Парсинг файлов в IS-Builder при помощи утилиты Log Parser
Доброго времени суток!
В данной статье я попытаюсь рассказать Вам о том, как при помощи простой, но достаточно мощной утилиты Log Parser осуществлять парсинг файлов, используя объектную COM-модель IS-Builder. Многие из Вас, наверно, уже знакомы с утилитой Log Parser, а для тех, кто не знаком с ней, я опишу ее назначение в разделе "Немного о Log Parser".
Немного о Log Parser
Log Parser – это многофункциональное и универсальное средство, которое предоставляет универсальный доступ по запросу к таким текстовым данным, как файлы журнала, XML- и CSV-файлы, а также к основным источникам данных в операционной системе Windows, например журналу событий, реестру, файловой системе и службе каталогов Active Directory. Для работы с Log Parser необходимо указать требуемый источник данных и способ их обработки. Результаты запроса можно представить в пользовательском текстовом формате вывода или в более специализированных форматах, например SQL, SYSLOG или в виде диаграммы.
IS-Builder и Log Parser
Для осуществления работы с Log Parser необходимо произвести создание COM-объекта LogQuery:
LogQuery = CreateObject('MSUtil.LogQuery')
Следующим шагом следует определить формат входного файла:
InputFormat = CreateObject(ProgID)
Таблица соответствия входного формата и ProdID приведена ниже:
| Входной формат | ProgID | Имя класса в .Net |
|---|---|---|
| ADS | MSUtil.LogQuery.ADSInputFormat | COMADSInputContextClassClass |
| BIN | MSUtil.LogQuery.IISBINInputFormat | COMIISBINInputContextClassClass |
| CSV | MSUtil.LogQuery.CSVInputFormat | COMCSVInputContextClassClass |
| ETW | MSUtil.LogQuery.ETWInputFormat | COMETWInputContextClassClass |
| EVT | MSUtil.LogQuery.EventLogInputFormat | COMEventLogInputContextClassClass |
| FS | MSUtil.LogQuery.FileSystemInputFormat | COMFileSystemInputContextClassClass |
| HTTPERR | MSUtil.LogQuery.HttpErrorInputFormat | COMHttpErrorInputContextClassClass |
| IIS | MSUtil.LogQuery.IISIISInputFormat | COMIISIISInputContextClassClass |
| IISODBC | MSUtil.LogQuery.IISODBCInputFormat | COMIISODBCInputContextClassClass |
| IISW3C | MSUtil.LogQuery.IISW3CInputFormat | COMIISW3CInputContextClassClass |
| NCSA | MSUtil.LogQuery.IISNCSAInputFormat | COMIISNCSAInputContextClassClass |
| NETMON | MSUtil.LogQuery.NetMonInputFormat | COMNetMonInputContextClassClass |
| REG | MSUtil.LogQuery.RegistryInputFormat | COMRegistryInputContextClassClass |
| TEXTLINE | MSUtil.LogQuery.TextLineInputFormat | COMTextLineInputContextClassClass |
| TEXTWORD | MSUtil.LogQuery.TextWordInputFormat | COMTextWordInputContextClassClass |
| TSV | MSUtil.LogQuery.TSVInputFormat | COMTSVInputContextClassClass |
| URLSCAN | MSUtil.LogQuery.URLScanLogInputFormat | COMURLScanLogInputContextClassClass |
| W3C | MSUtil.LogQuery.W3CInputFormat | COMW3CInputContextClassClass |
| XML | MSUtil.LogQuery.XMLInputFormat | COMXMLInputContextClassClass |
Необходимо учесть, что ProgID должен быть передан в виде строки. Например, для парсинга файлов формата CSV, необходимо произвести создание следующего COM-объекта:
InputFormat = CreateObject('MSUtil.LogQuery.CSVInputFormat')
После того, как задан входной формат необходимо составить SQL-запрос. Например:
PATH = 'D:\Table1.csv' SQL = Format(‘SELECT * FROM %s’; PATH)
Данный запрос произведет выборку всех записей из файла. Но не всегда выборка содержит только те столбцы, которые указаны в файле. Например, при парсинге файлов формата CSV данным запросом, первый столбец отводится под путь к файлу, а второй – под номер строки в файле. Также необходимо учитывать, что стандартно первая строка файла интерпретируется как строка заголовков таблицы. Бывают случаи, когда в первой строки вместо заголовков, содержатся данные и их необходимо обработать. Для того, чтобы первая строка интерпретировалась как строка данных, необходимо:
InputFormat.headerRow = FALSE
На примере формата CSV, с отключением строки заголовков, столбцы именуются следующим образом:
- Filename
- RowNumber
- Field1
- Field2
- …
Когда все настройки произведены, можно производить чтение набора данных:
RecordSet = LogQuery.Execute(SQL; InputFormat)
Данные получены и содержатся в RecordSet. Следующим шагом к обработке будет чтение записи, которое осуществляется методом getRecord():
Record = RecordSet.getRecord()
Для получения значений полей записи воспользуемся следующим методом:
Record.getValue(Название_столбца)
Для осуществления передвижения по записям внутри RecordSet применяются методы moveNext(), а для проверки окончания – метод atEnd().
В результате, все записи можно обработать следующим циклом:
PATH = 'D:\Table1.csv'
LogQuery = CreateObject('MSUtil.LogQuery')
InputFormat = CreateObject('MSUtil.LogQuery.CSVInputFormat')
InputFormat.headerRow = FALSE
SQL = Format('SELECT * FROM %s'; PATH)
RecordSet = LogQuery.Execute(SQL; InputFormat)
COLUMN_COUNT = RecordSet.getColumnCount()
while not RecordSet.atEnd()
Record = RecordSet.getRecord()
i = 1
while i < COLUMN_COUNT - 2
FIELD = Record.getValue(Format('Field%d'; i))
if not VarIsNull(FIELD)
//Операторы обработки
//...
endif
i = i + 1
endwhile
RecordSet.moveNext()
endwhile
Пример
Предположим, нам необходимо обработать файл D:\Test.csv, содержащий следующие строки:
Date,Description 10/23/2013,'Test 1' 10/24/2013,'Test 2' 10/25/2013,'Test 3'
Как видно, входной файл имеет формат CSV, а первая строка содержит заголовки. Поэтому алгоритм обработки данного файла будет иметь следующий вид:
CSV_PATH = 'D:\Test.csv'
LogQuery = CreateObject('MSUtil.LogQuery')
CSVInputFormat = CreateObject('MSUtil.LogQuery.CSVInputFormat')
SQL = Format('SELECT * FROM %s'; CSV_PATH)
RecordSet = LogQuery.Execute(SQL; CSVInputFormat)
COLUMN_COUNT = RecordSet.getColumnCount()
StrList = CreateStringList()
while not RecordSet.atEnd()
Record = RecordSet.getRecord()
Date = Record.getValue('Date')
Description = Record.getValue('Description')
StrList.Add(Date & TAB & Description)
RecordSet.moveNext()
endwhile
EditText(StrList.Text)
Результатом работы данного алгоритма будет окно EditText:
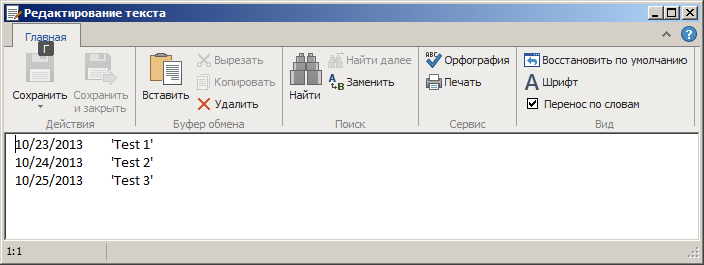
Итоги
В данной статье были рассмотрены основные возможности парсинга файлов при помощи утилиты Log Parser компании Microsoft посредством COM-модели.
Алгоритм работы с Log Parser посредством COM-модели следующий:
- Создать COM-объект LogQuery.
- Создать входной формат.
- Создать SQL запрос.
- Считать все данные в RecordSet.
- Производить последовательное чтение записей из RecordSet в Record.
Вопросы по поводу примера:
1) Как парсер понимает, что строка "Date,Description" - это заголовки, а не сами данные?
2) Что если этой строки не будет?
Как говорилось в статье, при стандартных настройках парсер считывает первую строку, как строку заголовков. Поэтому, если первая строка содержит данные, чтобы они не интерпретировались как заголовки столбцов, необходимо указать парсеру, что первая строка - не строка заголовков:
InputFormat.headerRow = FALSEИ тогда поля будут именоваться, как Field1, Field2, ...
Соответственно, если взять пример и убрать строку заголовков из входного файла, то столбцы будут именоваться следующим образом:
1. Вижу. Невнимательно читал.
2. А есть возможность при отсутствии строки заголовков дать полям алиасы в тексте запроса и потом использовать их в качестве имен для обращения к результатам?
Если я правильно понимаю вопрос, то почему нет? Написать запрос в виде:
Тогда собственно сам код будет выглядеть примерно так:
CSV_PATH = 'D:\Test.csv' LogQuery = CreateObject('MSUtil.LogQuery') CSVInputFormat = CreateObject('MSUtil.LogQuery.CSVInputFormat') SQL = Format('SELECT Field1 AS DateField, Field2 AS DescriptionField FROM %s'; CSV_PATH) CSVInputFormat.headerRow = FALSE RecordSet = LogQuery.Execute(SQL; CSVInputFormat) COLUMN_COUNT = RecordSet.getColumnCount() StrList = CreateStringList() while not RecordSet.atEnd() Record = RecordSet.getRecord() Date = Record.getValue('DateField') Description = Record.getValue('DescriptionField') StrList.Add(Date & TAB & Description) RecordSet.moveNext() endwhile EditText(StrList.Text)Собственно, результат работы будет полностью идентичным
Авторизуйтесь, чтобы написать комментарий