Серия статей. SQL внутри. Статья третья. Читаем план запроса. Часть вторая. Итераторы агрегаторы
Правила серии статей
В каждой статье я буду упоминать правила, оглашенные еще в первой. А тебя, мой читатель, прошу их принять:
- Статья не будет описывать все подробности. Область обсуждения такова, что всегда будут оставаться утверждения, которые здесь будут приняты за аксиомы.
- Статья - руководство к размышлению, но никак не к действию. Применив рекомендации не обдумав и не обточив под себя, Ты что ни будь сломаешь.
- Факты, указанные в статье, не претендуют на правду в последней инстанции. Если ты, мой читатель, обнаружишь, что я написал неправду, я прошу тебя максимально подробно с ссылками, экспериментами, скриншотами рассказать сообществу правду.
В первой статье мы с тобой знакомились с компиляциями
http://club.directum.ru/post/Serija-statejj-SQL-vnutri-Statja-pervaja-Kompiljacija-zaprosa.aspx.
Во второй статье мы знакомились с необходимыми и лишними индексами
http://club.directum.ru/post/Serija-statejj-SQL-vnutri-Statja-vtoraja-Zhelaemye-i-nezhelatelnye-indeksy.aspx.
В первой части третьей статьи мы познакомились с основными итераторами плана запроса
http://club.directum.ru/post/Serija-statejj-SQL-vnutri-Statja-tretja-Chitaem-plan-zaprosa-Chast-pervaja.aspx. Во второй части третьей статьи (т.е. в этой статье) рассмотрим итераторы из группы агрегаторов.
Базовые итераторы плана (продолжение)
Агрегаторы
Рассмотрим три типа агрегации:
- скалярная потоковая (scalar stream). Агрегация без условия GROUP BY;
- потоковая (stream). Агрегация с условием GROUP BY;
- по хэшу (hash).
Скалярная потоковая агрегация
Скалярная потоковая агрегация выполняется в запросах с функциями агрегации в SELECT части и без GROUP BY условий.
Скалярная потоковая агрегация всегда возвращает одну строку.
Рассмотрим простой пример:
SELECT COUNT(*) FROM Table_1


Что здесь делает SQL:
- получает строки с колонкой кластерного индекса. Т.к. последовательное сканирование строк кластерного индекса, это самая быстрая операция чтения без WHERE условий;
- считает полученные строки. Функция Count() всегда возвращает результат в формате BIGINT ;
- конвертирует результаты из BIGINT в тип INT.
Рассмотрим еще пример:
SELECT MIN(Column6), MAX(Column6) FROM Table_1

Что здесь делает SQL:
- получает строки из кластерного индекса. По статье http://club.directum.ru/post/Serija-statejj-SQL-vnutri-Statja-tretja-Chitaem-plan-zaprosa-Chast-pervaja.aspx мы помним, что кластерный индекс возвращает все колонки;
- по набору строк одновременно ищет максимум и минимум. Заметь, что конвертация результатов не требуется т.к. функция MIN() и MAX() дает тип на основе искомой колонки.
Рассмотрим еще пример:
SELECT AVG(Column7) FROM Table_1

Что здесь делает SQL:
- получает значение колонки Column7 из кластерного индекса;
- считает количество строк и сумму всех строк;
- если количество равно нулю, то выдавать NULL; если количество не равно нулю, то поделить сумму на количество.
Рассмотрим пример с DISTINCT:
SELECT DISTINCT(Column2) FROM Table_1

Что здесь делает SQL:
- получает все значения колонки Column2 из кластерного индекса;
- т.к. эта колонка не входит в первое ключевое поле какго-либо индекса, то ее значения не отсортированы, поэтому нужно их отсортировать, например, по возрастанию, при это исключая повторяющиеся.
Примечание: сортировка выполняется долго? - подсунь кластерный индекс:

Ты знаешь, значения кластерного индекса физически отсортированы.
Потоковая агрегация
Потоковая агрегация выполняется в запросах с функциями агрегации в SELECT части и с GROUP BY условиями.
Логика работы:
Потоковая агрегация получает на вход данные, отсортированные по GROUP BY условию.
Сортировка может быть взята чтением данных из индекса. А при отсутствии подходящего индекса SQL придется отсортировать данные в оперативной памяти или TempDB.
Сортировка гарантирует, что строки с одинаковым значением колонок GROUP BY условия будут соседями.
Псевдокод логики работы потоковой агрегации:
clear the current aggregate results
clear the current group by columns
for each input row
begin
-- Если текущая значение колонок GROUP BY условия не совпадает с предыдущей, то
if the input row does not match the current group by columns
begin
-- Записать строку в результирующий набор данных
output the current aggregate results (if any)
clear the current aggregate results
set the current group by columns to the input row
end
update the aggregate results with the input row
end
Например, чтобы подсчитать сумму по условию GROUP BY итератор потоковой агрегации считывает каждую входную строку. Если очередная строка принадлежит текущей группе GROUP BY условий, то итератор увеличивает сумму.
Если очередная строка не принадлежит
текущей группе GROUP BY условий, то итератор записывает сумму в результирующий набор, обнуляет сумму и прибавляет к ней очередную цифру.
Простой пример:
SELECT Column6, Column7, COUNT(*) FROM dbo.Table_1 GROUP BY Column6, Column7
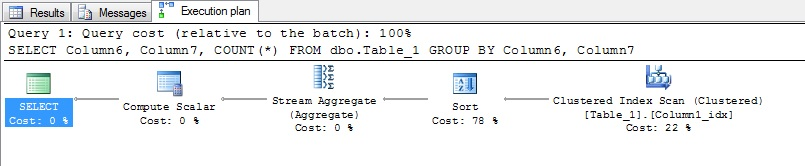

План очень похож на первый пример скалярной потоковой агрегации. За исключением сортировки.
Что здесь делает SQL:
- получает набор данных из кластерного индекса;
- сортирует его по колонкам условия GROUP BY;
- подсчитывает сумму по повторяющимся значениям GROUP BY условий;
- конвертирует результат в тип int.
Второй пример. Добавляем сортировку, но по тем же условиям.
SELECT Column6, Column7, COUNT(*) FROM dbo.Table_1 GROUP BY Column6, Column7 ORDER BY Column6, Column7

План отличается лишь тем, что оптимизатор поменял порядок колонок сортировки, чтобы второй раз не сортировать. Было Column7, Column6 стало Column6,Column7. Таким образом порядок колонок для GROUP BY собственно не важен.
Третий пример. Как ты уже догадался, операция сортировки весьма ресурсоёмкая, и индекс может нам помочь ее избежать.
SELECT Column1, COUNT(*) FROM dbo.Table_1 GROUP BY Column1

Четвертый пример. DISTINCT как потоковая агрегация. Возможна только тогда когда подходит индекс, иначе используется SORT DISTINCT.
SELECT DISTINCT Column1 FROM dbo.Table_1

Индекс подходит - будет потоковая агрегация.
Пятый пример. Подходящего индекса нет - будет SORT DISTINCT
SELECT DISTINCT Column2 FROM dbo.Table_1
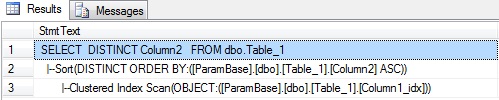
Шестой пример. Две потоковые агрегации и DISTINCT.
SELECT Column2, COUNT(*), COUNT(DISTINCT Column3) FROM dbo.Table_1 GROUP BY Column2

Что здесь делает SQL:
- получает набор данных из кластерного индекса путем последовательного сканирования;
- подходящего индекса по колонкам Column2 и Column3 нет, поэтому выполняет сортировка по этим колонкам;
- считает отдельно общее количество;
- считает отдельно с DISTINCT;
- конвертируется результаты
Агрегация по хэшу
Логика работы агрегации по хэшу сходна с HASH JOIN (http://club.directum.ru/post/Serija-statejj-SQL-vnutri-Statja-tretja-Chitaem-plan-zaprosa-Chast-pervaja.aspx).
Аналогично HASH JOIN хэш агрегация:
- не требует отсортированные наборы данных на входе;
- требует оперативную память;
- является блокирующим итератором, т.е. не выдает результат построчно, пока все строки не будут обработаны;
- хороша для больших наборов обрабатываемых данных и эффективно в планах запросов, выполняющихся с параллельными итераторами.
Псевдокод логики работы:
for each input row
begin
calculate hash value on group by column(s)
check for a matching row in the hash table
if matching row not found
insert a new row into the hash table
else
update the matching row with the input row
end
output all rows in the hash table
Примечание:
- перед выполнением хэш агрегации SQL оценивает количество памяти под хэш таблицы. Количество памяти пропорционально количеству уникальных значений GROUP BY колонок;
- если оптимизатор ошибается, то происходит сброс хэш таблиц в TempDB, что сразу ухудшает быстродействие;
Таким образом оптимизатор предпочтет выполнить хэш агрегацию при следующих условиях:
- исходный набор строк очень большой;
- условие GROUP BY из исходного набора дает значительно меньше строк;
- нет условия ORDER BY;
- нет возможности считать отсортированный набор из индекса
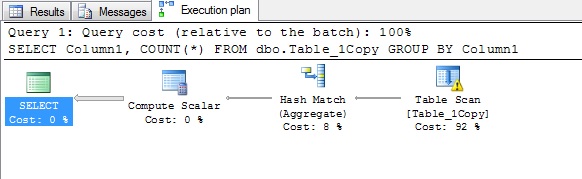
Пример. Воспользуемся небольшой хитростью. Скопируем таблицу, и используя недокументированную возможность заставим оптимизатор думать, что количество строк в таблице огромное.
SELECT * INTO dbo.Table_1Copy FROM dbo.Table_1 UPDATE STATISTICS dbo.Table_1Copy WITH ROWCOUNT = 10000000, PAGECOUNT = 1000000; SELECT Column1, COUNT(*) FROM dbo.Table_1Copy GROUP BY Column1

Авторизуйтесь, чтобы написать комментарий