"Все лгут"... или решение нетривиального инцидента.
В службу поддержки компании DIRECTUM регулярно поступают обращения как от пользователй системы, так и администраторов и разработчиков. Часть из них закрываются сходу и являются типовыми. Часть более сложны и требуют большего времени для анализа, но также закрываются в приемлемое время. Меньшая же часть – инциденты, которые по сути являются нетривиальными и могут находиться в анализе значительное время.
Пример такого инцидента будет описан далее в этой статье.

«За приступами интересно наблюдать, а не диагностировать их»
В ходе мониторинга состояния сервера СУБД одного из наших клиентов было выявлено повышение нагрузки на процессорную систему сервера. Нагрузка повышалась в произвольные дни в среднем на несколько часов в 1.5-2 раза от среднедневной. В среднем это происходило 1 раз в 1-2 недели, но с завидной регулярностью.
Первоначальный анализ счетчиков производительности, в частности таких показателей как BatchRequests/sec и Compilations/sec (как правило для каждой инсталляции системы DIRECTUM отношение числа батчей к числу компиляций является величиной постоянной), выявил изменение характера нагрузки на SQL.
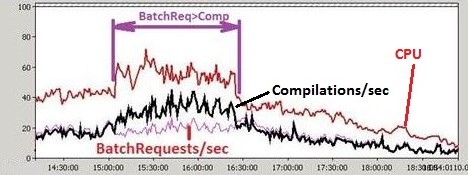
При этом число компиляций увеличивалось в проблемные моменты также в 1.5-2 раза. Исходя из этого можно было сделать предположение, что в эти моменты значительно изменялся профиль нагрузки.
«Мы что-то упускаем»
В качестве дальнейших шагов необходимо было проанализировать, что и как могло достаточно серьезно повлиять на профиль нагрузки системы. Для анализа определили, что необходимо проанализировать логи клиентских частей и сервисных служб, логи клиентского профайлинга и SQL-трассы.
Тут стоит сделать следующее уточнение, что у данного клиента в системе работает достаточно большое число пользователей и весь анализ выполнялся автоматизированными средствами, т.к. анализировать десятки гигабайт SQL-трасс и логов клиентского профайлинга вручную достаточно сложно, если не сказать невозможно.
Также основная проблема заключалась в том, как было упомянуто выше, что инцидент мог возникнуть один раз в одну-две недели, что приводило к необходимости выполнять запись минимально необходимого числа счетчиков и событий в системе, т.к. в ином случае запись максимально возможного объема данных могла оказать значительную нагрузку на оборудование.
Были записаны и проанализированы десятки гигабайт SQL-трасс, логов системы и логов клиентского профайлинга. Данные сравнивались за проблемный день и день без инцидента, данные сопоставлялись и за отдельные часы, но обнаружить сколько-то значительных отличий в нагрузке на СУБД не удавалось. Т.е. по сути все дни и часы ничем не отличались, независимо от того, была ли проблема или ее не было.
Это был тупик…В какой-то момент инцидент от одного инженера был передан другому с целью, чтобы посмотреть на ситуацию свежим взглядом и возможно найти тот нюанс, который привел бы к решению.
«Если ему станет лучше, прав я. Если он умрет — права ты»
Тем не менее, второй инженер также не обнаружил явных признаков проблемы, но в процессе общения были сформированы дальнейшие шаги по анализу:
- проанализировать кэш планов запросов СУБД с целью выявления проблемных запросов, которые приводили к увеличению числа компиляций. Один из вариантов такого анализа подробно описан в статье одного из наших коллег https://club.directum.ru/post/820;
- альтернативный вариант состоял в том, чтобы проанализировать кэш планов запросов, не вдаваясь в детали.
С учетом того, что первое направление требовало значительных трудозатрат и не гарантировало точного результата, решено было начать со второго. Были настроены соответствующие счетчики ОС, благодаря которым удалось выявить следующее:
в моменты увеличения числа компиляций над батчами и даже ранее, в кэше планов запросов значительно падает число кэшированных планов, в т.ч. и те которые используются в текущий момент (в то время как в обычные дни число планов в кэше примерно постоянно).
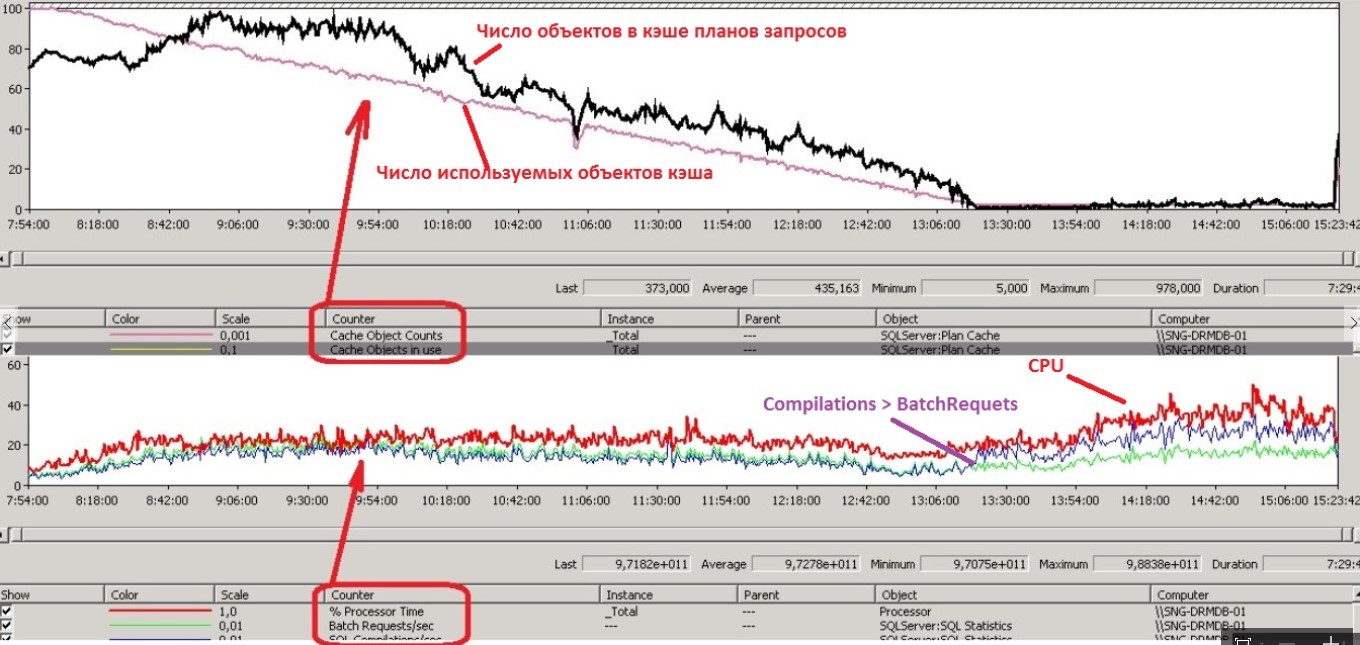
Это в свою очередь могло означать, что объем памяти под этот кэш мог уменьшиться по тем или иным причинам, т.к. объем регулируется СУБД автоматически. Каково же было удивление, когда обнаружилось, что объем остается постоянным.
Следующий шаг был логичным: анализ содержимого кэша, тем более, что объектов в момент проблем было в сотни и тысячи раз меньше, чем в обычное время.
Д-р Уилсон (Хаусу): «Знаешь, у некоторых врачей есть комплекс мессии — им необходимо спасать мир. А у тебя комплекс Рубика — тебе необходимо решать головоломки»
Анализ привел нас к проблемному запросу, который мог выполняться несколько часов, при этом проблемы как видно из графика выше, могли наблюдаться только в его завершающей стадии. Именно поэтому так долго не удавалось отследить его по SQL-трассам (пока он не завершится, он в них просто не попадал).
Запрос представлял из себя запрос полнотекстового поиска по таблице версий документов SBEDocVer. Кратко, хронику событий на СУБД можно представить следующим образом:

Необходимо было каким-то образом свести к минимуму влияние единичных запросов на продуктивную систему, тем более, что аналогичных беспроблемных запросов в течение дня могло быть несколько десятков и даже сотен (проблемность запроса определялась параметрами поисковой фразы, т.к. SQL-сервер не всегда оптимально разбивает эту фразу на поисковые фрагменты).
В качестве временной меры, был настроен мониторинг проблемных запросов, на основе следующего sql-скрипта:
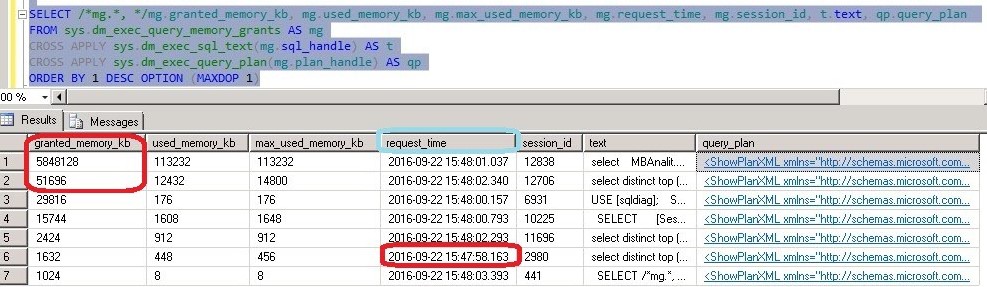
При появлении длительных запросов (например, длительность выполнения которых составляла более часа) с максимальным потреблением памяти, их можно было просто завершать.
С другой стороны, необходимы были меры по полному устранению. Не вдаваясь в детали анализа (статья итак получилась достаточно объемной) были определены следующие шаги:
- Включение опции SQL-сервера «optimize for Ad-hoc workloads», которая позволила сократить число кэшей планов запросов, за счет того, что в кэш помещается план запроса, который должен выполниться как минимум дважды.
- Перенос всех тел версий документов из БД в файловое хранилище.
- Отключение полнотекстового поиска по таблице SBEDocVer (требовалась доработка ПО)
Применение первого пункта позволило значительно сократить частоту возникновения проблем, но полностью не устранила ее. Применение второго пункта полностью устранило проблему и позволило сохранить функциональность полнотекстового поиска по телам документов.
Вместо выводов
Итак, к чему же написана эта статья:
- Поделиться опытом решения нетривиального инцидента, в котором были задействованы как специалисты Заказчика, так и специалисты службы поддержки DIRECTUM.
- Показать, что счетчики показывают текущую ситуацию и могут быть лишь следствием. Первопричина может быть совсем иной («Пять разных врачей ставят пять разных диагнозов на основании одних и тех же доказательств»).
- В СУБД, как и в любом живом организме, все взаимосвязано. Сбои в одной части влекут за собой негативные последствия для всей системы (организма) в целом. Поэтому эту простую истину необходимо учитывать разработчикам системы (в т.ч. прикладным) в особенности в высоконагруженных системах.
P.S.: У многих может возникнуть вопрос, как именно соотносится увеличение загрузки SQL-сервера и решение инцидента службой поддержки DIRECTUM, если инцидента как такового по сути нет, и система продолжает работать «почти» в штатном режиме. Тут хочется уточнить: в рамках расширенной приоритетной поддержки данные ситуации входят в пул решаемых вопросов службой поддержки DIRECTUM (да, есть и такая, и при желании ее можно включить в дополнение к Абонементу). Более детально, что именно предлагается в рамках приоритетной поддержки можно ознакомиться в т.ч. статье "Системный мониторинг: сопровождаем СЭД проактивно"
P.P.S.: С момента выявления проблемы до момента применения всех рекомендаций непосредственно на продуктивной системе прошло порядка ~9 месяцев. С одной стороны, этот срок может показаться слишком длительным, но я думаю у многих возникают ситуации внештатной работы системы и ПО в целом, когда не удается понять причин в принципе, и все списывается на некую «магию». В большинстве же случаев, как показала описанная ситуация выше, «магия» вполне объяснима и требует некоторого внимания к деталям.
И еще один вывод - настройка полнотекстового поиска по файлам в системах с очень большим количеством документов не так уж проста. По моему опыту - файловое хранилище с полнотекстовым поиском создает уж очень большую нагрузку на дисковое хранилище (во время индексирования файлов). Если документы хранятся в БД, то это тоже может привести к повышенной нагрузке при поиске (как мы увидели в этой статье).
Поэтому нужно держать баланс по количеству файлов, которые должны попасть в полнотекстовый каталог, но это уже тема для отдельной статьи :)
Андрей, спасибо, что уделили время на прочтение статьи и собственно комментарий.
Согласен с Вами отчасти: на текущий момент я не сталкивался с ситуациями, когда ресурсы дискового хранилища являются узким местом при индексировании, по крайней мере если речь идет о службе Indexing Service.
Уточните пжл, о какой службе речь в вашем комментарии Indexing Service или Windows Search, а также на каких объемах ФХ это проявилось (еще можно добавить параметры дискового хранилища)
А кто в итоге соврал? я не понял :(
>> Уточните пжл, о какой службе речь в вашем комментарии Indexing Service или Windows Search, а также на каких объемах ФХ это проявилось (еще можно добавить параметры дискового хранилища)
Да, речь идет о Windows Search, в новых версиях Windows Server можно использовать только ее. Объем хранилища действительно большой - около 6 миллионов документов, примерно 700ГБ. В основном это сканы документов в формате PDF с текстовым слоем. На счет хранилища точно не скажу, хранилище мощное (3PAR), но насколько его может использовать ФХ DIRECTUM - неизвестно.
>>Да, речь идет о Windows Search, в новых версиях Windows Server можно использовать только ее. Объем хранилища действительно большой - около 6 миллионов документов, примерно 700ГБ. В основном это сканы документов в формате PDF с текстовым слоем. На счет хранилища точно не скажу, хранилище мощное (3PAR), но насколько его может использовать ФХ DIRECTUM - неизвестно.
Андрей, несколько мыслей:
1. В данном случае высокая нагрузка м.б. вызвана при первоначальном индексировании. В дальнейшем индексирование не должно вызывать значительных проблем.
2. Службу ФХ в данном случае необходимо вынести на отдельный сервер.
3. Далее лучше исключить из индексирования ненужные расширения файлов (оставить только doc и т.д.). К примеру, были проблемы при индексировании сжатых zip архивов, необходимо было накатывать KB.
4. Если используются специализированные iFilter-ы, попробовать использовать фильтры сторонних производителей (в сети есть соответствующие тесты производительности).
>>А кто в итоге соврал? я не понял :(
Статья в процессе написания была частично сокращена для удобства восприятия, возможно поэтому не удалось явно выделить отдельные моменты, и акцентировать на них внимание.
Но в реальности на основании:
"...Первоначальный анализ счетчиков производительности, в частности таких показателей как BatchRequests/sec и Compilations/sec (как правило для каждой инсталляции системы DIRECTUM отношение числа батчей к числу компиляций является величиной постоянной), выявил изменение характера нагрузки на SQL.
При этом число компиляций увеличивалось в проблемные моменты также в 1.5-2 раза. Исходя из этого можно было сделать предположение, что в эти моменты значительно изменялся профиль нагрузки..."
достаточно долго считали, что в системе что-то значительно изменяло характер (профиль) нагрузки. По факту же оказалось, что даже относительно стабильные показатели могут значительно изменяться:
"...счетчики показывают текущую ситуацию и могут быть лишь следствием..."
Согласен с Вами отчасти: на текущий момент я не сталкивался с ситуациями, когда ресурсы дискового хранилища являются узким местом при индексировании, по крайней мере если речь идет о службе Indexing Service.
Уточните пжл, о какой службе речь в вашем комментарии Indexing Service или Windows Search, а также на каких объемах ФХ это проявилось (еще можно добавить параметры дискового хранилища)
Что как бы и не удивительно. Microsoft не рекомендует использовать эти службы в Enterprise окружении. Это предупреждение прописано даже в интерфейсе установки соответвующей компоненты.
Алексей, в тексте упоминается про анализ большого количества информации:
"Тут стоит сделать следующее уточнение, что у данного клиента в системе работает достаточно большое число пользователей и весь анализ выполнялся автоматизированными средствами, т.к. анализировать десятки гигабайт SQL-трасс и логов клиентского профайлинга вручную достаточно сложно, если не сказать невозможно."
Потом сообщается, что это все было проанализировано. При помощи каких инструментов был проведен анализ данных?
>> Потом сообщается, что это все было проанализировано. При помощи каких инструментов был проведен анализ данных?
Айрат, для анализа клиентских логов sbrte использовалась утилита logparser.exe (не путать с одноименной утилитой от компании Microsoft), принцип работы которой описан в статье "Парсим логи DIRECTUM".
Для анализа SQL-трасс использовалась внутренняя утилита, которая повзоляет группировать идентичные запросы в единый вид без конкретных ИД и значений.
Авторизуйтесь, чтобы написать комментарий