Основы разработки гибких форм распознавания. Часть 2
Предыдущие статьи по данной теме:
Основы разработки гибких форм распознавания. Часть 1
Abbyy FlexiCapture Engine + IS-Builder = Автоматизация ввода и обработки документов
Прошлая часть была посвящена основным этапам построения гибких форм, а также базовому инструментарию доступному для разработчика.
В этой части хотелось бы поговорить уже о конкретных шаблонах построения элементов поиска, применяемых при построении гибкой формы распознавания.
Данные шаблоны зависят конечно же от конкретной структуры данных, а также их типах. Поэтому остановимся только на часто используемых типах и структурах.
На изображении, будь то скан или фотография, встречаются 4 типа структур: Одиночные данные, Табличные данные, Текст и рисунок. Поиск рисунков не очень тривиальная задача и врядли найдёт применение в СЭД. В этой части постараюсь освятить тему поиска одиночных данных и обычного текста.
1. Текст
Текст наверное самый простой из структурных элементов, которые можно легко обнаружить на изображении. Делается это при помощи элемента поиска Paragraph.
Наиболее отличительные черты текста:
- Значение текста обычно располагается более чем на 3-4 строках.
- Обычно ширина значения текста занимает больше чем четверть ширины страницы.
- Для конкретных типов документов текст располагается в конкретных местах. К примеру для финансовых документов текст обычно пишется в верхних и нижних колонтитулах.
Собственно, все эти черты являются свойствами элемента поиска Paragraph. Указав которые можно легко обнаружить текст.
2. Одиночные данные
Самый распространнённый тип данных, которые приходится извлекать изображения. Типичными данными для данного типа являются номер документа, название организации,
ФИО работника, различного рода денежные суммы, даты и.т.п. Обычно такие данные сопровождаются заголовками. Реже ситуации когда таковые отсутствуют.
Самый лёгкий способ извлечь такие данные это использовать элемент поиска Labelled Field. В свойствах данного элемента можно задать конкретный тип поля: строка, дата, сумма.
Также мы можем задать расположение данных, справа или снизу, отступы от заголовка, а, а также несколько разных заголовков, под которыми может быть указано это поле.
Такой элемент поиска подходит для строго стандартизированных документов у которых чётко определён заголовок, положение относительно него и др.
Более продвинутые структура элементов поиска, описанная ниже, уже избавлена от этих недостатков.
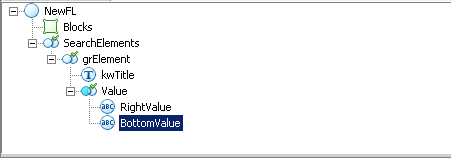
На рисунке представлена типичная структура такого шаблона. Первый элемент поиска это заголовок. Представляет собой статический текст. В нём мы указываем все возможные заголовки конкретного поля.
Второй элементы представляет собой группу, которая ищет первый из возможных объектов подходящих к элементу. В группе созданы два элемента поиска соответственно для расположения значения справа
и снизу от заголовка. Это самые типичные варианты расположения значения поля. Само расположение этих элементов задаётся с помощью относительных координат в отношении к заголовку.
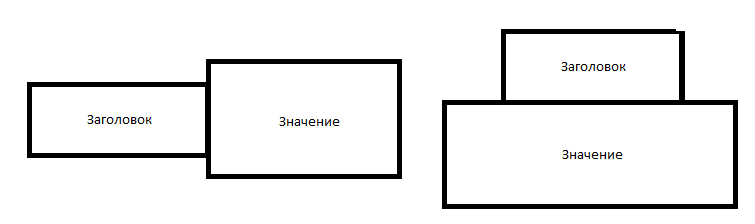
Для правого расположения значение обычно задаётся отступ сверху и снизу для того чтобы случаайно не усечь значение по высоте. Обычно такой интервал составляет 5-40 px сверху и снизу. Значение справа обычно устанавливается по ситуации в зависимости от длины выражения которое требуется найти и
Для нижнего расположения значения ситуация аналогичная. слева и справа отступы составляются порядка 150-200px, нижняя граница обычно берётся по высоте текста с учетом отступов.
В качестве типа элемента поиска значения может выступать Character String, Date, Amount в зависимости от типа данных, которые требуется найти.
Этот шаблон хорош своей простотой и скоростью поиска. Но в ряде случаев он может попросту ничего не находить. Этот шаблон можно расширить используя следующие модификации.
2.1 Приоритеты поиска заголовка
Иногда бывает так, что под конкретным заголовком на одном примере могут быть нужные нам данные а в другом эти данные находятся под другим заголовком. А этот заголовок используется совершенно для других целей.
Обычно такими заголовками бывают строки состоящие из одного слова: Дата, Сумма, Число, №. Указывая все заголовки в одном элементе поиска мы получаем всегда тот объект у которого оценка качества гипотезы выше.
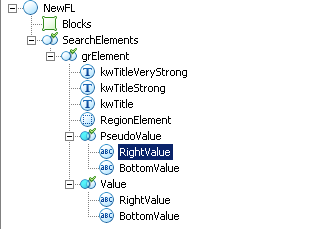
В большинстве случаев однословные заголовки побеждают. Для этого можно разделить заголовки на необходимое количество уровней. А в качестве конечного заголовка задать регион.

В данном случае выделили 3 уровня заголовков, в каждом из которых указали значения заголовков от более частных к более общим. А для указания области значения в элементе типа Region применим прикладные вычисления:
// Если обратить внимание, то можно заметить что прикладные вычисления очень похожи на язык VBScript ;) if kwTitleVeryStrong.IsFound then RestrictSearchArea(kwTitleVeryStrong.Rect); else if kwTitleStrong.IsFound then RestrictSearchArea(kwTitleStrong.Rect); else RestrictSearchArea(kwTitle.Rect);
Здесь функция RestrictSearchArea задаёт область элемента RegionElement. Ну а методы IsFound соответственно дают данные о том найден ли элемент. Данная конструкция позволит вам искать заголовки в порядке значимости. А уже поиск значения опирается на данный элемент RegionElement.
А самые догадливые думаю заметят, что здесь аналогично можно было бы применить элемент группа первого вхождения, как в случае поиска значения, но это сделано умышленно дабы показать возможности Flexy Layout Studio.
2.2. Поиск по части значения
В некоторых неординарных случаях может так получиться что у нас значение находится ниже заголовка. А структура указанная выше находит значение справа от заголовка. В данном случае можно воспользоваться поиском по части значения. Частью значения может выступать любая часть значения которая имеет строго типизированную форму. К таким можно отнести различные числовые данные, номера, даты, возможно в некоторых случаях применение частей выражения (к примеру "договор № от ").
Перед поиском самого выражения создаётся структура аналогичная поиску самого значения. Отличие лишь в том, что элементы поиска части значения имеют различные ограничения: Для числовых данных это ограничение алфавита поиска. Для дат это собственно типизация конкретным типом элемента. Для частей выражения это использование регулярных выражений.
Сами элементы поиска значений уже ищутся при помощи относительного местоположения около части значения, либо напрямую зашиваются в прикладном коде.
2.3. Исключение областей поиска
Ещё более распространённая ситуация когда мы находим не то что нам нужно хотя шаблон под все предыдущие варианты отработал на ура. Одна из таких ситуаций может возникнуть если сам заголовок находится в тексте.
В этом случае мы можем попросту исключить некоторые области изображения.
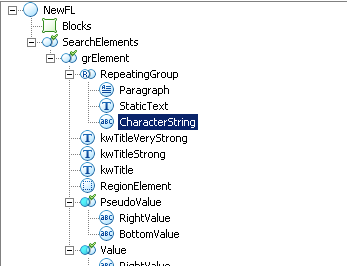
В данной структуре применяются группа повторяющихся элементов, в которую можно добавить любые интересующие нас элементы. Чаще всего исключается текст (На изображение Paragraph). Реже какие либо шаблоны текстовых фраз и алфавита (вставлен ради примера). Саму группу добавляется в исключения областей поиска других элементов, к примеру элементов поиска заголовка. Таким образом, к примеру, мы исключим появление заголовка в тексте и найдём уже более нужное нам значение.
2.4. Ограничение области поиска при помощи разделителя.
В документах, особенно финансовых, данные часто располагаются в таблицах (не путать с табличными данными, где количество данных неограниченно, и они повторяются по структуре).
И сами значения как и заголовки ограниченны рамками таблицы. Для ограничения зоны поиска можно использовать элемент Separator.
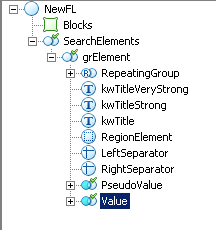
Мы добавляем два элемента LeftSeparator и RightSeparator. Сразу хочется оговорится что такой метод работает только для значения расположенного снизу. Для значения расположенного справа не имеет смысла искать верхний и нижний разделитель так как текст обычно совпадает по высоте а также располагается на одной оси с заголовком.
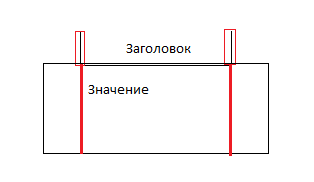
При помощи LeftSeparator и RightSeparator мы находим левую и правую границу ячейки. Эти границы в большинстве случаев продолжаются и до значения. Тем самым мы ограничиваем область поиска почти в 1,5 раза. Благодаря этому можно исключить поиск в соседних ячейках таблицы.
2.5. Поиск без полей без заголовка. Поиск при помощи данных из СУБД.
Самый коварный случай, когда одиночные данные без заголовка. Здесь уже стоит поступать в зависимости от ситуации: применять строгую типизацию: Дата, Сумма; ограничивать область поиска: к примеру общая сумма, дата документа обычно располагается внизу страницы. и др. методы
Для текстовых данных (к примеру название организации) можно применить поиск значении при помощи данных из СУБД. Особенно это хорошо получается в отношении к СЭД, в частности к Directum.
string ConnectionString = "Provider=SQLOLEDB.1;Password=;Persist Security Info=True;User ID=Administrator;Initial Catalog=DIRECTUM;Data Source=MSSQL2008R2"; string VendorNameQuery = "select a.NameAn from MBAnalit a join MBVidAn v on v.Vid = a.Vid where v.Kod='ОРГ'"; // 5000 - максимальное количество записей возвращаемое в запросе. SearchTextFromDB: ConnectionString, VendorNameQuery, 5000;
Здесь добавив прикладной код выше мы ограничиваем поиск только конкретными текстовыми значениями.
Авторизуйтесь, чтобы написать комментарий