Использование Ario для инвентаризации активов АО "СИСТЭМ ЭЛЕКТРИК"
~50
пользователей охвачены автоматизацией по проекту
в 3-5 раз
сократилось время на ввод документов
3 дня
срок внедрения
Следующий проект



Автор заявки
Исполнитель
Предыстория
В нашей компании долго стояла дилемма «Что больше, вложения в искусственный интеллект или польза, которую он приносит?».
По итогу летом мы взяли на тестирование вариант поставки RX Intelligence, далее прошли курсы и самостоятельно провели установку с настройкой. Реализовали распознавание писем и заполнение по ним свойств, индексацию всех сканов в системе и сравнение версий документов. Внутренний клиент был очень доволен этим.
А далее начался мозговой штурм, в каких ещё задачах можно задействовать ИИ. И ниже приведён один из кейсов.
Задача
В рамках инвентаризации активов компании возникла необходимость в автоматизации процесса распознавания и обработки Актов приёма-передачи.
Сложность заключалась в том, что раньше не было единого шаблона, и каждый специалист заполнял поля без какого-либо ограничения. Шаги, которые были пройдены для реализации распознавания архива по API через сервис ARIO, опишу в хронологическом порядке.
История проекта в 15 шагах
1. Создал новый проект в AVIA, загрузил 10 файлов для разметки.
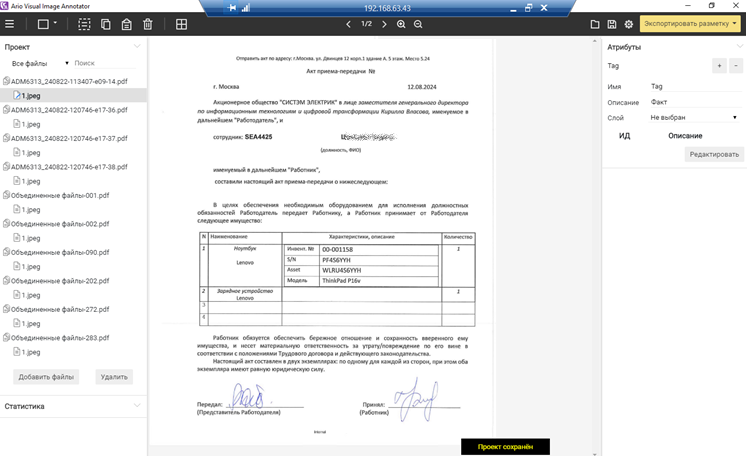
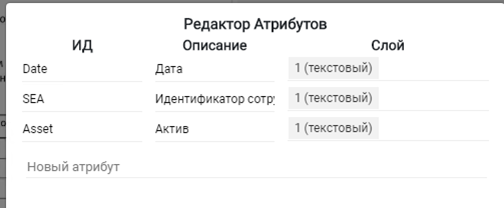
2. Задал атрибуты.
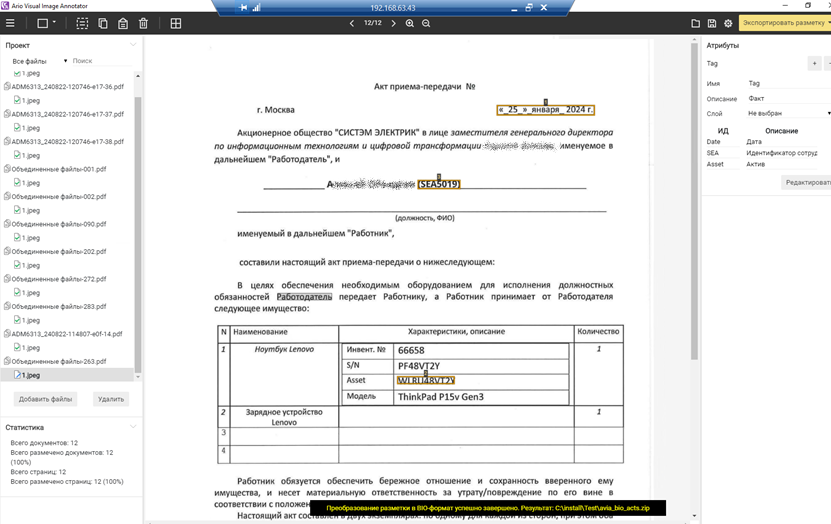
3. Разметил документы и выгрузил файл bio.
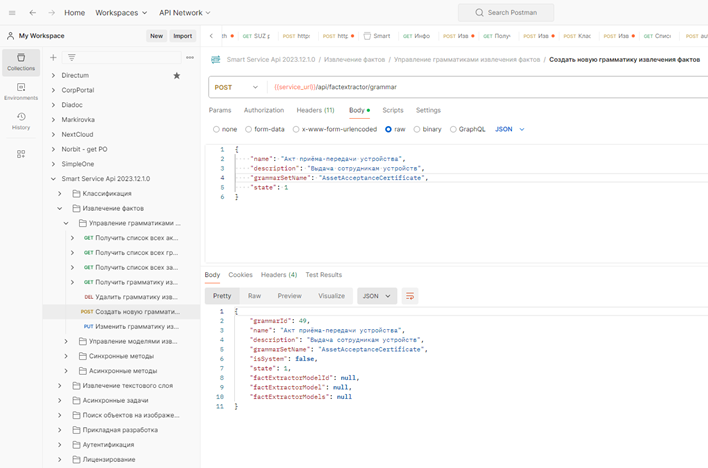
4. Создание новой грамматики для Актов приёма-передачи.

5. Обучение модели по размеченным документам.
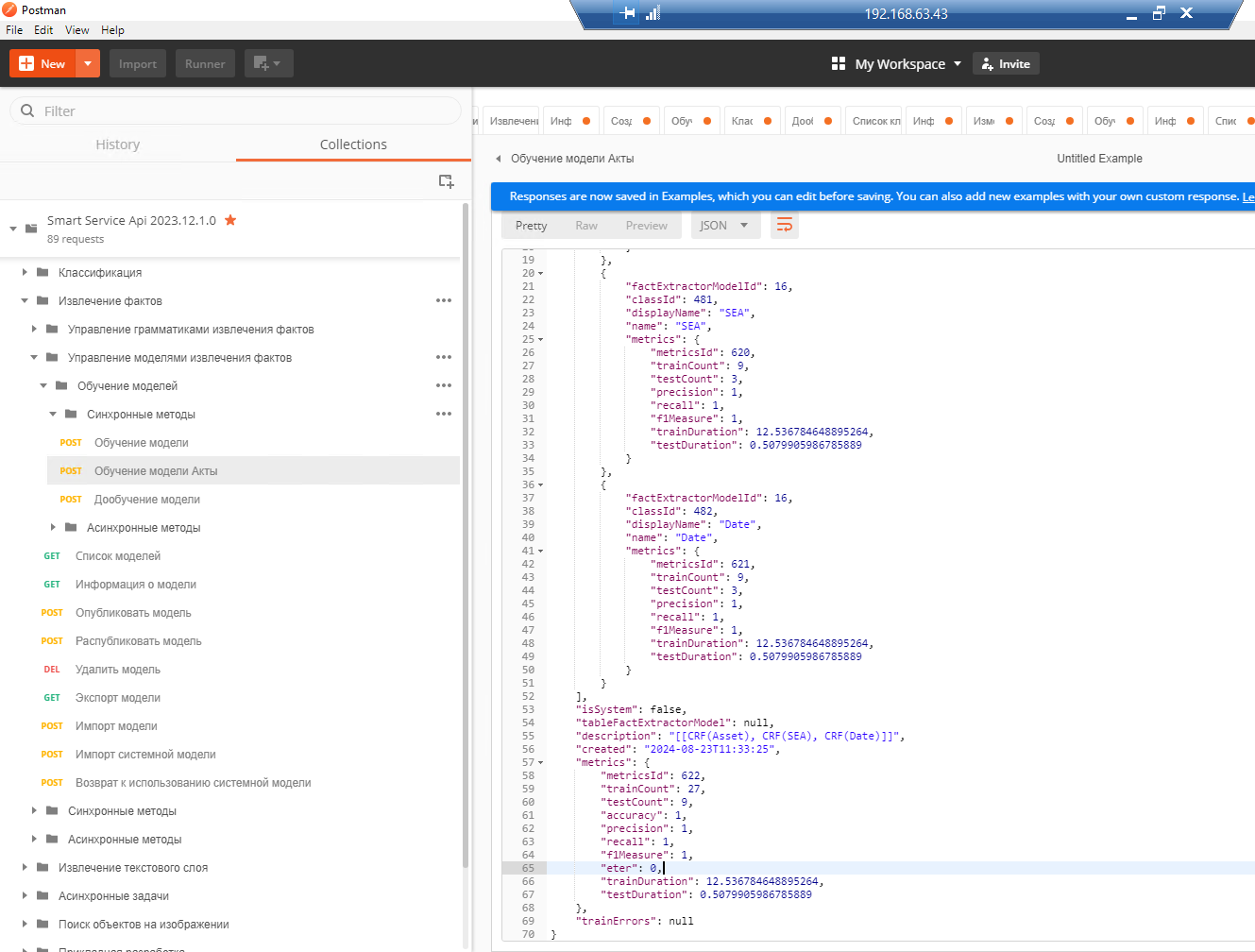
6. Проверка фактов грамматики “LaptopAcceptanceCertificate”.
На примерах:
- стандартный файл
- с повторяющимся значением
- с нестандартной датой
- идентификатор сотрудника в скобках
- с рукописным текстом
- и др.
Стандартный файл (успех)
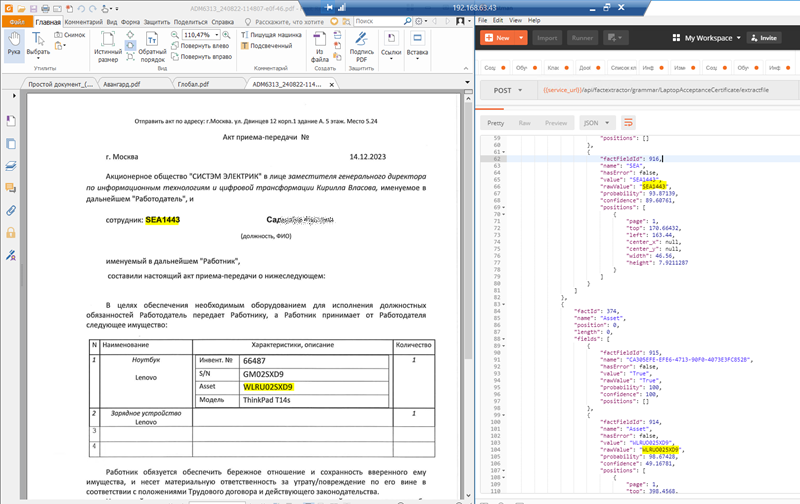
Второй пример
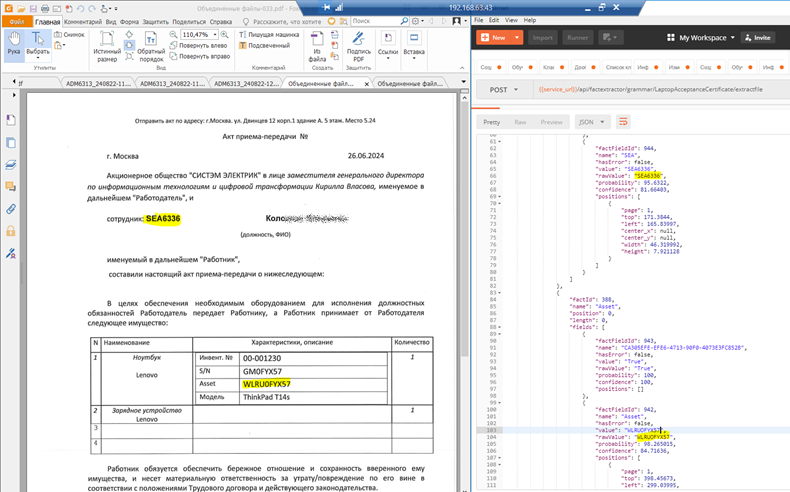
С повторяющимся значением (успех)
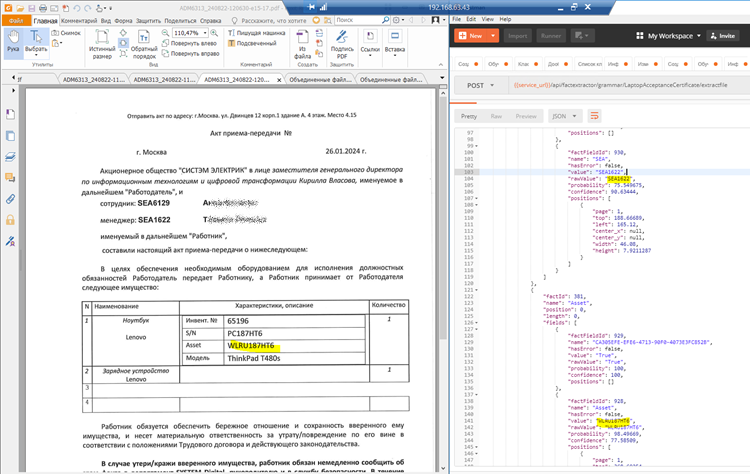
Третий пример
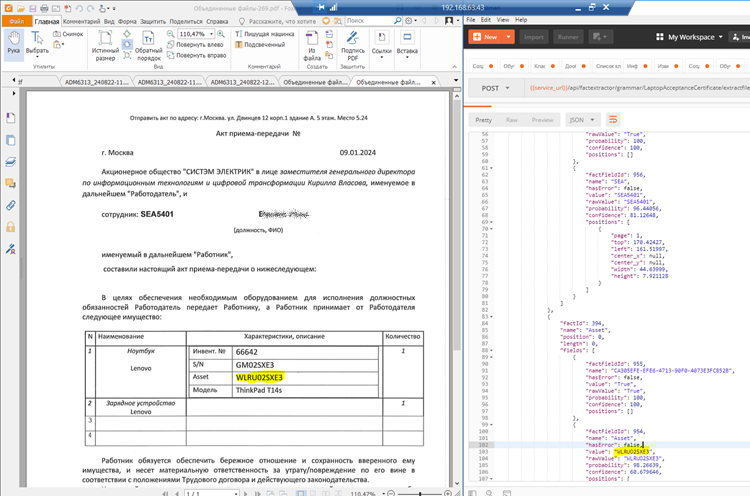
С нестандартной датой (успех)
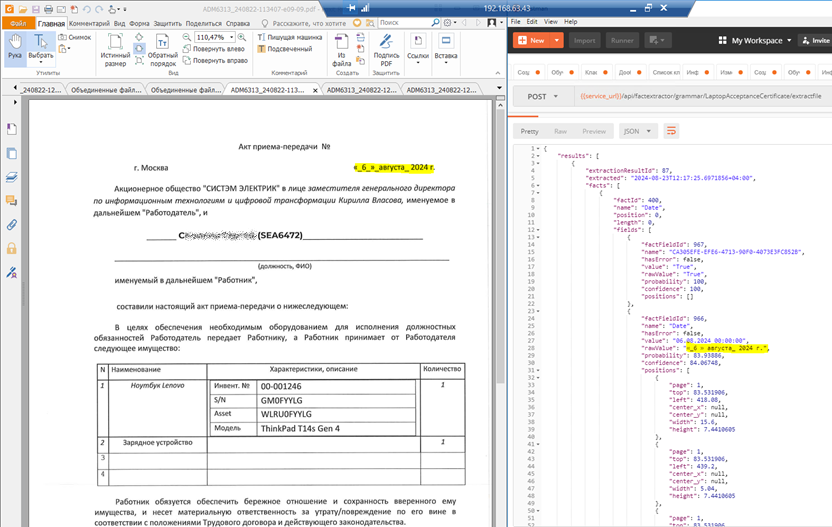
Идентификатор сотрудника в скобках (провал, кроме одного кейса)
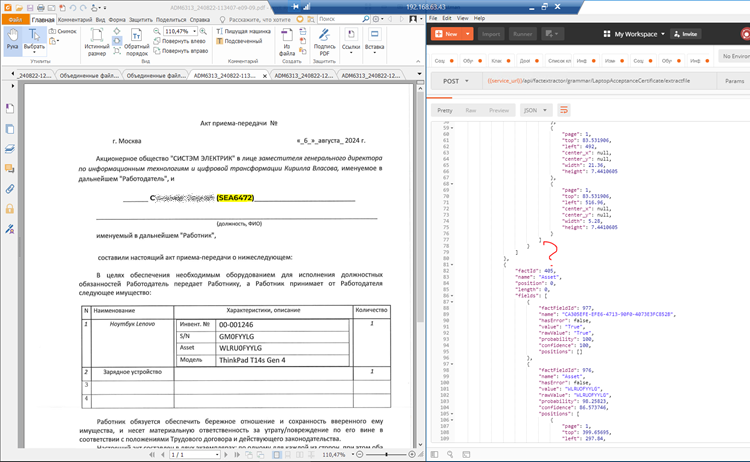
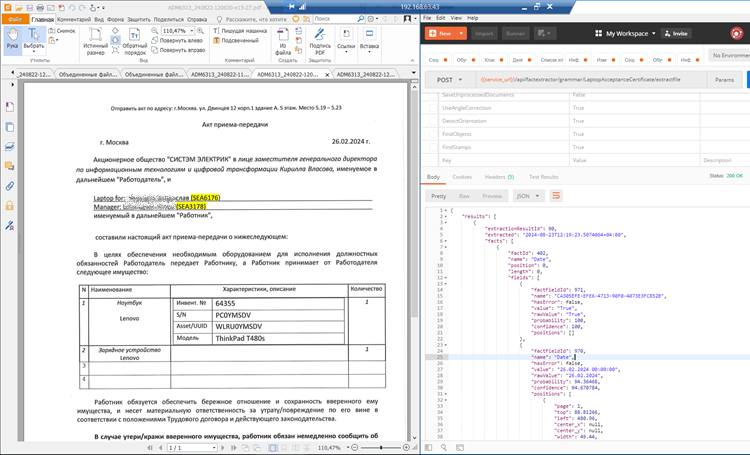
Успешный кейс:
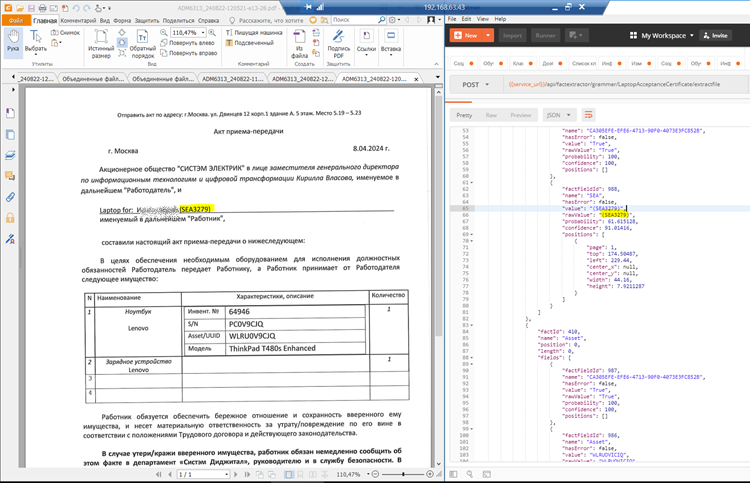
С рукописным текстом (провал)
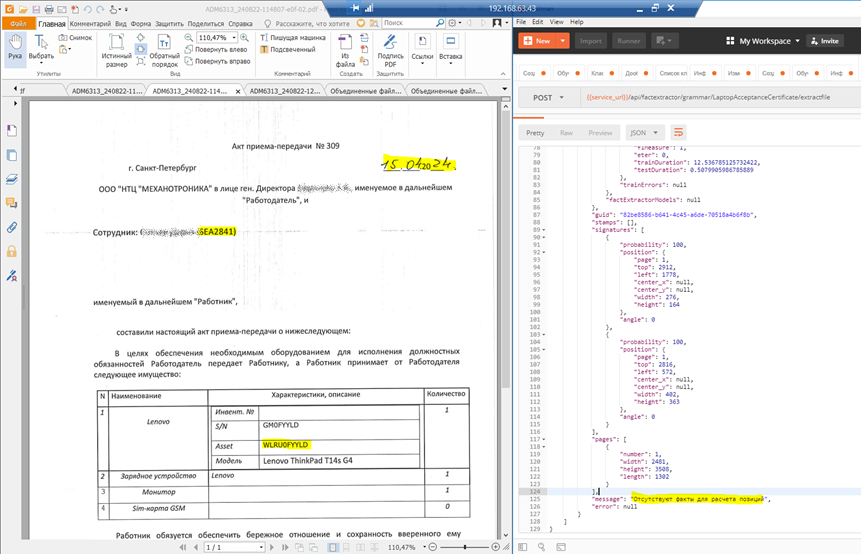
7. Переход на использование S/N вместо Asset
В рамках обсуждения было принято решение использовать S/N вместо Asset, так как далее планируется расширение на телефоны, где поле Asset пустое.
Повторно разметили 22 документа на тестовом стенде.
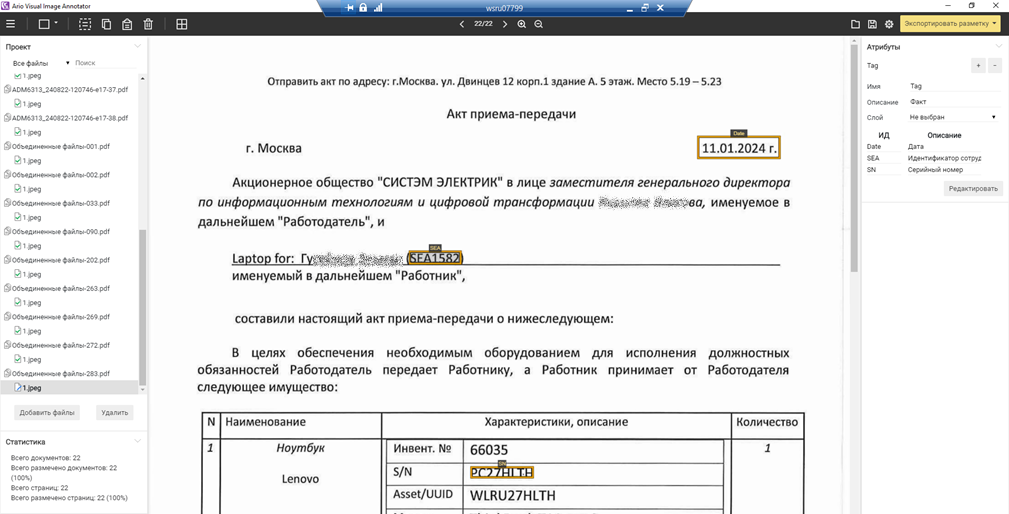
8. Создание новой грамматики для Актов приёма-передачи (на тестовом стенде)
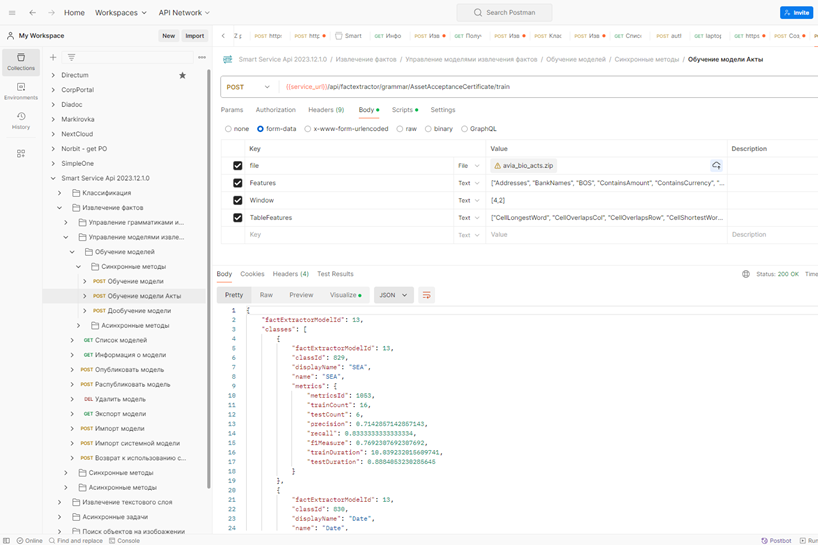
9. Обучение модели по размеченным документам:
10. Проверка фактов грамматики “AssetAcceptanceCertificate”.
На примерах:
- стандартный кейс
- двойная SEA
- нестандартная дата + кавычки
- SEA в кавычках с подчёркиванием
- и др.
Стандартный кейс (успех)
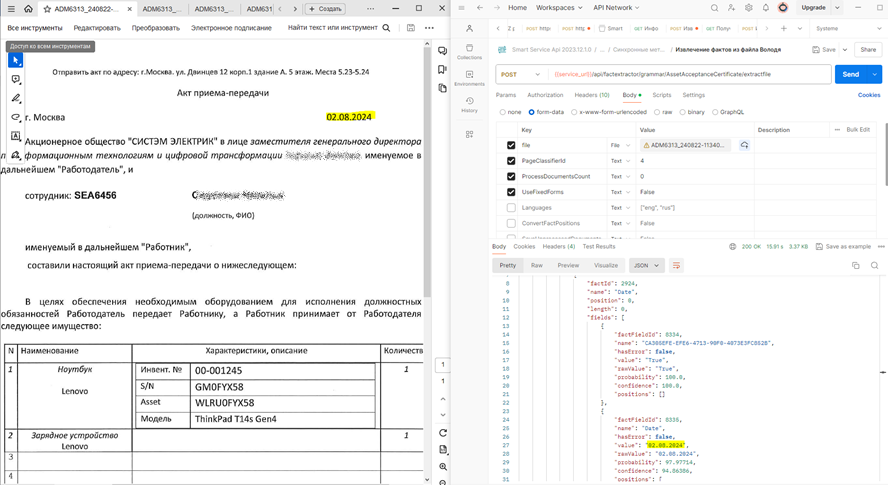
Двойная SEA (Успех):
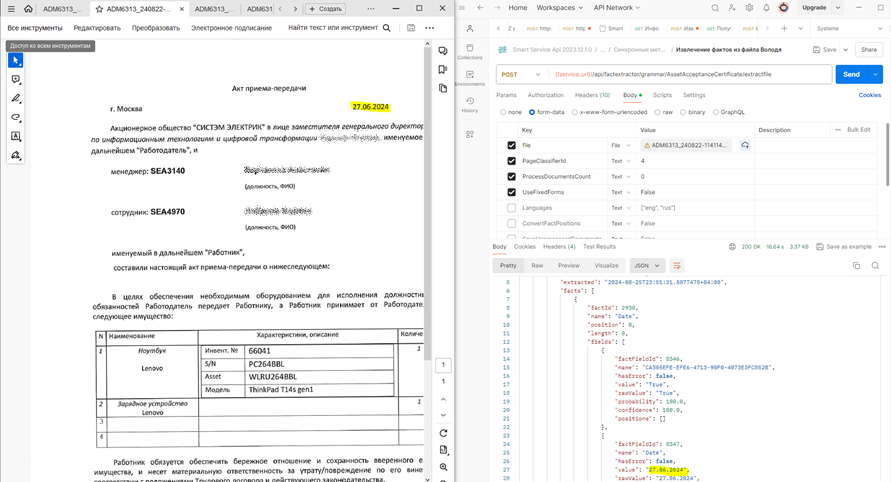
Нестандартная дата + кавычки (успех):
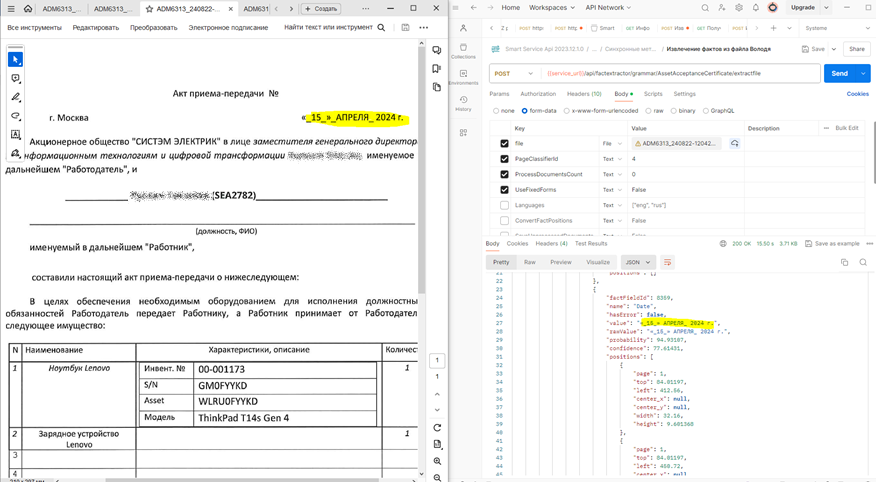
SEA в кавычках с подчёркиванием (успех):

11. Добавление форматеров для нормализации даты и SEA.
Прописал новый форматер:
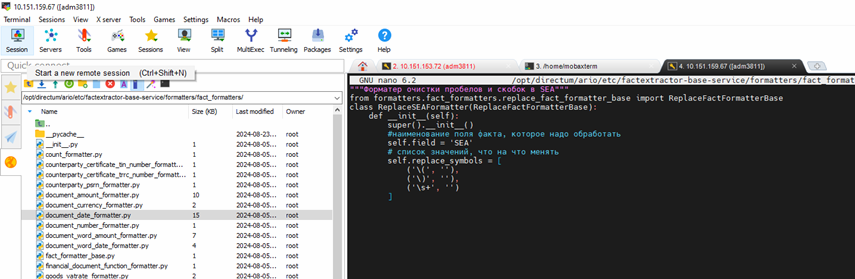
Включил новый форматер в общий список:
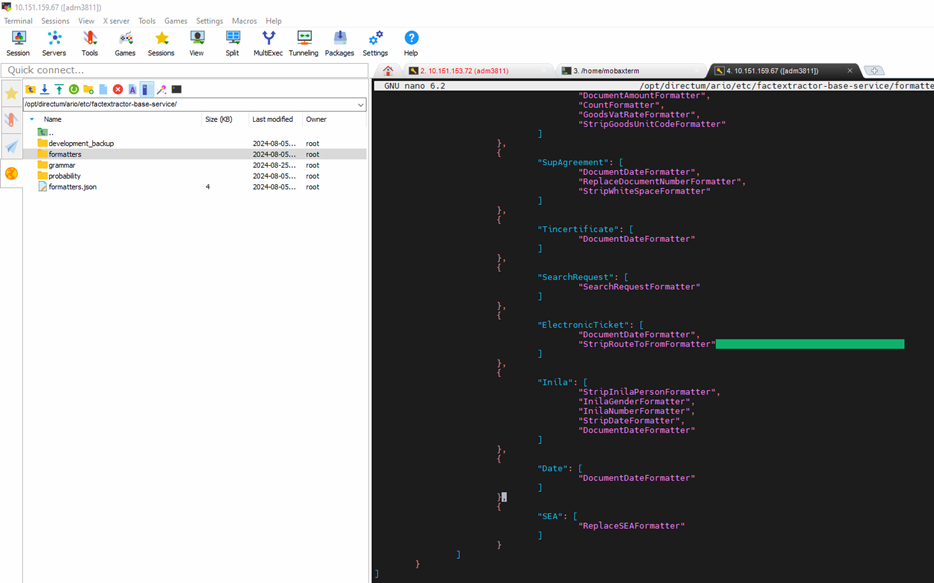
Добавил папку и файл для форматеров грамматики:

12. Проверка форматирования (успех):
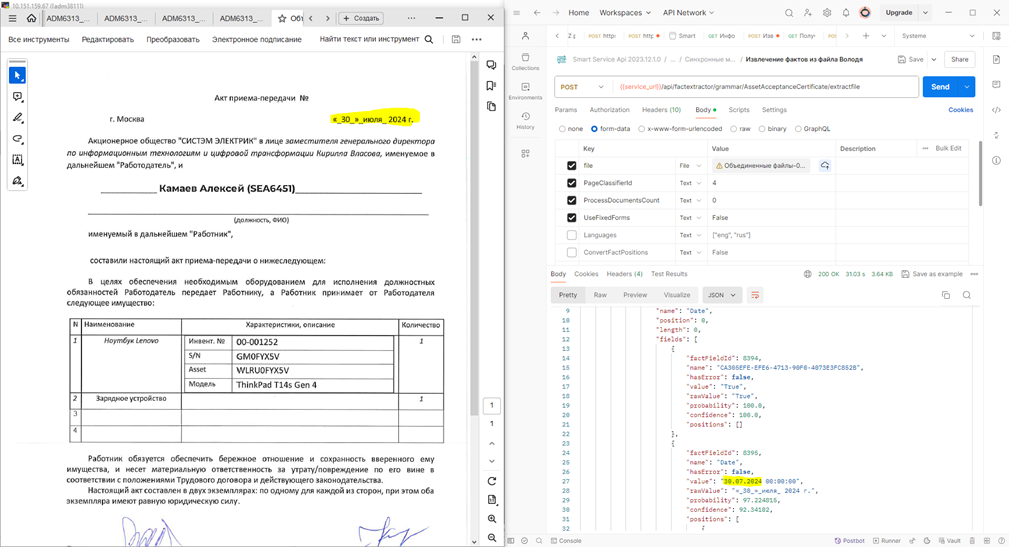
13. Тестирую скрипт на разовое распознавание документа:
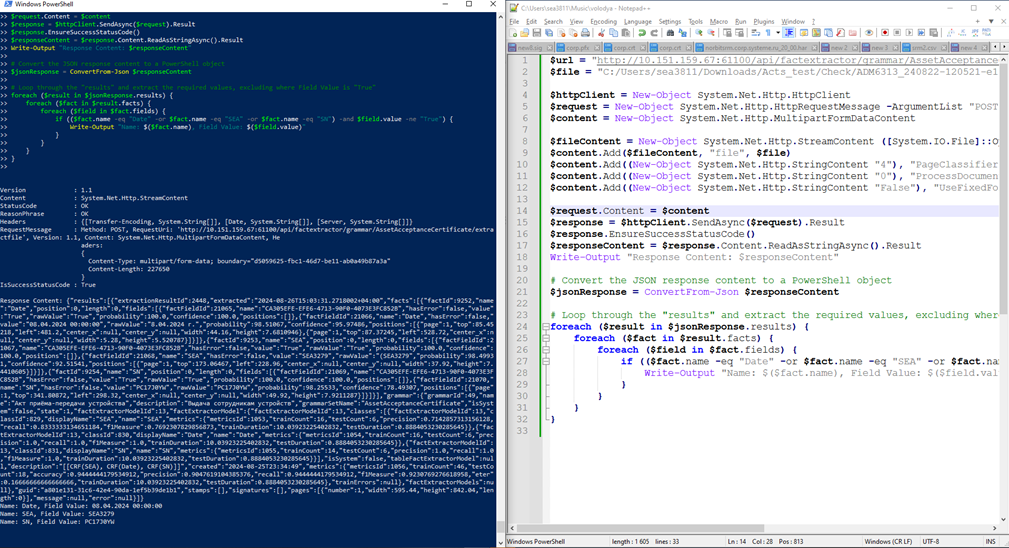
14. Скрипт для массового распознавания:
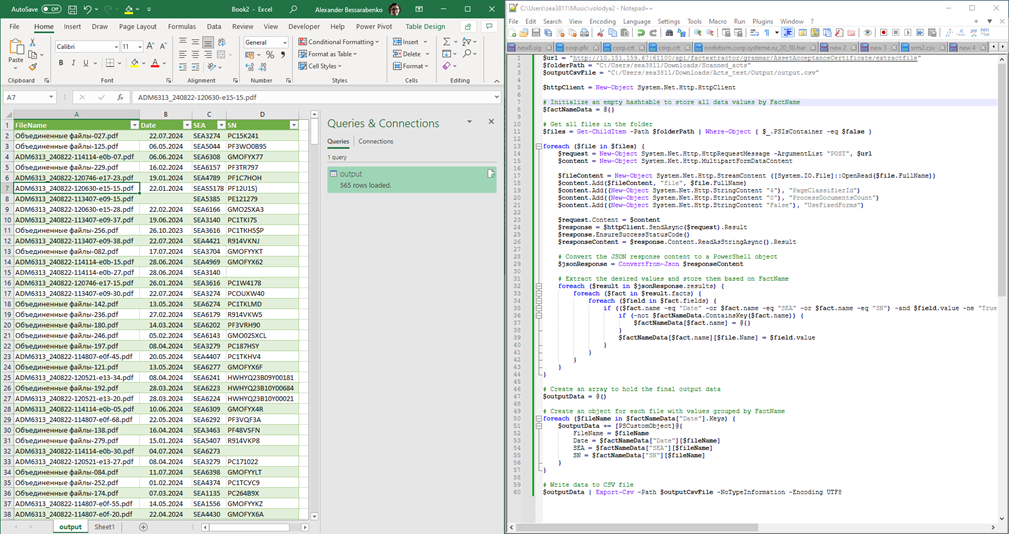
15. Проверка уровня обучения модели:
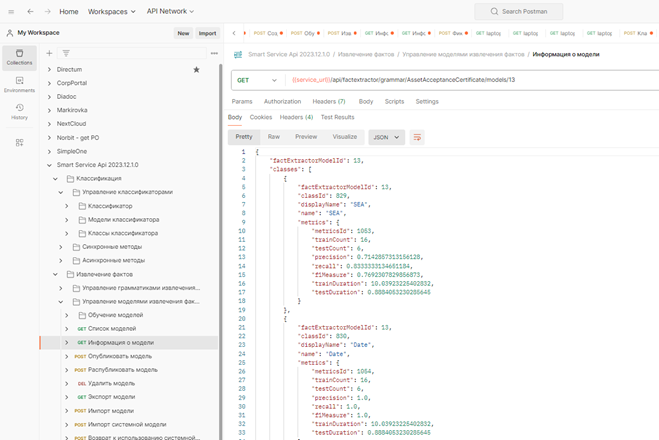
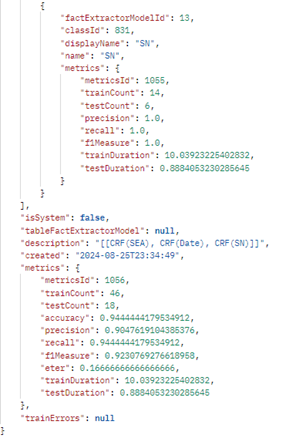
При обучении модели около 10-15% слов откладывается и используется для тестирования модели.
f1Measure - гармоническое среднее между метриками precision (точность) и recall (полнота).
probability - вероятность факта, confidence - уверенность в распознавании текста
При наличии составных атрибутов метрика ETER (Entity Tree Error Rate) может использоваться для сравнения нескольких моделей. Чем меньше значение данной метрики, тем лучше модель работает с составными фактами.
Итоги
Возможно было провести дообучение модели для увеличения уровня распознавания фактов, однако текущее качество устроило бизнес-заказчика. Проект по распознаванию Актов приёма-передачи был успешно реализован и показал высокую эффективность.
Технология распознавания документов значительно упростила процесс инвентаризации, сократив время на ввод в 3-5 раз. Это позволило сотрудникам сосредоточиться на более важных задачах, повысив общую производительность и качество работы.
Учитывая изменение требований посередине, на весь процесс "от и до" ушло 3 дня.
Все вышеперечисленные настройки были произведены без использования студии разработчика.
Номинации:
распознавание
Directum RX
Ario (Арио)
Интеллектуальная система (Intelligence)
искусственный интеллект
No-code
1
Опубликовано:
19 февраля в 09:48
Авторизуйтесь, чтобы написать комментарий
У вас похожая задача?
Обсудите реализацию с экспертом Directum
Комментарии (1)
Отличная заявка! Рады видеть такие кейсы на конкурсе!