр для хранения глобального значения максимального количества потоков в базе данных.
3. Фоновый процесс — отслеживает активные настройки, анализирует очереди, при необходимости формирует новые и запускает обработчики с учетом заданных лимитов.
4. Асинхронный обработчик — выполняет обработку очереди, фиксирует ошибки. Повторная обработка выполняется новым экземпляром, чтобы исключить неконтролируемый рост количества потоков.
5. Обработка ошибок и блокировок — реализованы в базовом методе. Обработка конкретной записи сущности вынесена в виртуальный метод, обязательный для перекрытия.
6. Детали выполнения процессов — очереди обработки, их статусы, время обработки и наличие ошибок можно увидеть по действию из карточки настройки процесса.
7. Гибкое обращение с ошибками — ошибки, возникающие в процессе обработки сущности, не прерывают основной процесс, а текст ошибок с привязкой к ИД сохраняется в таблицу внутри экземпляра очереди.
8. Контроль повторных ошибок — ошибки, не связанные с блокировками, которые превысили допустимое количество повторных попыток, исключаются из дальнейших обработок. После анализа и устранения причин ошибок обработку этих записей можно запустить вручную действием «Возобновить» прямо из карточки.
Эффект
Важно отметить, что наше решение не ускоряет прямое выполнение кода обработки одной сущности. Абстрактная производительность одного потока остается прежней. Поэтому тут не будет прямого сравнения скорости выполнения, но зафиксированные значения по реальным кейсам приведем:
- заполнение карточек в 28 191 документе (2 потока) — 2 ч 15 мин, скорость: 210 документов/мин;
- обработка 48 372 папок (4 потока) — 23 мин, скорость: 2100 записей/мин;
- обработка прав в 1 373 242 документах (2–8 потоков) — 7 ч 50 мин, скорость: 2800 документов/мин;
- обработка прав в 3 701 702 задачах (8 потоков) — 13 ч 55 мин, скорость: 4400 задач/мин.
Бизнес-логику обработки сущности разработчик все равно пишет сам, и этого не избежать. Но наше решение берет на себя всю инфраструктурную нагрузку, которая отнимала львиную долю времени при создании каждого нового обработчика.
Что есть уже «из коробки» и не требует затрат:
- Механизм параллелизации и управления потоками.
- Создание очередей, их поддержка и перезапуск.
- Вся логика обработки блокировок, ошибок и повторов.
- Готовый веб-интерфейс для мониторинга и управления.
- Логирование с контекстом.
Разработчику остается только унаследоваться от готового справочника и реализовать ключевые методы с бизнес-логикой. Как показала практика, это сокращает время разработки нового сценария массовой обработки с 1-2 дней (с нуля) до 2-3 часов (настройка по шаблону). Таким образом, если и считать выигрыш в «производительности», то он заключается не в миллисекундах на одну запись, а в часах и днях, сэкономленных на разработке, отладке и доведении процесса до полного завершения.
Ну и подытожим...
Преимущества шаблона
1. Контроль нагрузки: управление потоками позволяет эффективно использовать ресурсы и защищает сервер от перегрузок.
2. Прозрачность и самообслуживание: веб-интерфейс предоставляет полную информацию о ходе выполнения и детализацию ошибок с привязкой к конкретному объекту. Это исключает цепочку взаимодействия "пользователь → администратор → анализ логов". Поэтому ответственный сотрудник может самостоятельно увидеть суть проблемы.
3. Экономия времени: разработчику требуется около 2 часов, чтобы подключить новый процесс обработки.
4. Надёжность: встроенный механизм обработки блокировок и ошибок обеспечивает отказоустойчивость.
Где наиболее применимо
Идеально для задач, где требуется обработка десятков и сотен тысяч сущностей через объектную модель RX после миграций или для проведения массовой обработки.
Где не актуально
Не актуально в процессах, где объектов для обработки немного, либо с задачей более эффективно справятся SQL-скрипты.
Заключение
Опыт компании СТАРКОВ Групп показал: массовая обработка исторических данных после миграций — это задача, которая требует не точечных решений, а системного подхода. Созданный нами шаблон позволяет превратить трудоемкий и рискованный процесс в управляемый, прозрачный и предсказуемый инструмент.
С кодом самого решения можно ознакомиться по ссылке на github
Идея с "Показать списком" ошибки очень хороша, если ошибок будет много.
Параллельных потоков -- доводилось ли проверять ситуацию с очень большим количеством параллельных потоков?
Konstantin, спасибо за хороший вопрос.
Специальных тестов с экстремальным количеством потоков не проводилось. При превышении разумных лимитов мы скорее всего получим:
Полную занятость потоков воркера
Рост очереди
Риск деградации производительности всей системы
Очевидно, к настройке потоков нужно подходить осознанно и знать инфраструктурные ограничения серверов с воркером. В архитектуре решения заложены определенные ограничения:
Локальный лимит — настраивается в веб-интерфейсе для каждого процесса
Глобальный лимит — хранится в БД и ограничивает общее число потоков для всех процессов решения
Приоритетная очередь — процессы ожидают доступных потоков в соответствии с приоритетами
Подразумевается что глобальный лимит (параметр в БД) будет настраивать разработчик или администратор, по-умолчанию он инициализируется значением 8 потоков.
Авторизуйтесь, чтобы написать комментарий