Основы разработки гибких форм распознавания. Часть 1
Предыдущие статьи по данной теме:
Abbyy FlexiCapture Engine + IS-Builder = Автоматизация ввода и обработки документов
Что же такое гибкие формы и для чего они нужны. Распознавание – это процесс получения текста с изображения. После обычного распознавания мы получим сплошной текст, который мы вряд ли сможем структурировать, поэтому структурировать информацию нужно ещё до распознавания. Как раз для этого и предназначены гибкие формы распознавания. Общая схема цикла распознавания при этом получается следующая:

От того как будет выглядеть гибкая форма распознавания, будет зависеть весь последующий процесс распознавания и структурирования.
Для разработки таких форм в пакете Abbyy Flexi Capture есть инструмент для разработки таких форм – Flexi Layout Studio. С помощью него можно создать произвольную гибкую форму для любого типа документа, будь то счет-фактура или резюме кандидата на работу. Работа с ней хорошо описана в справочной системе, поэтому подробно о том, как в ней работать, останавливаться не будем.
Процесс разработки гибких форм можно условно разбить на 3 этапа.
Подготовка проекта
На данном этапе создаётся проект гибкой формы, производятся все необходимые настройки, такие как тип текста, язык текста, минимальное, максимальное количество страниц, на которое происходит наложение гибкой формы, и др.
Также на данном этапе производится подготовка тестовых изображений для наложения. Они нам необходимы для дальнейшей разработки и тестирования в качестве опытных образцов. И чем больше этих тестовых изображений будет, тем больше можно будет выявить признаков у структурных элементов, и тем точнее будет наша гибкая форма при наложении.
На данном этапе мы подготовили все, что нам нужно для последующей разработки.
Определение элементов структуры
Элементами структуры в гибких формах разработки являются блоки. В блоках содержится информации о названии структурного элемента, о его типе и о его расположении на изображении по результатам наложения. Разработка гибких форм начинается с определения состава блоков, которые нужно найти. Flexi Layout Studio предоставляет следующие типы блоков:
- Text – текстовый блок;
- Barcode – штрих код;
- Checkmark – флажок;
- Picture – изображение;
- Table – таблица;
- Group – группа;
- Checkmark group – группа флажков;
- Repeatable group – повторяющаяся группа;
- Unrecognizable – не распознаваемая область.
Названия типов блоков говорят сами за себя.
Фактически для документооборота полезны только несколько блоков. Это Text, Table, Group и Repeatable group. Остальные блоки используются не так часто, как например Barcode, Picture и др. Как выбирать какой блок, где использовать? Это довольно просто решается. Если у нас элемент структуры является единичной информацией, а это может быть дата документа, общая сумма, ответственный сотрудник, одним словом любая единичная текстовая информация, то выбираем блок Text. Блок Table предназначен для идентификации таблиц. Его следует использовать для поиска каких-либо табличных данных, к примеру, состав товаров из счет-фактуры. Блок Group не несёт какой-либо полезной нагрузки, предназначен лишь для объединения других блоков, к примеру, можно объединить в группу блоки с информацией о поставщике. Блок Repeatable group предназначен для блоков, которые могут идентифицировать область элементов структуры неограниченное количество раз. То есть таких элементов может быть несколько и заведомо, сколько их будет неизвестно. В чем-то он схож с блоком таблица. Его отличие состоит в том, что эти повторяющиеся блоки могут быть разбросаны по всему изображению. Использовать его можно, когда нельзя точно сказать, что это таблица.
Каждый блок имеет какое-то своё уникальное имя, и связь с элементами поиска, либо написать специфический код на встроенном языке, который будет указывать область поиска автоматически. Это делается через свойства блока. Имя нужно будет указать сейчас, а связь будем указывать после того, как разработаем элемент поиска. Для таких специфичных типов блоков, как Table, нужно указать состав колонок и их тип: Text, Barcode, Checkmark, Picture, Unrecognizable. Чаще всего в качестве типа указывают Text. Что делать, если состав колонок у разных документов разный. В данном случае выход только один – указать все возможные виды колонок.
В качестве примера приведу структуру, которая получилась для гибкой формы распознавания инвойса (ccылка на Wikipedia):
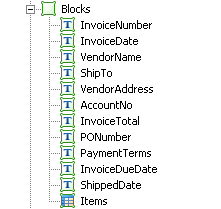
Как видим, большинство полей у нас получились с типом Text, и один элемент с типом Table.
По завершению данного этапа у нас должна получиться описание того, что мы получим в итоге от гибкой формы распознавания.
Создание гибкого описания
Данный этап, наверное, является самым важным, по сравнению с предыдущими этапами. Ведь именно за счет этого этапа осуществляет поиск тех самых областей, в которых расположен тот, или иной элемент структуры. И если на предыдущих этапах мы производили действия исходя из каких-либо потребностей и технических описаний, то разработка формы на данном этапе является полностью эмпирической. Нет никаких правил или техник, по которым можно достичь наилучшего результата. Нужно сказать, что любое изменение может сказаться на процессе распознавания, поэтому модифицировать проект гибкой формы в части поиска нужно с особой осторожностью.
Гибкое описание в Flexi Layout Studio строится при помощи элементов поиска. В инструменте предоставляются следующие элементы:
- Static Text – позволяет найти заранее известный текст;
- Separator – позволяет искать вертикальные и горизонтальные линии и разделители;
- White Gap – позволяет искать области не содержащие объектов, фактически пустые места в изображении;
- Barcode – позволяет искать штрих – коды;
- Character String – позволяет искать заранее неизвестные слова или цепочки слов;
- Paragraph – позволяет искать целые абзацы с текстом;
- Object Collection – позволяет искать совокупности каких либо объектов изображения – например логотипы компаний;
- Date – позволяет искать даты;
- Group – предназначена для группировки различных элементов поиска в одну единицу;
- Phone – предназначена для поиска телефонных номеров и факсов;
- Currency – предназначена для поиска денежных сумм в различных валютах;
- Table – предназначена для поиска таблиц;
- Repeatable Group – предназначена для поиска повторяющихся элементов с одинаковым описанием;
- First Found – предназначена для поиска первого попавшегося по списку элемента;
- Labelled Field – предназначена для поиска полей с заголовками;
- Region – Не является каким то поисковым элементом, но позволяет задать область для поиска;
- Header и Footer – предназначены для установления начала и конца страниц в многостраничном документе.
Добавляя тот, или иной элемент можно находить на изображении соответствующий ему объект. Например, добавив в проект элемент Static Text, можно будет найти на изображении объект соответствующий тексту заданном в свойствах этого элемента.
Из базовых элементов, таких как Static Text, Character String, Date и др. и элементов групп можно выстраивать деревья элементов любого уровня вложенности. Поиск объектов по элементам происходит, начиная от самого верхнего элемента в дереве заканчивая самым нижним.
Поиск объектов в гибких формах осуществляется тремя способами:
- на основе ключевых признаков (поисковых выражений, алфавита, количества и форматов строк, количества символов и др.);
- на основе расположения относительно других объектов;
- на основе абсолютного расположения.
С помощью 1 и 2 типа ищутся обычно поля с заголовками, а с помощью 1 и 3, наоборот, без заголовков. Настройки данных способов выполняются в свойствах элементов.
Для примера попробуем найти сумму к оплате в счете на оплату.

Как видим её можно найти в строке «Всего к оплате». Сумма расположена правее заголовка. Найти такой объект можно при помощи 2 элементов: Static Text и Character String. Для удобства объединим их в одну группу и назовём kwTotal – заголовок и Total - поле.
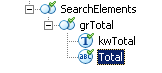
В Static Text указать текст поиска «Всегокоплате», в Character String задать расположение относительно Static Text примерно следующим образом:
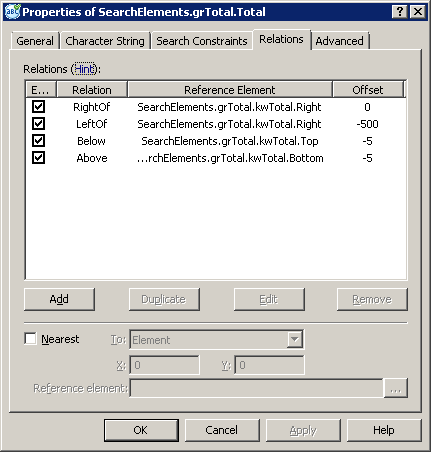
За счет такой конфигурации мы добиваемся следующего расположения области поиска Character String.
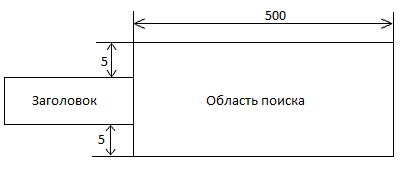
Укажем алфавит для поиска Total: ',-.0123456789. Создав такое описание, мы можем найти необходимое нам поле:

При поиске объектов на изображении Flexi Capture строит дерево возможных вариантов, при котором найденные объекты соответствуют гибкому описанию. При помощи такого дерева FC может делать предположения и находить верный вариант расположения объектов. Это дерево может быть из одной ветки, а может и быть очень разветвлённым. Каждая ветка соответствует одному найденному объекту или случаю когда такой объект не найден.
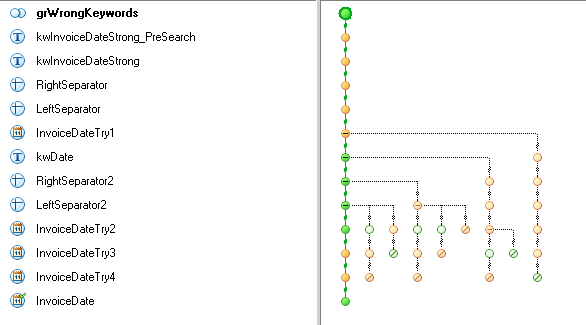
Для того чтобы разобраться какой вариант наиболее правильный применяется такой параметр, как гипотеза. Гипотеза - предположение, что найденный объект (ы) изображения соответствует элементу, т.е. удовлетворяет заданным свойствам и условиям поиска данного элемента. Основной характеристикой гипотезы является качество гипотезы. Качество гипотезы это некоторое число от 0 до 1 показывающее насколько хорошо найденный объект соответствует данному элементу. Для каждого элемента поиска, даже для группы, создаётся отдельная гипотеза. Если объекты на изображении соответствующие элементу поиска не найдены, то качество гипотезы задаётся с помощью качества нулевой гипотезы, которая указывается в свойствах элемента поиска.
Таким образом, подводя итог по вышесказанному, основная суть разработки гибких форм это добиться такой конфигурации, чтобы для правильных найденных объектов или нулевой гипотезы качество гипотезы было выше, чем у неправильных найденных объектов.
Качество гипотезы объекта зависит от различных признаков, которые указываются в свойствах элемента поиска. Это может быть обязательность элемента, это длина строки, это соответствие алфавиту и др. Возвращаясь к предыдущему примеру со счетом на оплату, были выставлены следующие критерии:
- kwTotal: Обязательный, максимальный процент несовпадений с текстом поиска 30%
- Total: Обязательный, процент не алфавитных символов 20%, количество символов неограниченно.
После того как мы создали описание осталось связать блок с нужным нам элементом описания, к примеру с элементом поиска Total.
Выводы
Используя такой мощный инструмент можно автоматизировать захват и структурирование входящих документов любого типа, содержания или качества. Применяя гибкие формы распознавания можно обеспечить не только распознавание но и структурирование информации, а это важно для передачи и хранения таких документов в ERP и ECM системах. Гибкое описание позволяет не заботиться о том как выглядит документ, обеспечивая тем самым универсальность распознавания документов от любой организации.
Все зависит от уровня интереса к данной информации. А так в целом во второй части постараюсь рассказать.
Авторизуйтесь, чтобы написать комментарий