Немного о производительности
Введение
Как часто Вы, администраторы системы DIRECTUM, получали от пользователей заявления вида, что система «тормозит», «зависает», медленно выполняет какие-то типовые операции, которые должны выполняться довольно быстро? Я думаю, каждый сталкивался с этим в своей практике. Другое дело, что часть этих заявлений была необоснована по причине каких-то пользовательских неточностей, неправильного выполнения каких-то действий, низкой производительности пользовательского оборудования и т.д. Но иногда бывают случаи, что действительно при отсутствии какой-либо серьезной нагрузки на систему, ее производительность оставляет желать лучшего, у всех без исключения пользователей системы…
Как быть в этом случае, с чего начинать искать причины низкой производительности?
Для начала необходимо уточнить, что мы будем понимать под низкой производительностью. Чтобы определиться с этим понятием мы должны ввести так называемые метрики, по значениям которых мы будем определять низкую производительность системы. В этом нам может помочь механизм профайлинга системы DIRECTUM, который дает временные значения тех или иных действий пользователей в системе, например, открытие карточки записи справочника, создание записи справочника, открытие проводника и т.д. (стоит отметить, что не все действия могут быть отражены в профайлинге).
Сравнив текущие значения операций с усредненными данными профайлинга за последнюю неделю (месяц, год), можно сделать предварительные выводы о наличии проблем с производительностью.
Далее необходимо найти причину низкой производительности, для ее поиска нам потребуется проанализировать список основных пунктов.
Аппаратная часть сервера
Это пожалуй основа с которой следует начинать. Очень часто бывает, что в процессе эксплуатации системы количество сервисов на сервере увеличивается, соответственно растет нагрузка и в результате получаем проблемы с производительностью.
Конфигурацию аппаратного обеспечения для системы DIRECTUM можно узнать в документе «DIRECTUM. Типовые требования к аппаратному и программному обеспечению»
В случае если аппаратные ресурсы сервера явно не удовлетворяют требованиям, есть два пути:
- увеличить/улучшить ресурсы сервера;
- разнести часть компонент и сервисов на различные физические/виртуальные сервера. При выборе на какой сервер переносить (физический или виртуальный) может помочь статья Виртуализация серверной инфраструктуры DIRECTUM.
Проверка соответствия настроек ОС, СУБД и СХД рекомендациям вендоров
Каждый разработчик ПО и оборудования при выпуске своего продукта старается охватить как можно больший спектр задач и потенциальную аудиторию, для которой подойдет это решение. С одной стороны это большой плюс и продуктом можно пользоваться практически из коробки без существенных доработок, с другой – минус, т.к. не всегда нужны все функции продукта здесь и сейчас, например, это может привести к путанице при эксплуатации у персонала или будет затрачиваться часть ресурсов на неиспользуемые функции.
Поэтому у каждого вендора, как правило к своему продукту есть некий набор рекомендаций, т.н. best practices, для наилучшей настройки продукта под те или иные условия эксплуатации. Часть из них может влиять на надежность, часть на производительность.
ОС, СУБД и СХД в этом вопросе не являются исключениями. Эти рекомендации можно найти на официальных сайтах компаний.
Примером таких рекомендаций могут служить:
- установка параметра использования оперативной памяти SQL-сервером в максимально возможное значение, с учетом резервирования части памяти под нужды ОС;
- расположение данных на дисковых массивах RAID-10, вместо одиночных дисков.
Полезные статьи: Пять глупых ошибок администраторов БД (DBA) и Подготовка MS SQL Server 2005 к промышленной эксплуатации
Назначенные задания по обслуживанию сервера СУБД и БД
Очень часто снижение производительности системы может наблюдаться в моменты интенсивной работы каких-либо назначенных заданий Windows и SQL-сервера. Примером могут быть задания по переиндексации БД, либо выполнение полного индексирования текстов и слепков системы.
Любые задания по обслуживанию СУБД и самих БД необходимо выполнять в моменты минимального влияния на работу пользователей, например, по окончании рабочего дня или ночное время.
Счетчики производительности ОС и СУБД
Одним из наиболее мощных и доступных инструментов для обнаружения проблем с производительностью в ОС Windows и СУБД MS SQL Server являются встроенные счетчики производительности (Performance Counters).
Запись счетчиков можно произвести с помощью утилиты perfmon, либо создав группу сборщиков данных на основе готовых шаблонов. Далее проанализировав эти данные можно сделать вывод о достаточности/недостаточности вычислительных ресурсов сервера. Очень часто в ходе такого анализа выявляются узкие места в дисковой подсистеме, сети и т.д. После того как определены узкие места, необходимо если возможно переконфигурировать существующее оборудование, либо заменить его на более производительное.
Постоянный мониторинг счетчиков на пороговые значения можно автоматизировать с помощью продукта Microsoft System Center Operation Manager (SCOM) и технического решения Management Pack DIRECTUM for SCOM. Кроме того, это техническое решение поможет контролировать и другие параметры системы DIRECTUM, такие как состояние сервисных служб и т.д. Более подробно можно узнать здесь и здесь.
Activity Monitor
С этим инструментом я думаю знаком каждый администратор кто хоть как-то связан с администрированием СУБД MS SQL Server. Он позволяет выявить выполнение длительных запросов на SQL-сервере, выявить блокировки и т.д. Все это монитор позволяет выполнять в режиме онлайн.
Логи системы DIRECTUM
Казалось бы между логами и производительностью нет прямой зависимости, тем не менее очень часто по логам можно определить проблемные места в системе и тем самым улучшить эту самую производительность. Примером такой ситуации может быть, постоянные ошибки в лог-файле службы WorkFlow вида:

Таким образом, при наличии таких строк лога можно сделать вывод, что процесс службы WF принудительно завершается. При большом количестве подобных задач это может привести к тому, что будет копиться очередь необработанных службой задач, и в итоге может значительно
увеличиться время между отправкой задачи и доставкой соответствующего задания исполнителю, что с точки зрения пользователя также выглядит как медленная работа системы.
Поэтому необходимо своевременно анализировать лог-файлы системы и устранять причины возникновения ошибок в системе.
Более подробно о некоторых регулярных полезных действиях с лог-файлами и их автоматизации можно узнать в статьях: Все о лог-файлах DIRECTUM, Про лог-файлы и Парсим логи DIRECTUM.
Клиентский профайлинг системы DIRECTUM и SQL-профайлинг
Профайлинг системы DIRECTUM предназначен для анализа производительности системы DIRECTUM в разных разрезах и за разные периоды. Он позволяет анализировать длительность как отдельных операций конкретных пользователей, так и все операции всех пользователей за какой-либо период. В системе есть готовые отчеты, которые позволяют наглядно проиллюстрировать, например, динамику времен выполнения операций.
Но наиболее интересным и полезным с точки зрения анализа производительности являются не отчеты, а «ручной» профайлинг. Под «ручным» понимается профайлинг прямыми запросами в БД профайлинга. Так мы можем выявить например, наиболее длительные прикладные функции или события в системе. Если операция выполняется долго, причин м.б. несколько, например: низкая производительность рабочей станции, сети или длительное выполнение операции на самом сервере.
В совокупности с SQL-профайлингом мы можем определить, где именно операция-функция выполняется медленно: на клиентском рабочем месте или непосредственно на SQL-сервере, т.к. практически всегда операция профайлинга состоит из одного или нескольких SQL-запросов.
Если операция на сервере выполняется долго (при адекватном объеме выбранных данных), есть три пути:
- использование дополнительных индексов в системе;
- оптимизация прикладной разработки;
- увеличить/улучшить аппаратные ресурсы сервера.
Стоит отметить, что оптимизацию прикладных функций и событий должен осуществлять разработчик системы. В случае же добавления индексов также надо быть осмотрительным, т.к. бездумное добавление индексов может привести к обратному эффекту. Также стоит учитывать, что эти рекомендации относятся в большей степени к тем, у кого в системе много нестандартной разработки. Для стандартного функционала, как правило правка прикладной разработки и добавление новых индексов не требуется.
Если же операция на сервере выполняется быстро и нет проблем в прикладной разработке, предлагаю вам обратиться в службу поддержки с приложением результатов вашего анализа, вполне возможно вы обнаружили дефект.
Также рекомендую к прочтению статью – Автоматизация отчетов о быстродействии системы DIRECTUM.
И вместо заключения, примерная блок схема поиска узких мест в системе(картинка кликабельна):
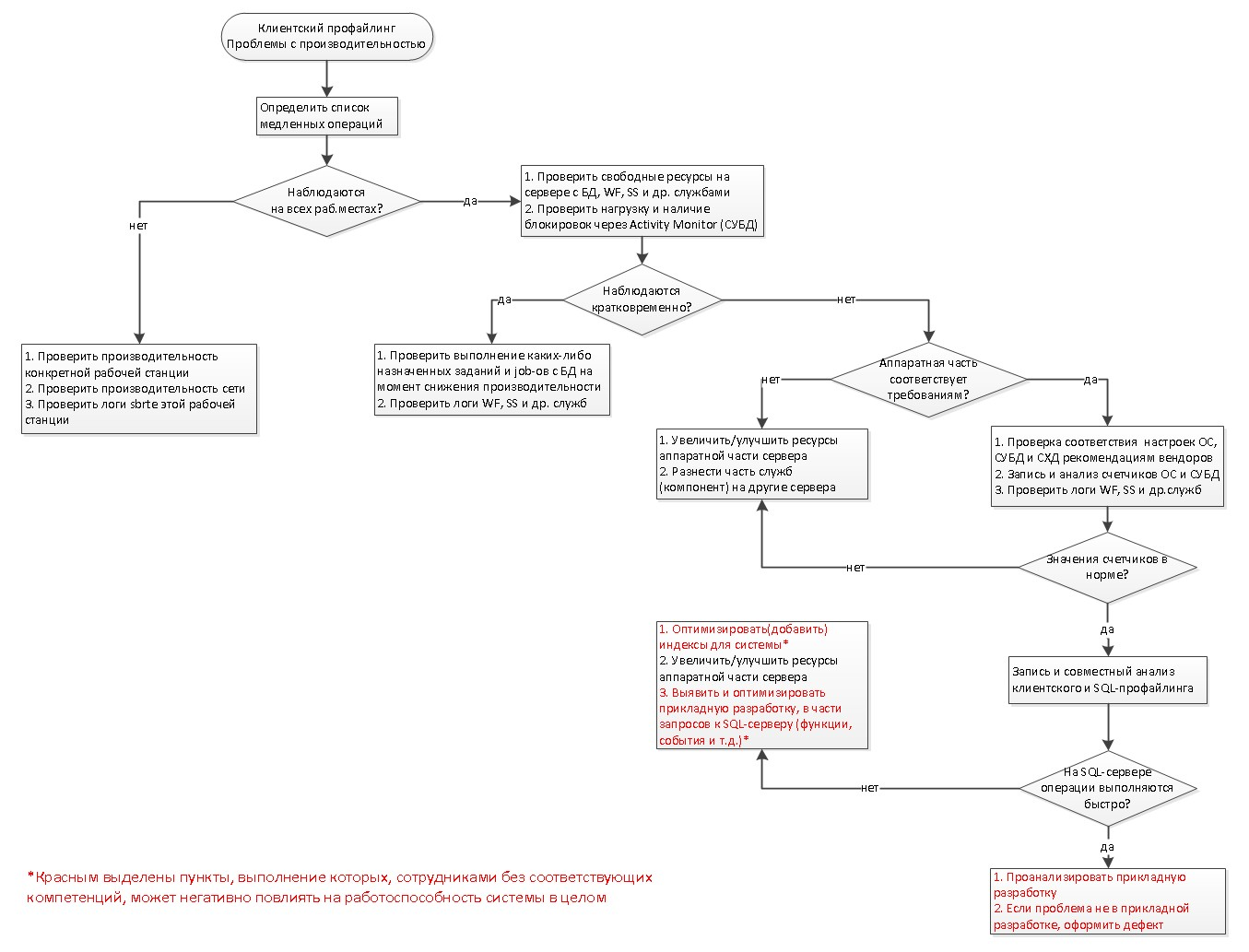
А как быть, если на одном компьютере подключение идет быстро, а на другом нет, как диагностировать?
Иван, начните с самого простого:
Авторизуйтесь, чтобы написать комментарий