Подсистема извлечения контента документа, автоматической классификации и структурирования обращений граждан
в 2-3 раза
сокращение времени на обработку обращения
в 2-3 раза
сокращение трудоемкости обработки документа
Суть идеи
Идея заключается в создании подсистемы для определения контента документа (text mining) из обращений граждан, автоматической классификации и структурирования этой информации для предоставления пользователю.
Область применения и назначение
Такое решение необходимо для автоматического определения предметной области содержимого документа(о чем он), классификации этой информации и структурированию её по областям применения, категориям и ответственным лицам, а так же помощи в выстраивании бизнес-процессов обработки данной информации.
Подсистема может автоматически анализировать контент документа(с использованием техник text mining) и предоставлять пользователю дополнительную информацию о документе. Так же подсистема может автоматически формировать облако меток для пользователя и вести общую статистику для отчетности(и возможно дальнейшего анализа).
Автоматическое распознавание текста документа позволит при просмотре/рассмотрении документа сотрудником, оставлять им комментарии и заметки к этому документу, независимо от его типа. Заметки будут доступны всем, кто будет выполнять работы по документу либо учитывать его в своей работе
В чем новизна идеи/проекта
Главная новизна идеи в том, что поступившая информация, предварительно, автоматически обрабатывается компьютером, и предоставляется пользователю в более удобном, дополненном виде. Можно сказать .что у пользователя появляется в некотором роде «помощник» по работе с большим количеством документов.
Контент для анализа из документа набирается двумя способами: анализом самой структуры файла, либо при помощи технологии распознавание текста (OCR, в случае если это графический документ — например скан рукописного документа). Использовании OCR при чтении документа пользователем, так же позволит реализовать такую интересную возможность, как добавление комментариев и заметок к документу, независимо от типа документа, загруженного в СЭД. Данные заметки в дальнейшем смогут видеть остальные пользователи, работающие с документом или бизнес процессом по нему и учитывать их в своей работе.
Дополнительно, реализация этой идеи позволит автоматическая классифицировать и структурировать информацию без участия человека. Более удобная работа с информацией.
На изображении 1. показана примерная схема обработки поступающего документа:
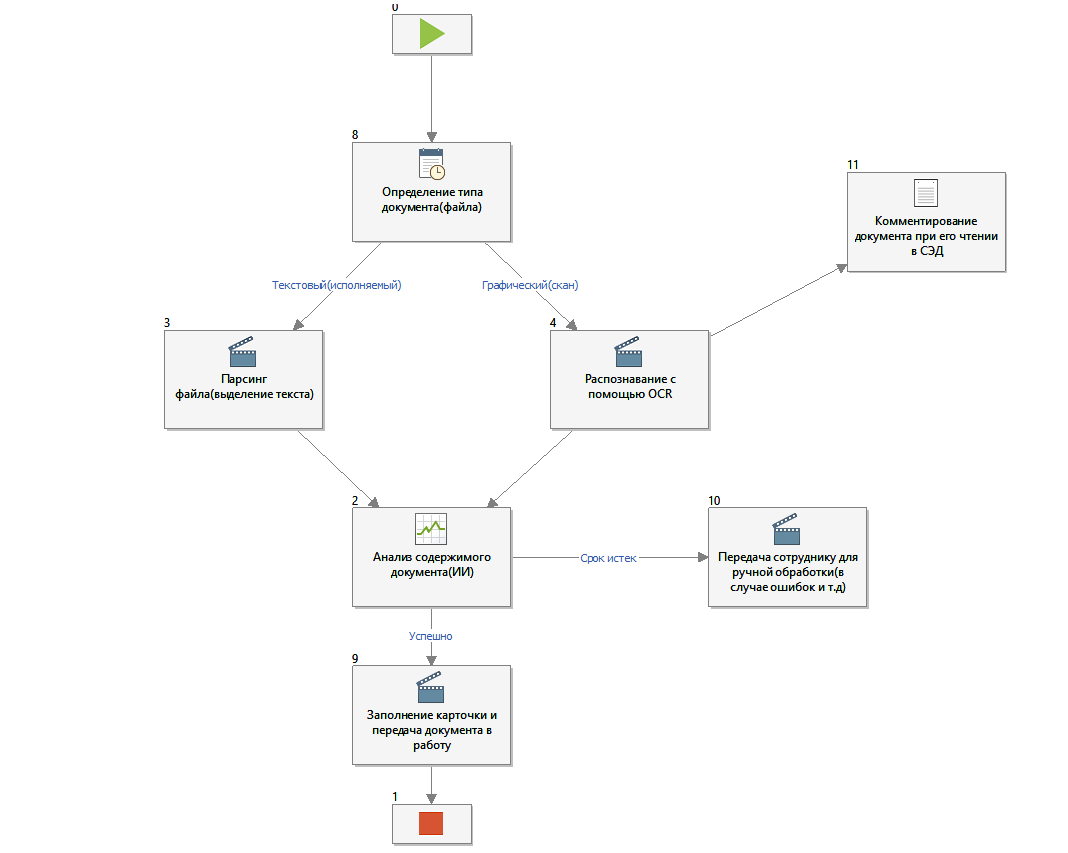
Какой эффект ожидается от внедрения инновации
Главный эффект от внедрения — это снижение нагрузки на сотрудников, количества совершаемых ими ошибок(человек может что-то не заметить или пропустить в тексте), и ускорение обработки информации органами власти, т.к часть работы сможет производиться автоматически. Например, подсистема сможет автоматически отсеивать или ставить в конец очереди документы, имеющие малозначительный или рекламный характер. Повысится удобство работы в СЭД. Как следствие, уменьшение материальных затрат на ведение документооборота.
Ускорение процесса
Ускорение процесса обработки и передачи в работу входящего документа, за счет снижения времени, необходимого сотруднику на ознакомление с ним и внесением его в СЭД. Система сама классифицирует и оповестит, о чем документ, а так же автоматически внесет его в СЭД, что позволит сотруднику направить его в работу курирующему руководителю, по сути даже не читая его(это за него уже сделала система). Ускорение процесса передачи документа в работу (т.е задержка док-та на этапе канцелярии ) в 2-3 раза.
Сокращение трудозатрат
Этот пункт тесно связан с первым, т.к часть работы за сотрудника делает система, это приводит к снижению в несколько раз трудозтрат, связанных с первичной обработкой и передачей в работу корреспонденции и документов. Например, сейчас в отделе обращений граждан аппарата Губернатора ТО, обрабатывающих корреспонденцию, работает 3 человека, они знакомятся с текстами обращений и направляют их в работу курирующим заместителям губернатора. Отдел обрабатываем примерно по 50-80 обращений в день. Сюда входит ознакомление с текстом документа, внесение его в СЭД и направление в работу.
С внедрением такой системы достаточно будет одного человека, т.к обработка документа уже проведена, он распознан, добавлен в СЭД и система выдала рекомендации, сотруднику останется только направить документ руководителю (этот процесс так же может быть автоматизирован, по сути сотрудник нужен только для контроля). Это позволит значительно снизить трудозатраты(в несколько раз) и обрабатывать всю поступающую за день корреспонденцию.
На примере отдела обращений граждан аппарата губернатора Тюменской области, сведем некоторые показатели в таблицу для оценки эффективности:
Таблица 1.
|
Описание процесса и контента для оптимизации |
Показатель/ Описание |
Применение инноваций |
|
Название и тип документа (поля документа) |
Обращение граждан. Непосредственно текст обращения |
Поступающий в систему со сканера документ распознается системой, из него выделяется текст обращения. На основе этого текста автомат. формируется карточка обращения, ей присваивается рег. номер и дат |
|
Общее количество созданных документов за год, шт. (среднее в месяц) |
В год, отдел обрабатывает в среднем от 11 до 16 тыс. обращений. По 1-2 тыс документов в месяц. |
Снижается зависимость количества обрабатываемых документов от количества сотрудников отдела. |
|
Сотрудники, работающие с документом; должности количество сотрудников |
В отделе обращений граждан на данный момент работает 3 человека, непосредственно обрабатывающих корреспонденцию. |
Для работы достаточно одного человека, для контроля. При том же объеме поступающих документов. |
|
Среднее время
|
На подготовку карточки документа, присваивание рег. Номера и связывание с похожими обращениями уходит в среднем 5-10 мин. |
Заполнение карточки документа, присваивание всех необходимых реквизитов и поиск связанных документов происходят практически моментально. |
|
Среднее время согласования |
Время согласования документов не регламентируется и для данной идеи не принципиально. |
Использование технологии распознавания текста(OCR) из состава подсистемы, позволяет реализовать такую возможность, как совместно рецензирование документа или оставление на нём заметок пользователей, без изменения текста самого документа. Заметки применяются отдельным слоем на документ и хранятся отдельно. |
|
Сканируется ли документ |
Все поступающие документы сканируются |
Умное сканирование, распознавание содержимого документа, выделение основных базисов документа: смысла, ключевых слов. Формирование облака из базисов документов тегов для СЭД. |
Почему Вы считаете идею/проект нужным и востребованным сегодня
Информации становится всё больше, а количество сотрудников, которые её обрабатывают остаётся на том же уровне. Снижается производительность труда и увеличивается нагрузка на персонал.
Так же появляется возможность часть документов с запросами переложить на «автоматическую обработку»
Какие перспективы есть у подобных проектов в России
Данный проект достаточно важен и имеет большие перспективы, причем, не только применительно к СЭД, но и в других системах обработки информации.
У вас похожая задача?
Обсудите реализацию с экспертом Directum

Хотите внедрить
похожее решение?
Оставьте заявку, и мы свяжемся с вами — определим ваши интересы и подготовим индивидуальную презентацию под ваши задачи.
Получить презентацию
Пока комментариев нет.
Авторизуйтесь, чтобы написать комментарий