Кейс ex-Росбанка по применению ИИ для обработки финансовой отчетности клиентов
120 000
документов в месяц проходят интеллектуальную обработку
~10 FTE
достигнутая экономия
~30 FTE
ожидаемой ежегодная экономия
89%
точность определения классов для баланса и отчета о прибылях и убытках с помощью ИИ
Автор заявки

Исполнитель
Росбанк запустил новую функцию разбора входящих пакетов документов корпоративных клиентов, распознавания отчетностей и импорта данных.
Бизнес-контекст
На всех этапах работы с сегментом корпоративных клиентов – от онбординга нового клиента до закрытия исполненного договора Банк опирается в том числе на данные предоставляемые самими клиентами через различные каналы – ИКБ, электронная почта и даже бумажные носители.
Перечень документов, содержащих такие данные определяется как условиями продуктов, так и регулятором и может быть весьма ощутим, но как минимум включает бухгалтерскую отчетность с приложениями к ней.
При большом количестве клиентов обработка входящего потока с соблюдением SLA и одновременным сохранением для клиента гибкости по форме/составу пакетов требует отвлечения существенных человеческих ресурсов. Упорядочивание хаоса и превращение сырых данных в структурированные и несущие ценность – чистый кост для Банка и, в ручной реализации - одновременно барьер для дальнейшей автоматизации. Нет подготовки данных – невозможно выстроить data-driven пайплайны принятия решений с приемлемой масштабируемостью.
Постановка задачи
В исходном состоянии в работе с документами участвовало до 5 сторон, осуществлявших 40+ технических действий в разных процессах. Некоторые действия могли дублироваться между этапами разными пользователями и что хуже того, количество касаний клиента отличалось от оптимального.
Весь набор действий тем не менее укладывался в единую целевую трубу «подготовить данные за один проход»:
- Разобрать входящий пакет по видам
- Извлечь метаданные и направить файлы в соответствующие места хранения в библиотеке
- Определить документы с извлекаемыми данными
- Извлечь данные и загрузить в банковские системы в структурированном виде.
Основой такого сервиса виделся инструмент чтения содержимого документа.
Таким образом обрисовались базовые требования к решению:
- Чтение документов разных форматов: pdf, tiff, word и т.д.
- Чтение документов разных по качеству – сканы могут быть повернутые, с водяными знаками / печатями, отличатся по резкости, уровню шумов и т.п.
- Чтение структурированных (отчетность) так и не структурированных (свободной формы, т.е. различных по формату справок / писем, расшифровки)
- Качество извлечения, позволяющее оставить на ручной разбор не более 20% потока
- Решение должно держать пиковые нагрузки и одновременно обеспечивать приемлемый отклик
- И критичное: решение возможно разместить в контуре Банка, передача клиентских данных наружу невозможна.
Росбанк имеет опыт использования интеллектуальных инструментов для автоматизации процессов. На базе инструментов Ario были запущены сервисы для внешнеторговых клиентов и автоматическая обработка запросов от ФНС и подготовку справки о подтверждающих документах (СПД) и другие.
Т.к. решение уже было установлено внутри Банка и связано с некоторыми сервисами, первичная интеграция, проверка гипотезы и выход на пилот – виделись возможными в короткие сроки, что и предопределило стартовую систему для теста.
Описание проекта
Проект в целом представляет из себя инициативу автоматизации корпоративного кредитования всех клиентских субсегментов на всех этапах: предварительный скрининг, подготовка заявок на комитет, последующий мониторинг выполнения условий по принятым решениям и фокусируется на минимизацию/исключение участия сотрудника в подготовке данных и последующих шаблонных процессах на них основанных. Чем ниже по сегментной пирамиде – тем ниже tolerance к допустимому % ручной обработки.
В части непосредственно извлечения данных из док-тов проект опирается на сервисы Directum Ario, API Ario и буфер предварительной обработки.
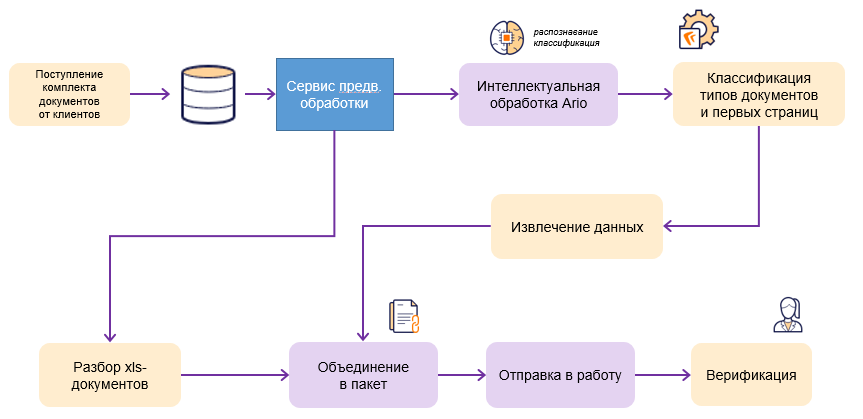
Порядок работы сервиса
Документы различными каналами поступают от клиентов (основной поток), с возможностью загрузки пользователями. Реализован буфер предобработки, который:
- отсекает файлы технических форматов (xml, архивы, подписи и т.п.), для которых настроены отдельные бизнес- правила
- с превышением некоторых порогов по весу / размеру (текущий лимит в pdf – 80 страниц), такие сразу уходят в ручной разбор, поскольку выяснилось, что время отклика по ним превышает допустимые пределы
- выделяет в отдельный поток xls/xlsx, для которых настроен отдельный парсер
- остальные документы передаются далее в Арио.
Характеристика входящего потока – ~54% excel-форматов, 35% pdf и далее сильная фрагментация по типам.
Сервисом Арио обрабатываются таким образом файлы по-своему white list’у: doc, pdf, jpg и другие форматы, преимущественно сканы.
Внутри: Классификатор первых страниц (КПС) осуществляет разметку длинных файлов на отдельные документы по поиску шапок соответствующих началу нового вида док-та (на текущий момент это 29 различных форм)
Классификатор типов получившиеся отдельные части определяет на 21 класс документов, в том числе все формы отчетности.
Через настроенные пары класс-грамматика происходит извлечение данных согласно сделанной разметке.
Верификация происходит на стороне банковской системы. С хранением скорректированных значений по полям.
Сервис работает в асинхронном режиме, в двух сущностях – онлайн поток обрабатывается непосредственно по получении файла. Все неудачно обработанные, ошибочные, сохраняются в очереди и вместе с накопленными историческими документами идут в разбор отдельно и по расписанию в часы наименьшей загрузки (ночные окна).
Этапы проекта
Поступление документов юридических лиц носит волноообразный характер, обусловленный датами окончания отчетных периодов (=появление новых данных клиентов доступных для Банка) и одновременно с этим регуляторным ограничением по срокам обязательной обработки этой новой информации на стороне Банка. Это выливается в 4 характерных пика каждый длиною в месяц, которые и обусловили основных этапы в развитии проекта.
Начальный этап (ноябрь 23 – конец 2023). Сделали первичную разметку 2 форм отчетности прим. по 200 документов каждого типа, настроили соотв. образом классификатор. Прогнали тестовым образом документы 3 кв. 2023его. Первые результаты оказались достаточными для продолжения работ.
Первый пайплайн (январь – апрель24). Дообучали модели извлечения (грамматики) добавляя количество и разнообразие документов, но все те же 2х форм отчетности. Построение интеграции с системами банка (ИКБ, хранилище, система обработки отчетности). Получилась первая версия сквозного решения.
Первый тест на живом потоке (апрель) – первая волна по новому пайплайну. Решение работало в режиме parallel-run в виде доступной, но не обязательной к использованию опции. Поняли, что несмотря на обучение, одна форма (точнее внешний вид) вышел де-факто не читаемый на приемлемом уровне надёжности. Углубили типизацию в КПС и выделили такую отчетность в отдельный класс, отложив решение. Добавили несколько второстепенных типов (нал. Декларации). На данном этапе работал только импорт данных отчетностей без перекладок файлов по хранилищу.
Попытка в hotfix (май). Все еще низкий процент (50-60%) по ключевым классам (баланс и отчет о прибылях и убытках), теперь по причине двух видов одного и того же. Классификатор путался (в т.ч. с налоговыми декларациями), стабильно определяя класс верно, но выбивая уверенность в определении ниже установленного threshold’a в 75%. (на уровне 60-70%). Поняли, что нужно охватывать всю совокупность.
К августу – много работ по обучению КПС и классификатора на большом количестве документов (основные типы – подняли до 1 тыс.), дополнили карту классов до покрытия состава пакетов близкому к полному. % определения класса поднялся до на тестовых сэмплах до 95%. На живом потоке очередной волны результаты тоже оказались уверенно выше 80%.
К ноябрю т.к. результаты августа оказались приемлемыми – то было принято решение обязательно переключить на этот пайплайн все каналы, сделал его основным. Внедрили автораскладку по библиотеке на основе содержимого. Еще более детализировали КПС и классификатор, доведя количество «шапок» до 27. Продолжили дообучать грамматики, доведя количество размеченных док-тов в основных классах так же до 1к)
Пилот (ноябрь) – в эту волну сервис первый раз работал уже как главный канал обработки плюс были реализованы основные компоненты (классификация, чтение, раскладка, импорт) в каких-то своих версиях. Ввиду особенностей календаря получилась концентрация по времени предоставления, сервис испытал следующие пики по таймфреймам (макс/период): сек – 103; мин – 626; час – 5 428; день – 25 288. Поняли, что начинаем забивать поток обработки, нащупав потолок развернутой инфраструктуры (порядка 1тыс в час уверенной обработки). Но результаты оказались многообещающими, был получен ощутимо позитивный пользовательский отклик (документы разложены, легко доступны + импорт в пару кликов).
Получен зеленый свет на дальнейшее развитие => добрали ресурса в команду разработки сервисов на замену последующих по процессу этапов на основе достигнутого чтения
Особенности и сложности проекта
На старте проекта, особенно в фазе proof-of-concept и связанной с ней стесненностью по ресурсам потребовались заметные затраты времени на выполнение разметки в базовых классах. Отсутствие built-in предобученных моделей на основные формы отчетности обусловило более медленный старт. Собственно рутинное дообучение моделей – до сих пор самый ощутимый апсайд по %.
Так как задачей проекта является работа с уже существующим процессом, где сильна фрагментация по сегментам клиентов / используемым продуктам / степени гибкости требований к клиентам - перечень документов равно как их форматы могут варьироваться самым существенным образом. Поэтому кластеризация входящего потока с последующим обучением вылилась в достаточно трудоемкий процесс.
Нет петли на авто-обучение / корректировку разметки выполненной ИИ. Сделали накопитель исправлений, внесенных пользователями и с некоторой периодичностью дообучаем модели ручной поставкой размеченных документов. Отсутствие такой петли замедлило темп роста % классификации/ распознавания, т.к. опять требовало человеческого ресурса команды внедрения.
Так как изначально целились в полностью автоматическую раскладку входящего пакета, то цена ошибки в false-positive (класс определен, но неверно) исходе классификации казалась выше ошибки в false-negative (не определен). Это привело к достаточно долгой битве за % уверенности в классификации при высоком мин. пороге определения. На этом этапе выявили зависимость успешности классификатора от нарезки входящего документа – чем на более мелкие куски нарезан весь файл, тем точнее классифицируется каждая часть. Это привело к пониманию необходимости
- 1) выделить в КПС практически все подтипы шапок для, казалось бы, одинаковых по содержанию классов
- 2) разметить даже «мусорные» классы документов, работа с которыми предполагалась в каком-то дальнем бэклоге, с тем чтобы «отрезать» их от более ценных документов, повышая % успеха работы с последними.
На момент данной заявки это привело к 29 видам в КПС с примерно по 1тыс на каждую тип в классификаторе.
Решение «из коробки» потребовало защиты «от дурака». Предварительно никак не отфильтрованный и не сортированный поток, поступающий от клиентов может содержать разного рода файлы, такие как очень длинные или многостраничные эксели, pdf на 100+ страниц (был пример на 1800) которые 1) являются статистическими выбросами 2) провоцируют время ответа сервиса за гранью SLA, да и добра и зла тоже.
Отсутствие встроенного менеджера очередей приводило к сложности избирательного исключения таких файлов из потока обработки. А также невозможности хранения этой самой очереди на случай падения сервисов, равно как и управления приоритезацией тасков внутри потока. Для решение этой проблемы добавили буфер до Арио, который фильтрует и разделяет потоки файлов по расширениям плюс имеет свою встроенную очередь.
Для эффективного же управления нагрузкой между потоками (актуально в какое-то количество дней пиковой загрузки) от разных систем-пользователей потребовалось физическое выделение отдельных instance Арио на разные потоки, т.е. де-факто такое управление оказалось недоступно при нахождении в одном контуре.
Результаты
Метрики по первому пилотному периоду были приняты как достаточные для дальнейшего развития сервиса и построения сквозных пайплайнов по отдельным этапам кредитного процесса с минимальным участием пользователя.
Основные выводы с первого этапа:
- Построили единый пайплайн и полностью исключили sales-офис из ежеквартального регуляторного документооборота и практически полностью – из заявочного. Покрытие сервисом по последней волне - 90% действующих клиентов.
- По последней волне пропустили более 120к документов в разбор за месяц, с пиком в ~25к / день.
- За счет авто-запросов в интерфейс клиентов в ИКБ – сдвинули сроки предоставления док-тов влево на 3-5 дней, что увеличило период доступный для работы подразделения мониторинга на 1/3, выравнивая нагрузку и фактически увеличивая capacity на аналогичную величину без добавления FTE.
- Точность определения классов для баланса и отчета о прибылях и убытках достигла 89%. Импорт успешно прочитанного документа в системы банка для пользователя – пара кликов вместо 30+минут ручной обработки.
- Достигнутая реализация на текущей клиентской базе высвободила суммарно ~10 FTE из разных подразделений, в т.ч. половина из этой экономии – полностью освобожденное от документооборота клиентское подразделение
Достигнутые цифры являются уверенным фундаментом для дальнейшей автоматизации. На горизонте года мы планируем достроить ряд пайплайнов, использующих достижения первого этапа с ожидаемой ежегодной экономией ~30 FTE на текущей клиентской базе.
При переходе к целевой конфигурации мы планируем гораздо легче масштабироваться вниз сегментной пирамиды, обеспечивая непропорционально отстающий рост затрат в обслуживающих подразделениях относительно sales-офиса, снижая таким образом удельный кост стоимости сервиса и удерживая unit-экономику в низких чеках.
По прямым, но неденежным эффектам аналогично ожидаем апсайды по таким направлениям как:
- рост NPS за счет повышения прозрачности, снижения кол-ва клиентских касаний (особенно повторных), сокращения time-to-yes и time-to-money
- выравнивание качества и сопоставимости данных максимальным исключением сотрудников из их подготовки
- повышение скорости реагирования на новые данные для всех процессов, завязанных на эти цифры (различное рейтинги, регуляторные требования и т.п, отслеживание выполнения условий).
«Это очень хороший шаг, который позволяет дальше тестировать и использовать ИИ-сервисы Directum Ario на этой задачи и экспериментировать с другими процессами» — отметил Владислав Рыбка, стейкхолдер проекта.
Уникальность проекта
Что вы считаете особенно уникальным в идее/проекте?
Решение Арио было дополнено буфером предобработки, позволившим адаптировать инструмент под особенности проекта, повысив эффективность и отказоустойчивость сервиса в составе пайплайна.
Почему эту практику оставили даже после слияния с Т-Банком?
Сегменты, в которых до объединения работали Т-банк и Росбанк скорее комплиментарны друг другу, чем являются пересекающимися. Поэтому выработанное на контуре Р решение продолжает использоваться для своего клиентского стрима. Границы применения пайплайна в рамках общей клиентской базы в процессе исследования.
Почему инновация может быть интересна другим компаниям?
Процессы, классически определяемые как подходящие для автоматизации (сходные и повторяемые действия) в избытке встречаются в любой компании. Превращение сырых данных в структурированные и возможные к использованию – это одновременно и затратная часть для всех игроков, и сходное по основным шагам действие, кастомизируемое под типологию первичных документов при сохранении общей логики процесса.
Команда проекта
- Владислав Рыбка - заказчик, стейкхолдер проекта.
- Игорь Гипич - архитектор команды RPA, руководитель проекта по интеграции ИИ Арио.
- 2 разработчика
Номинация:
Лучший интеллектуальный проект
Оптимизация
Directum RX
Данные
бизнес-процессы
Входящие документы
импорт документов
банки
Контрагенты
Ario (Арио)
Интеллектуальная система (Intelligence)
отчетность
искусственный интеллект
интеллектуальная обработка
классификация
дообучение
экономия
2
Поделиться материалом:
Опубликовано:
27 марта 2025 в 12:49
Пока комментариев нет.
Авторизуйтесь, чтобы написать комментарий
У вас похожая задача?
Обсудите реализацию с экспертом Directum

Хотите внедрить
похожее решение?
Оставьте заявку, и мы свяжемся с вами — определим ваши интересы и подготовим индивидуальную презентацию под ваши задачи.
Получить презентацию