Нагрузочное тестирование системы DIRECTUM на 5000 одновременно работающих пользователях. Часть 2. Подготовка базы данных.
Проведенные в 2005 году тестирования показало, что размер базы данных на скорость работы с системой не влияет. Тем не менее, было решено проводить тестирование на базе данных, соответствующей 2 годам работы 5000 пользователей.
Собственно первое, что пришлось сделать при подготовке базы данных, это создать 5000 пользователей. Для автоматизации этого процесса, был написан сценарий DIRECTUM, который создает пользователей, группы пользователей и раскидывает пользователей по группам.
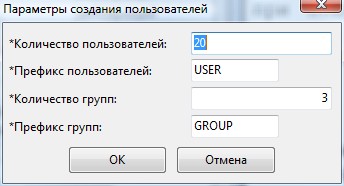
Рисунок 1 Входные параметры сценария для создания пользователей
После создания пользователей необходимо было задать пароли для всех пользователей. Для этого использовали следующий сценарий:
!Query=CreateQuery()
!Query.CommandText="select UserCode
from LTUsers
where Type='П'"
!Query.Open
!Query.First
while !Query.EOF=false
!UserName=!Query.FieldByIndex(0).Value
!Сhange=CreateQuery()
!Сhange.CommandText="exec sp_password @old = null , @new = '11111' , @loginame = '"&!UserName&"'"
!Сhange.Execute
!Query.Next
endwhile
!Query.Close
ShowMessage("Готово!")
Для того, чтобы использовать созданных пользователей в тестировании, нужно было, чтобы у каждого пользователи были стандартные папки (Исходящие, Входящие, Избранное). Паки эти создаются при первом входе в систему. Делать это вручную оказалось очень долго. Поэтому был написан сценарий, который для каждого пользователя создает объект Application и получает родительские паки следующим образом
RootFolders = Folders.RootFoldersПри анализе результатов, полученных с помощью механизма профайлинга системы DIRECTUM в нашей компании, были выделены следующие характеристики базы данных:
- количество документов – 4.5 млн.;
- средний размер документов - 600кб;
- типы документов - 90% офисных документов (Word, Excel, PowerPoint), 10% графических;
- количество РКК – 2.25 млн.;
- количество задач – 7.5 млн.;
К сожалению, из-за ограниченности количества дисков в системе хранения данных, была создана база, соответствующая только 10 месяцам работы 5000 пользователей. В наличии было только 2 ТБ свободного места, вместо 5 ТБ требуемого.
Таблица 1 Характеристики базы данных
|
Параметр |
Значение |
|
Число документов |
1868316 |
|
Число задач |
2967058 |
|
Число заданий |
2917058 |
|
Число записей в справочнике РКК («Регистрационно-контрольные карточки») |
901204 |
|
Число записей в справочнике ОРГ («Организации») |
12340 |
|
Размер базы данных (ГБ) |
1650 |
Предварительно предполагалось, заданий будет в 2 раза больше чем задач и их созданием должна была заниматься служба workflow. В базе данных было создано необходимое количество задач и поставлено в очередь обработки службой. Но как оказалось, скорость обработки очереди задач для быстрой закачки данных не удовлетворяет. За 1 час было обработано порядка 7000 задач. С учетом того, что задач должно было быть порядка 1.5 млн, то обработка заняла бы порядка 214 часов. Пришлось искать способы ускорения закачки заданий.
Для быстрой закачки заданий были использованы уже созданные задачи с заданиями. Они были просто скопированы. Очередь обработки задач была очищена. В итоге мы получили количество задач, превышающее требуемое в 2 раза, половина из которых была в состоянии Инициализация.
Собственно, как же происходила закачка такого большого количества данных. Была написана утилита, позволяющая создавать большое количество документов, РРК, задач. Суть утилиты в том, что все создание происходит с помощью прямых sql-запросов к базе данных. Выглядит она следующим образом.
Рисунок 2 Утилита для закачки данных
Прошу строго не судить за юзабельность утилиты  .
.
Вот некоторые интересные цифры, которые были получены при закачке данных:
1. Время создания 1000000 задач - 40 мин.
2. Время создания 500000 РКК - 15 мин.
3. Время создания 100000 документов – 35 мин.
Далее расскажу о методике тестирования
Это старая версия утилиты Сеичас многих контролов нет уже
Сеичас многих контролов нет уже
На каком тестовом стенде это было (Гигагерцы, Гигабайты, Террафлопы, Гигабиты/сек)?
Пусть в компании работает 500 человек (предположим что это так, для округления):
количество документов – 4.5 млн.;
количество задач – 7.5 млн.;
тогда на среднего директумовца приходится 9000 документов и 15000 задач.
Расчётная компания:
За 10 месяцем работы 5000 пользователей, они создали бы 1868316 документов и 2967058 задач.
Значит:
1. На 1 пользователя приходится 373,6632 документов
2. Скорость создания документов 1-м пользователем: 37,36632 документов в месяц.
Так как средний пользователь Директума создал 9000 документов, то он постратил на это примерно 241 месяц или 20 лет.
Вывод - если в компании работает 500 человек, то каждый их них имеет стаж работы около 20 лет.
Пытаюсь понять расчеты предыдущего комментатора:
Откуда такое количество документов для 500 человек?
Т.о. в нашей компании 4,5 млн. документов. Из этих соображений и расчёт. А сколько человек у нас в компании (было + есть), которые хоть как то приложили руку к созданию документов - да около 500.
4,5 млн. документов в нашей базе, это обман с твоей стороны Слава. Я нигде этого не писал. То что на основе анализа нашей базы были получены эти данные, то это да. Но эти данные можно легко вести полцчив данные на одного человека.
Но эти данные можно легко получить, зная данные на одного человека.
Мне показалось, что в данном случае 4,5 млн взято для 5000 пользователей на основании данных по нашей компании. При этом данные по нашей компании здесь не приведены
Верно, Саша, ты этого не писал.
Чувствовал, что вот эта формулировка таит загадку, (думал - как это профайлинг показал количество документов в базе, зачем вообще количество документов определять таким образом):
Механизм профайлинга показал сколько создается документов в день. Зная же сколько человек это количество создало, можно вывести документов в в день на одного пользователя. А потом с этим числом хоть что делай, хоть на 500 переводи, хоть на 10 лет.
Авторизуйтесь, чтобы написать комментарий