DIRECTUM. Отказоустойчивость и масштабируемость.
Предисловие
Я думаю, что многие за свою карьеру сталкивались с ситуацией, когда то или иное решение в какой-то момент времени требовало увеличения производительности оборудования, например, в связи с увеличением нагрузки, связанной с подключением новых пользователей, добавлением новой функциональности или просто увеличением интенсивности работы. Приобретение нового более производительного решения на текущий момент по тем или иным причинам невозможно.
С другой стороны, если система изначально проектировалась как отказоустойчивое решение и была рассчитана на достаточно высокие нагрузки, то весьма вероятно, что затраты на оборудование были весьма существенны. В связи с этим возникает вопрос, возможно ли как-то эффективно использовать уже имеющееся оборудование, сохраняя изначально заложенную отказоустойчивость, при этом масштабировать систему до необходимых размеров.
С высокой долей вероятности, на примере сервера СУБД системы DIRECTUM можно сказать - да.
Исходные данные
На текущий момент система DIRECTUM с версии 5.0 и выше поддерживает механизм SQL-сервера AlwaysOn в части распределения нагрузки.
Но на текущий же момент в системе DIRECTUM в рамках поддержки механизма AlwaysOn отсутствует реализация отказоустойчивости.
Задача
Организовать для системы DIRECTUM развертывание высокодоступной (High Availability) архитектуры с возможностью распределения нагрузки на несколько серверов.
Анализ
Пример отказоустойчивой схемы сервера СУБД, рекомендуемой службой поддержки DIRECTUM выглядит следующим образом:

Из схемы следует, что один из серверов в каждый конкретный момент времени является активным, второй же находится в режиме ожидания (пассивная нода). Как только на активной ноде возникает неисправность служба SQL переезжает на пассивную ноду. Пассивная нода стает активной. Тем самым мы получаем High Availability схему.
Немного скорректировав схему и дополнив ее одним сервером, соизмеримой мощности и производительности получим следующую:
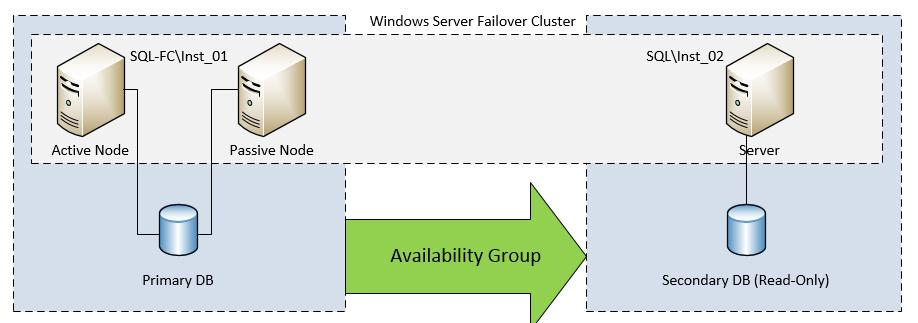
Схема остается высокодоступной, но в дополнение мы получаем распределение нагрузки с помощью механизма AlwaysOn.
На текущий момент эта схема является наиболее эффективной с точки зрения поддерживаемых технологий, а также затрат на поддержку/оборудование.
Краткое описание схемы
● Имеем экземпляр SQL-сервера SQL-FC\Inst_01, который развернут на основе Failover Cluster. При этом, одна из нод кластера в конкретный момент является активной, вторая нода в этот момент всегда является пассивной, чтобы в случае сбоя активной переключить всю нагрузку на себя. Т.е. 50% оборудования сервера простаивает (кроме СХД). На этом инстансе расположена основная база данных DIRECTUM (Primary).
● На дополнительном сервере развернут еще один экземпляр SQL-сервера SQL\Inst_02. На этом сервере будет расположена вторичная БД доступная только для чтения (Secondary).
● На основе обоих инстансов создается Availability Group, в результате чего получаем распределение нагрузки между двумя серверами.
Развертывание
Развертывание решения можно разбить на несколько основных этапов (детальнее этапы расписаны в существующих инструкциях системы DIRECTUM):
● Развертывание Windows Server Failover Cluster (WSFC) из двух нод (с Quorum-диском).
● Развертывание на этих двух нодах отказоустойчивого экземпляра SQL-сервера.
● Добавление в WSFC третьего сервера, с установленным экземпляром СУБД.
● Выполнение подготовки БД DIRECTUM для развертывания в группе доступности.
● Развертывание групп доступности (Availability Group).
● Корректировка настроек ресурсов кластера (owners, vote).
● Корректировка настроек DIRECTUM: PercentageOfPossibleConnectionsToReadOnlyServers (балансировка нагрузки) и GetDataFromReadOnlyServerTimeLag (задержка распространения данных на вторичный сервер).
Выводы
1. Тестирование показало, что дополненная схема с использованием Failover Cluster Instance (FCI) и групп доступности (Availability Group) AlwaysOn вполне работоспособна.
2. Отказоустойчивость реализуется с помощью механизма Failover Cluster Instance (в данном случае реализуется отказоустойчивость всего экземпляра СУБД)
3. Распределение нагрузки происходит за счет использования групп доступности путем отправки части запросов на вторичную БД, доступную только для чтения (в данном случае реализуется распределение нагрузки только БД).
4. Схема будет работоспособна при отказе вторичного ReadOnly сервера, а также отказе одной из нод Failover Cluster-а.
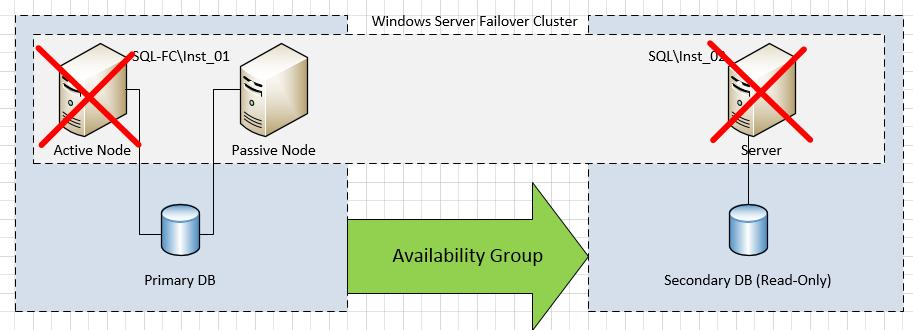
5. Время восстановления работоспособности при сбое составляет от нескольких десятков секунд до нескольких минут.
6. Схема лицензирования SQL сервера предполагает лицензирование SQL-сервера для активной ноды FCI и лицензирование SQL-сервера дополнительного сервера. Для обеих лицензий предполагается использование Enterprise-редакции SQL. Версия SQL от 2012 и выше.
7. После развертывания дополнительно необходимо явно убедиться, что сервер, на котором расположена вторичная ReadOnly БД не может быть владельцем кластеризованного инстанса (см. свойства кластера).
8. При развертывании групп доступности на версии Windows Server 2008, 2008 R2 необходима установка дополнительных критичных обновлений (подробности см. тут).
9. Не рекомендуется использование Failover Cluster Manager (FCM) для управления группами доступности, в частности:
● Добавлять или удалять ресурсы в кластеризованные службы групп доступности.
● Изменять любые свойства групп доступности, в т.ч. возможного и предпочитаемого владельца. Это свойство устанавливается автоматически на группу доступности.
● Перемещать группы доступности на различные ноды, т.к. в этом случае у FCM нет информации о синхронизации доступных реплик и в связи с этим может увеличиться время простоя. Для этих целей рекомендуется использование t-sql или Management Studio.
P.S.
В статье была сделана попытка обобщить данные документации системы DIRECTUM и рекомендации Microsoft по организации высокодоступных и масштабируемых решений.
Статья не является пошаговой инструкцией, а дает лишь взгляд сверху на то, как может быть организована архитектура решения в вашей организации, акцентируя внимание на некоторых нюансах, которые не очевидны изначально.
Начинаем спорить! )
Я бы не назвал схему классического Failover-кластера и работу в нем SQL схемой высокой доступности. Failover - это быстрое восстановление после сбоя. Время доступности конечно, в этом случае, повыше, чем при ручном восстановлении отказа, но тем не менее, отказ в обслуживании будет, хоть и недолго. А если рассматривать обычный Failover в сравнении с AlwaysOn - то вот как раз последняя технология и обеспечивает HA. По крайней мере, при использовании данной технологии (даже в редакции Standard, при невозможности читать из вторичной реплики - Basic Availability Group), отказа в обслуживании при сбое основного сервера не происходит вообще.
Владимир, полностью с Вами согласен!
Но по поводу "...Время доступности ...повыше..." уточню, что при использовании Failover оно выше в десятки и более раз, чем при ручном восстановлении.
С другой стороны на примере системы DIRECTUM переключение во время сбоя на пассивную ноду со стороны пользователей будет выглядеть как единичная ошибка и то в том, случае если они в этот момент отправили какой-либо запрос непосредственно на СУБД. Т.е. большинство пользователей просто не заметит проблем.
Если так рассуждать, то тут также можно сказать, что время простоя также имеет место быть, что подтверждено данными MS, хотя оно еще меньше:
High Availability and Disaster Recovery
SQL Server Solution
Potential Data Loss (RPO)
Potential Recovery Time (RTO)
Automatic Failover
Readable Secondaries(1)
AlwaysOn Availability Group - synchronous-commit
Zero
Seconds
Yes(4)
0 - 2
AlwaysOn Availability Group - asynchronous-commit
Seconds
Minutes
No
0 - 4
AlwaysOn Failover Cluster Instance
NA(5)
Seconds
-to-minutes
Yes
NA
Database Mirroring(2) - High-safety (sync + witness)
Zero
Seconds
Yes
NA
Database Mirroring(2) - High-performance (async)
Seconds(6)
Minutes(6)
No
NA
Log Shipping
Minutes(6)
Minutes
-to-hours(6)
No
Not during
a restore
Backup, Copy, Restore(3)
Hours(6)
Hours
-to-days(6)
No
Not during
a restore
(1) An AlwaysOn Availability Group can have no more than a total of four secondary replicas, regardless of type.
(2) This feature will be removed in a future version of Microsoft SQL Server. Use AlwaysOn Availability Groups instead.
(3) Backup, Copy, Restore is appropriate for disaster recovery, but not for high availability.
(4) Automatic failover of an availability group is not supported to or from a failover cluster instance.
(5) The FCI itself doesn’t provide data protection; data loss is dependent upon the storage system implementation.
(6) Highly dependent upon the workload, data volume, and failover procedures.
А вообще конечно ждем и надеемся, что в новых версиях системы DIRECTUM будет реализована поддержка отказоустойчивости на уровне AlwaysOn.
Уточню: утверждение справедливо, если сервер сеансов вынесен за пределы кластера на отдельный сервер/виртуальную машину.
Авторизуйтесь, чтобы написать комментарий