Миграция документов и справочников из MS Sharepoint
в 1,5 раза
ускорение процесса согласования документов
63
руководителя подписывают документы электронной подписью (ранее только 5)
444 000
мигрированных документов
10 000
мигрированных контрагентов
40 000
мигрированных персон

Исполнитель

Задачи и цели
Территориальный фонд обязательного медицинского страхования Свердловской области (ТФОМС СО) в прошлом году провел импортозамещение в сжатые сроки (о чем представил зявку на Awards).
На текущем этапе потребовалось пенести данные заказчика из MS Sharepoint в Directum RX.
Описание и возможности решения
Результат - автоматизированный импорт документов и справочников из MS Sharepoint в Directum RX (v.4.3 на момент миграции):
1. Реализован универсальный механизм получения данных списков MS Sharepoint без обращения к REST API, напрямую из БД.
2. Автоматическая генерация SQL запросов для экспорта данных справочников и документов, результаты сохраняются в JSON.
3. Многопоточный экспорт файлов документов и электронных подписей из MS Sharepoint через WEB.
4. Заливка справочников в систему с помощью сервиса интеграции Directum RX.
5. Отдельное решение для Directum RX, которое сводит данные воедино:
- Новый тип документа "Архивный документ", который содержит все необходимые поля для хранения необходимых типов документов из MS Sharepoint.
- Фоновый процесс создания архивных документов из метаданных.
- Фоновый процесс импорта версий в уже созданные документы.
6. Итоговый стек: Python скрипты, JSON для промежуточного хранения, сервис интеграции, фоновые процессы на стороне RX.
Фоновые процессы оптимизированы c учетом домиграции, это облегчило импорт документов по частям (годам).
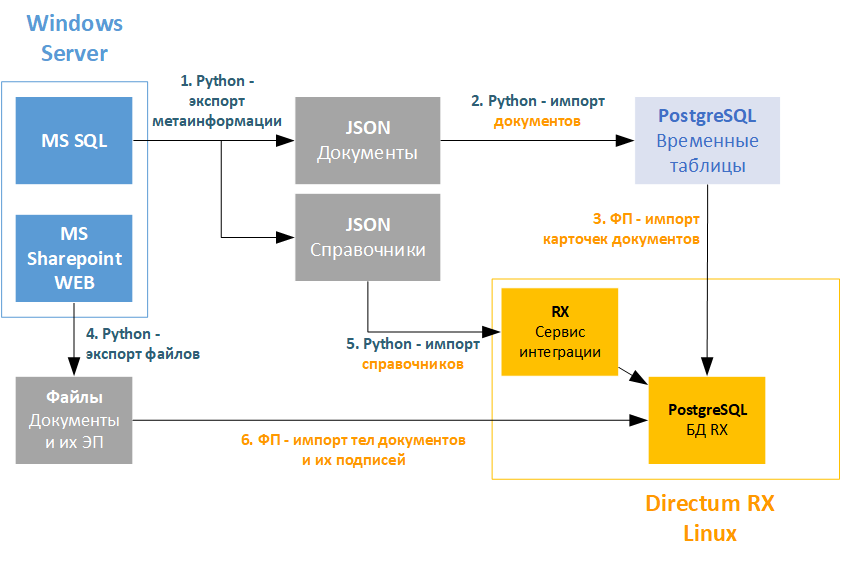
Итоговая архитектура решения
Масштаб и сложность задачи
В процессе разработки миграции были сложности :
- предыдущая система, из которой извлекалась информация, на базе Sharepoint была незнакома, потребовалось время на ее изучение;
- сложность изучения продукта, так как было много избыточной информации, типа «как писать веб-части для Sharepoint», и крайне мало «как извлечь данные из Sharepoint».
- поддержка со стороны разработчиков старой системы отсутствовала.
В итоге сложности преодолели и реализовали масштабную миграцию:
- 444 тысячи документов за период с 2014 по 2022 годы, разбитых на десятки типов и видов.
- 10 тысяч контрагентов и 40 тысяч персон.
- Оргструктура 300 записей.
- Несколько вспомогательных справочников.
Сроки разработки: с апреля по июнь 2022, параллельно с разработкой основного функционала.
Производительность итогового решения
- Экспорт всех метаданных (документы, справочники) из MS Sharepoint отрабатывает за 20 минут.
- Экспорт тел документов требует примерно 4 часа.
- Импорт документов в Directum RX (карточка и тело, с электронными подписями) - средняя скорость импорта - 10 документов в секунду, справочников – до 50 записей в секунду.
Долгая дорога к данным
Начало истории
Краткая история боли и преодоления сложностей в проекте.
Во время предварительной оценки реализуемости проекта была дана положительная оценка: "Я тут посмотрел в интернете, у шарепоинта есть API, всё реализуемо, надо заложить немного больше часов с поправкой на незнакомую систему".
Ситуация осложнялась тем, что поддержка старой системы была уже прекращена, а в нашей команде на момент начала проекта не было компетенций по работе с MS Sharepoint.
Соответственно, идти по традиционному простому пути - "мы выдвигаем спецификации - в каком виде нам нужны данные, а команда поддержки исторической системы их нам выкладывает в нужном виде" - немного не получилось.
Еще усложнение - разные подходы систем к хранению приложений - в MS Sharepoint одна карточка документа и несколько файлов, привязанных к карточке. А в Directum RX одна карточка на один файл и несколько документов - приложений.
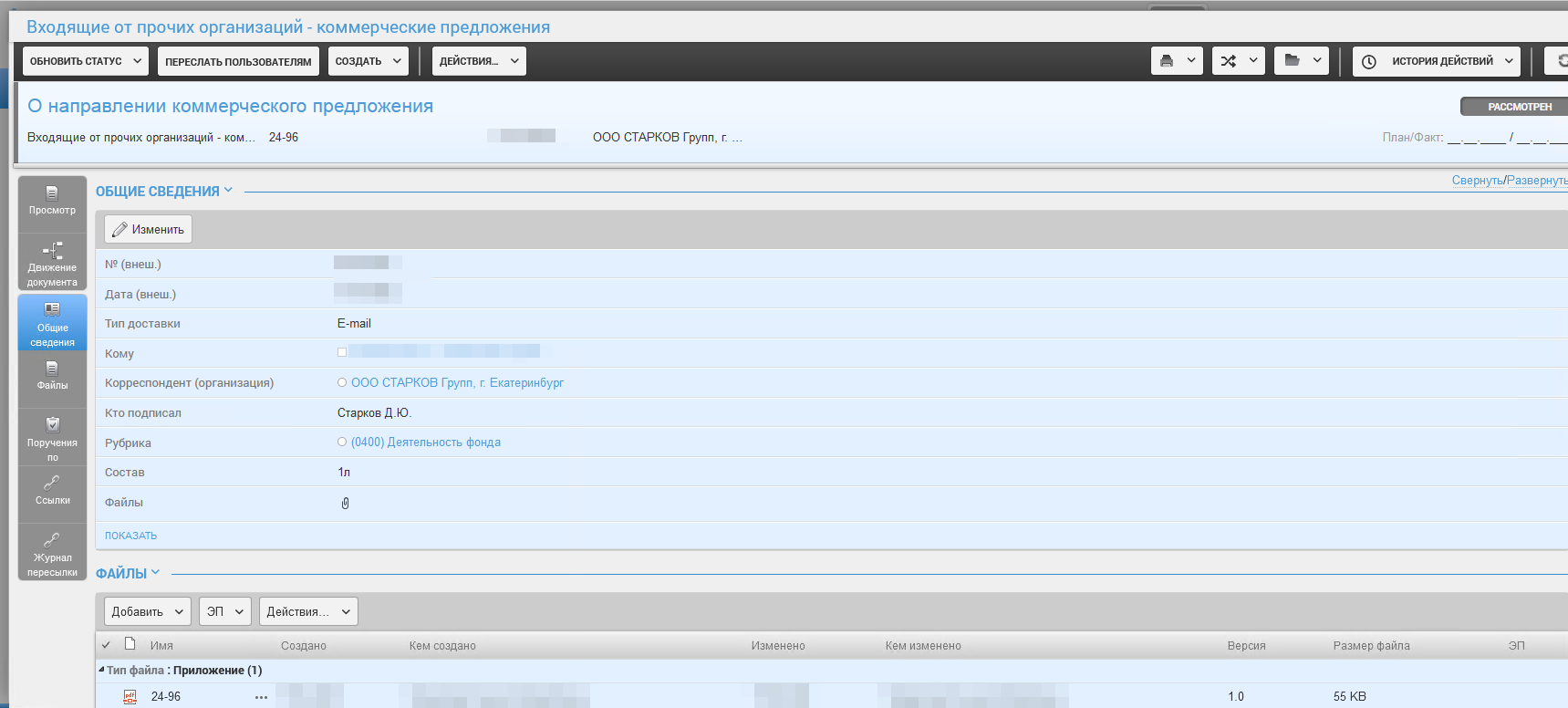
Пример карточки - документ
Варианты реализации
В ходе анализа выяснили, что есть несколько вариантов доступа к данным:
- CSOM (клиентская объектная модель SharePoint)
- REST API (OData) с особенностями реализации проприетарного MS
- JSOM (JavaScript object model)
- SOAP
- Коннектор для Powershell
- Прямой доступ в БД
- Парсинг веб-сайта напрямую.
В рамках проекта пришлось попробовать всё!
Поиски решения
Для целей миграции в локальной сети Заказчика был поднят стенд c доступом к копии данных. Усложнялось всё тем, что сам стенд миграции не обладал доступом в интернет, так что закинуть файл можно было только через буфер обмена по RDP.
Поэтому простые вещи: nuget add, pip install – стали нетривиальными. Это в итоге дало перевес в сторону скриптового решения по части экспорта – скрипты меньше весят и легче править/передавать.
CSOM
Что может быть лучше для .NET разработчика, чем уже готовый пакет, лежащий на Nuget? К сожалению, состыковались проблемы:
- MS Sharepoint 2013 в 2022 году – уже устарел, пришлось дополнительно заниматься археологическими изысканиями.
- Использовалась NTLM авторизация, которую быстро не удалось заставить работать, поэтому (сроки!) на этом варианте поставили крест и были готовы вернуться только в случае, если вариантов совсем не останется.
REST API, JSOM, SOAP
Пробуем привычное решение - Rest API, благо там под капотом вполне себе привычная уже OData (наивный). Форматы вывода - JSON и XML, привычный набор.
Для экспериментов начали со сравнительно маленького списка - контрагенты.
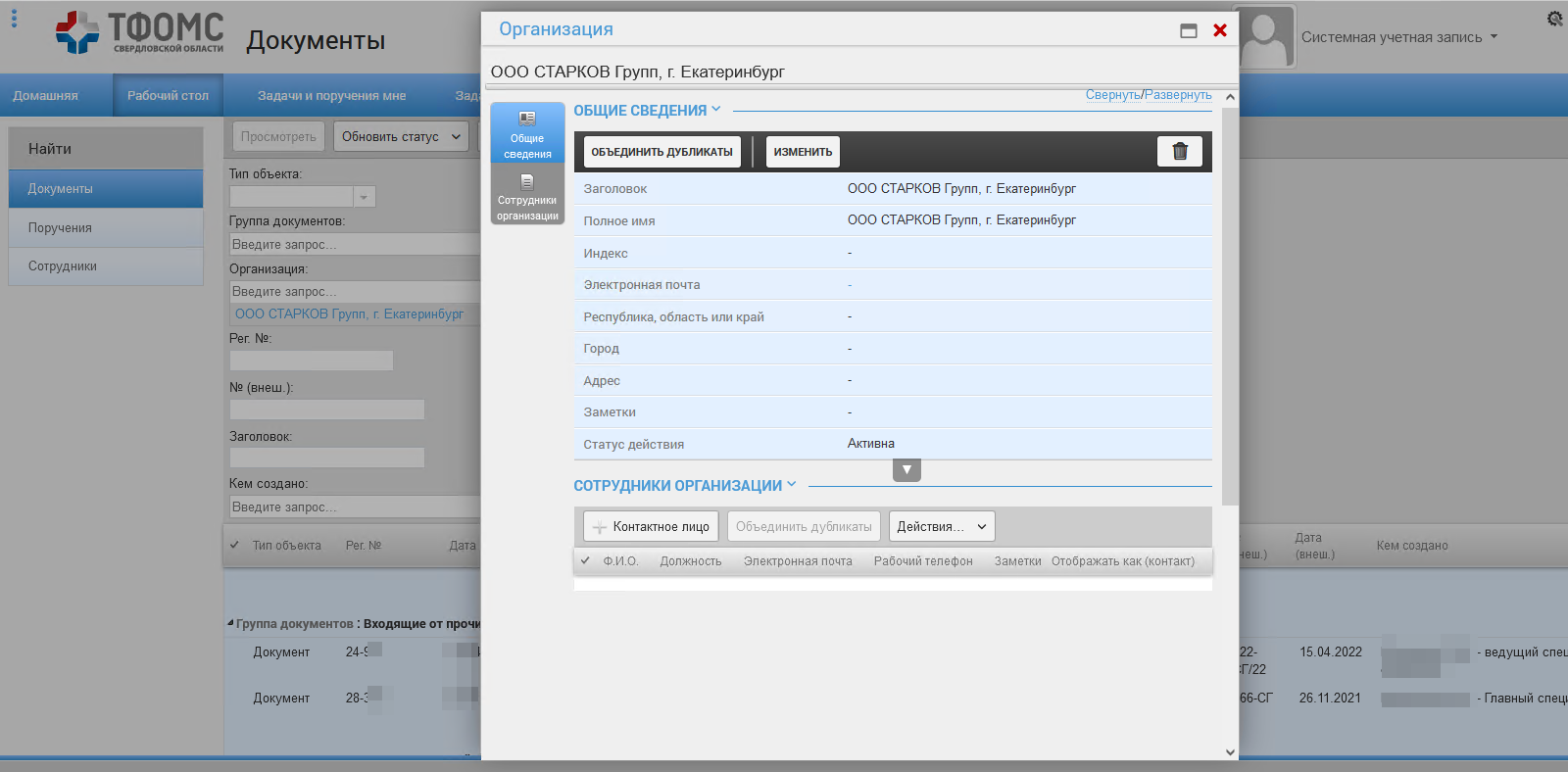
Пример карточки – запись справочника «Контрагенты»
Грабли, старательно разложенные разработчиками MS в реализации OData:
- При выводе длинных списков принудительная постраничность маленькими порциями и слегка невменяемая конструкция запроса для получения каждой следующей страницы.
- Гиперссылка на сайт состоит из объекта с двумя полями и OData не может их сериализовать для вывода. Можно, конечно, запрашивать данные без этих полей, но потом потребуется их извлекать отдельно и дополнять уже импортированные данные.
SOAP вполне успешно справляется с сериализацией сложных типов и успешно выдаёт всё необходимое, но метод доступа не профильный, документации крайне мало и собрать корректный запрос поиска c постраничной навигацией для всех необходимых типов документов было довольно сложно, вариант был помечен как запасной.
Powershell
Единственный инструмент, с которым всё заработало легко - добавили оснастку, и обращаемся к нужным спискам нужных подсайтов.
Что хорошо - в результирующем файле было достаточно информации, чтобы спокойно импортировать те же справочники.

Пример экспортированной записи
Что плохо:
- При экспорте потребовалось добавить стенду экспорта 64 Гб оперативной памяти, потому что оно грузило документы за год в оперативную память, а потом только сохраняло в файл (оптимизация в повершелл? зачем? он же не будет работать с бигдатой!).
- JSON на выходе получился странный - в свойстве JSONа «Xml» лежала XML-ка с большей частью необходимых данных, в кодировке UTF-16. К счастью, на Python в принципе без разницы – что парсить - код получился крайне простой.
- Основная проблема - в выгрузке не хватает ключевых реквизитов, которые были нужны для привязки документа к связанным с ними списками и ЭП, для связи можно дополнить реквизитами из БД, но это получается дополнительная постобработка, уже несколькими методами.
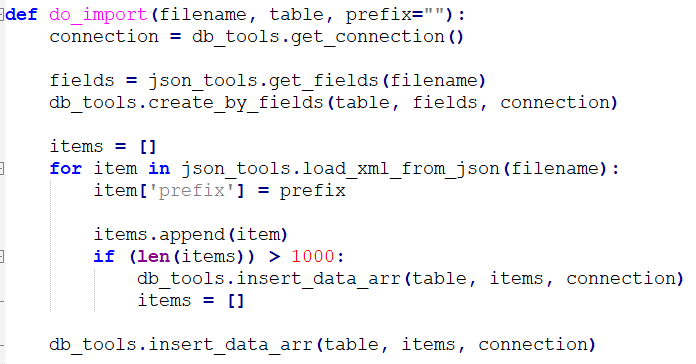
Фрагмент кода импорта из Powershell
В итоге всё намекало, что через БД будет лучше.
Прямой доступ в БД
Если кратко - НЕ РЕКОМЕНДУЕТСЯ всеми, кто что-либо рассказывал об этом (How do I query the Sharepoint database? - Stack Overflow).
На самом деле организация данных в БД довольно логична - есть Site (основная единица), есть Web (подсайт), есть Lists (списки документов в пределах подсайта) и есть Docs (это и документы, и записи справочников в терминологии Sharepoint).
Всё немного усложняется тем, что подсайт создаётся каждый год, внутри него копии списков (документы, задачи).
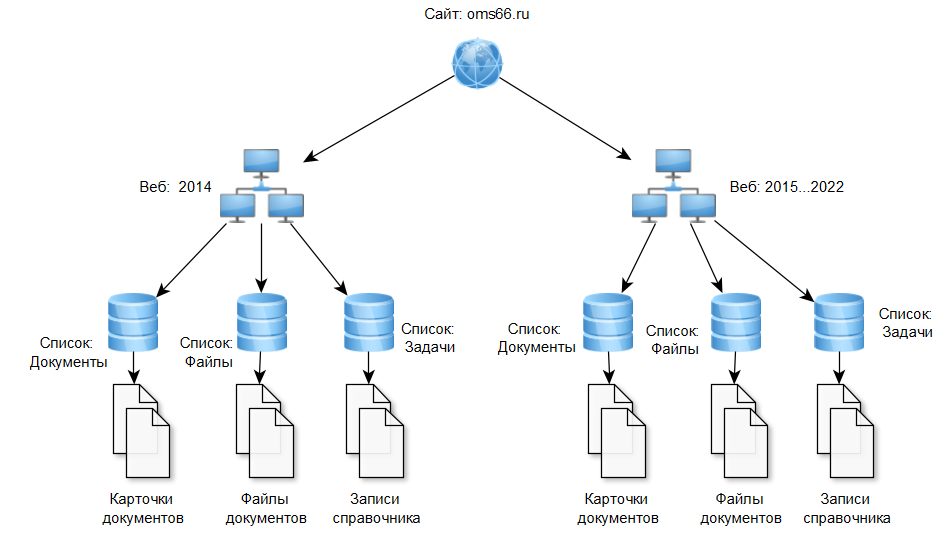
Структура организации данных
БД Sharepoint в MS SQL
Больше всего боли при анализе и импорте данных доставила излишне гибкая таблица в БД, которая хранит в себе ЗАПАСНЫЕ ПОЛЯ НА ВСЕ СЛУЧАИ и ВСЕ ЗНАЧЕНИЯ ПОЛЕЙ ДЛЯ ВСЕХ ДОКУМЕНТОВ И СПРАВОЧНИКОВ, которые используются во всех справочниках и документах (как если бы sungero_content_edoc + все databooks из Directum RX собрали в одной таблице).
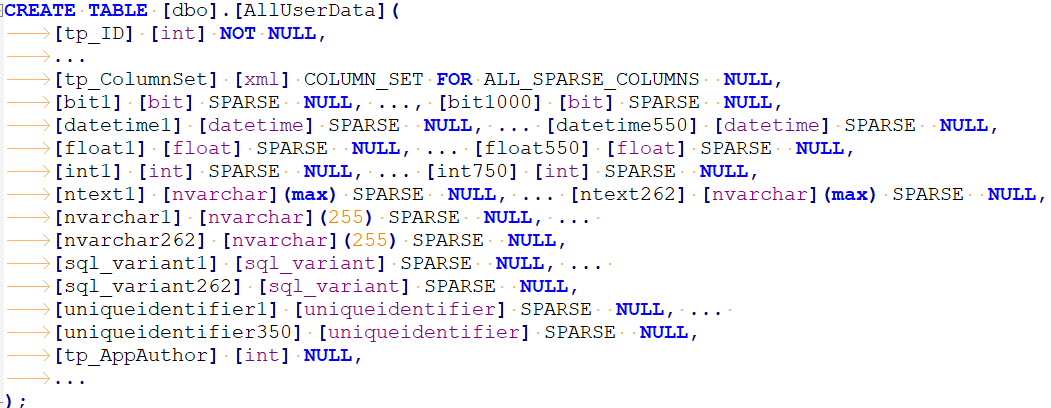
Ключевая таблица, содержащая все данные
То есть - 750 инт полей, 1000 битовых полей и т.д., добавлено разработчиками заранее и никогда не планировало меняться (640 кб памяти хватит всем! (с)).
В результатах запроса это поле выглядит чуть получше.
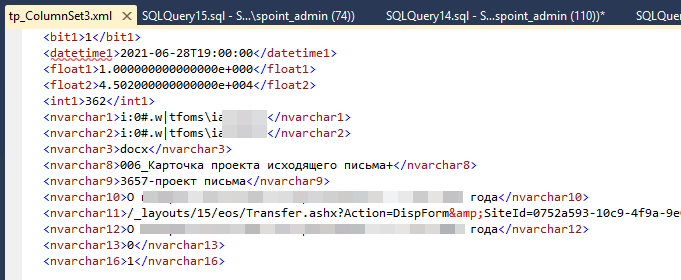
Содержимое столбца tp_ColumnSet для отдельной записи
Но ключевая проблема заключается в том, что для разных копий одного и того же списка в подсайтах для разных лет - одни и те же данные могут храниться в разных столбцах таблицы. То есть для каждого справочника в каждом году требовалось довольно сложным образом анализировать необходимые столбцы для привязки к свойствам документов, чтобы получить запросом все необходимые данные.
Еще проблема – метаданные для списков с маппингом свойств документов на поля БД были закодированы.
Еще одним усложняющим фактором оказалось решение EOS, которое для своего специфичного функционала реализовало параллельную структуру хранения данных во второй БД.
Парсинг веб-сайта напрямую
Еще одной проблемой оказалась странная структура хранения тел документов в БД (особенность Sharepoint), проще оказалось на основе имеющихся данных вычислить для каждого документа HTTP(S) ссылку на актуальную версию, а потом в несколько потоков скачать все файлы документов и положить их в набор каталогов, с именами, которые позволяют удобно привязать каждый файл к нужному документу.
Итоговое решение
- Справочники экспортировались через Powershell в промежуточные файлы JSON и с помощью скрипта на Python и сервиса интеграции были залиты в Directum RX.
- Удалось разобраться с хранением метаинформации в БД, после этого был написан автоматический генератор запросов в БД для экспорта данных напрямую из БД по любой необходимой структуре, включая ссылочные типы, промежуточный контейнер для документов – JSON. (При необходимости достаточно легко можно будет реализовать даже прямую миграцию БД -> БД).
Таким образом были экспортированы метаданные всех документов. - Файлы документов и ЭП были скачаны через веб, в имени файлов - ключевая информация для привязки его к документу и списку.
- JSON файлы с метаданными документов были загружены во временные таблицы в БД на сервере Directum RX, фоновый процесс занимался их импортом в систему.
- Файлы документов в созданные карточки документов импортировались вторым фоновым процессом, процессы работали параллельно, не мешая друг другу.
Финальный результат
ТФОМС Свердловской области уже почти год пользуется Directum RX.
Статья: Directum RX в ТФОМС Свердловской области: импортозамещение в сжатые сроки
Краткое итого
- Переезд другого заказчика с Sharepoint на DirectumRX будет быстрым и счастливым.
- Реализация и работа API может отличаться от маркетинговых обещаний, особенно если требуются нетривиальные кейсы.
- Декомпилятор быстрее отвечает на вопросы, которых нет в документации.
- Знать больше одного языка программирования – резко расширяет возможности и ускоряет процесс.
- Понимать, как работает система в глубине - БЕСЦЕННО!
- СТАРКОВ Групп МОЛОДЦЫ!
 |
Наталья Титкова, первый заместитель директора — заместитель директора по ОМС:
|

Перспективы развития решения
Возможна модификация под импорт данных из любой другой системы, потребуется дописать часть коннектора к сторонней системе.
Проще всего будет адаптировать под другой экземпляр Sharepoint.
Состав команды проекта

 Руководитель проекта – Вера Вафина |
|
 Заместитель руководителя проекта, аналитик – Александр Ершов |
 Разработчик-рецензент Алексей Присяжный |
 Разработчик Анастасия Матушкина |
 Разработчик Константин Бастылев |
Номинации:
6
Поделиться материалом:
Опубликовано:
14 марта 2023 в 11:34
Пока комментариев нет.
Авторизуйтесь, чтобы написать комментарий
У вас похожая задача?
Обсудите реализацию с экспертом Directum

Хотите внедрить
похожее решение?
Оставьте заявку, и мы свяжемся с вами — определим ваши интересы и подготовим индивидуальную презентацию под ваши задачи.
Получить презентацию